

![]()
Büyük veri sistemlerinde veri güvenliğini sağlamak ve veri formatını belirli bir yapıda tutmak, veri akışını yönetmede oldukça önemli bir rol oynar. Apicurio Schema Registry, veri yapısının standartlaşmasını sağlayarak Kafka gibi gerçek zamanlı veri hatlarında ve akış uygulamalarında veri doğruluğunu güvence altına alır. Kafka ise yüksek hacimli veri işlemlerini hızlıca gerçekleştiren bir mesajlaşma altyapısı sunar.
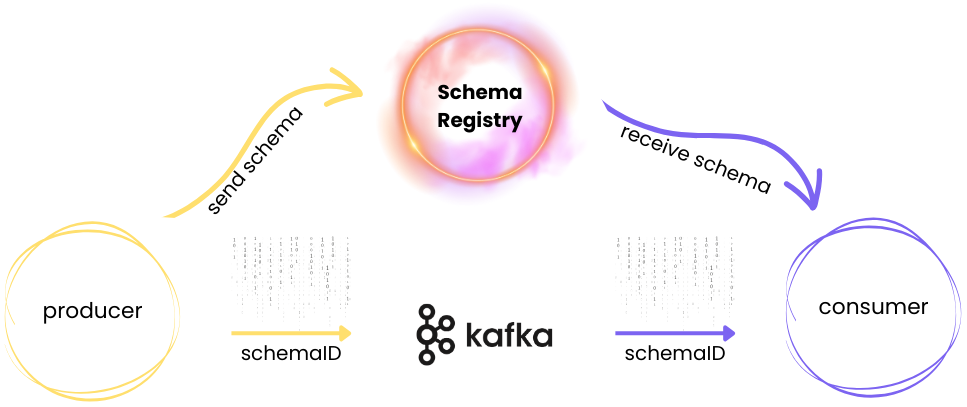
Bu yazıda, Apicurio Registry ile Kafka’nın birlikte nasıl çalıştığını, veri akışını nasıl sağladığımızı ve PostgreSQL gibi bir veritabanında bu verileri nasıl sakladığımızı uygulamalı bir şekilde ele alacağım. Bir Kafka veri akışı kurarak ve Apicurio Schema Registry ile veri şemalarını yöneterek büyük ölçekli veri işlemleri için güvenli ve düzenli bir yapı sağlayacağız. PostgreSQL kullanarak veri tabanı düzenlemesi yapacak, Docker ile ortam kurulumunu tamamlayacağız ve bir müşteri verisi akışı senaryosu oluşturacağız.
Gereksinimler
- Docker kurulu bir bilgisayar ve internet
Proje Ortamının Kurulması
İlk olarak, sanal bir Python ortamı oluşturarak gerekli bağımlılıkları yükleyip kurulum adımlarına başlıyorum. Bu ortam, bağımlılık yönetimini kolaylaştırarak projenin sorunsuz çalışmasını sağlayacak.
1. Sanal Ortam Oluşturulması ve Gereksinimlerin Yüklenmesi
Öncelikle kendimize yeni bir proje dizini ve ortam oluşturalım. Ardından proje için gerekli olan kütüphaneleri yükleyelim.
python3 -m venv schema_project
source schema_project/bin/activate
requirements.txt:
confluent_kafka psycopg2-binary requests avro-python3 pandas sqlmodel
pip install -r requirements.txt
2. Docker Ayarları ve Docker-Compose Yapılandırması
Docker kullanarak PostgreSQL, Kafka ve Apicurio Registry gibi hizmetlerin hepsini tek bir ortamda başlatıyoruz. Bu yapılandırma, farklı hizmetlerin uyum içinde çalışmasını sağlıyor.
Docker başlatalım:
sudo systemctl start docker
Kafka Dockerfile, start-kafka.sh, server.properties
Dockerfile:
Dockerfile, gerekli bağımlılıkları kurarak ve Kafka’yı indirip yapılandırarak Kafka sunucusunu Docker üzerinde çalışmaya hazır hale getirir.
FROM openjdk:17.0.2-jdk-buster
RUN apt update
RUN apt install -y curl
RUN apt install -y python3
RUN apt install -y python3-pip
RUN apt install -y git
RUN apt install -y libpq-dev
ENV KAFKA_VERSION 3.8.0
ENV SCALA_VERSION 2.12
RUN mkdir /tmp/kafka && \
curl "https://downloads.apache.org/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz" \
-o /tmp/kafka/kafka.tgz && \
mkdir /kafka && cd /kafka && \
tar -xvzf /tmp/kafka/kafka.tgz --strip 1
RUN mkdir -p /data/kafka
COPY start-kafka.sh /usr/bin
RUN chmod +x /usr/bin/start-kafka.sh
CMD ["start-kafka.sh"]
start-kafka.sh:
start-kafka.sh Kafka’nın belirtilen cluster-id ile başlatılmasını ve ardından server.properties ayarlarıyla Kafka sunucusunun çalıştırılmasını sağlar.
#!/bin/bash /kafka/bin/kafka-storage.sh format --config /kafka/config/server.properties --cluster-id 'EP6hyiddQNW5FPrAvR9kWw' --ignore-formatted /kafka/bin/kafka-server-start.sh /kafka/config/server.properties
server.properties: Kafka’nın temel yapılandırma dosyasıdır.
############################# Server Basics ############################# process.roles=broker,controller node.id=1 controller.quorum.voters=1@kafka:9093 ############################# Socket Server Settings ############################# listeners=PLAINTEXT://:9091,CONTROLLER://:9093,EXTERNAL://:9092 inter.broker.listener.name=PLAINTEXT advertised.listeners=PLAINTEXT://kafka:9091,EXTERNAL://localhost:9092 controller.listener.names=CONTROLLER listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 ############################# Log Basics ############################# log.dirs=/data/kafka num.partitions=3 num.recovery.threads.per.data.dir=1 ############################# Internal Topic Settings ############################# offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 ############################# Log Retention Policy ############################# log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 ################################ Custom Propertied Added by Erkan ######################### controlled.shutdown.enable=true delete.topic.enable=true
Dosyayı oluşturmak için komut:
touch docker-compose.yaml
Docker Compose oluşturulması
networks:
my_network:
driver: bridge
services:
kafka:
container_name: kafka
image: kafka:3.8.0
build:
context: ./kafka
ports:
- "9092:9092"
networks:
- my_network
volumes:
- ./kafka/config/server.properties:/kafka/config/server.properties
- ./data/kafka/:/data/kafka/
postgresql:
image: 'postgres:15-bullseye'
environment:
POSTGRES_USER: myuser
POSTGRES_PASSWORD: mypassword
POSTGRES_DB: mydatabase
ports:
- '5432:5432'
networks:
- my_network
apicurio-registry-kafkasql:
image: apicurio/apicurio-registry-kafkasql:2.6.5.Final
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka:9091
REGISTRY_FEATURES_GROUPS_ENABLED: "true"
ports:
- "8080:8080"
depends_on:
- kafka
networks:
- my_network
apicurio-registry-ui:
image: apicurio/apicurio-studio-ui:0.2.62.Final-announce
ports:
- "8081:8081"
depends_on:
- apicurio-registry-kafkasql
networks:
- my_networkdocker-compose dosyasındaki her servisin işlevi ve yapılandırmasından aşağıda kısaca açıklamak istiyorum.
Kurulacak Servisler ve Temel İşlevleri
- Kafka:
- Kafka, Apicurio Schema Registry ile veri ve şema yönetimi için bir mesajlaşma platformu olarak çalışır.
- 9092 portu üzerinden dış dünyaya açılır ve my_network isimli özel bir ağda çalışır.
- server.properties dosyasındaki konfigürasyonlar, Kafka’nın yapılandırmasını özelleştirir. Ayrıca, verileri kalıcı hale getirmek için bir volumes ayarına sahiptir.
- PostgreSQL:
- PostgreSQL, verilerin depolanmasını sağlamak için bir ilişkisel veritabanı olarak çalışır.
- 5432 portundan erişilebilir ve varsayılan kullanıcı, parola ve veritabanı bilgileri environment bölümünde belirtilmiştir.
- Apicurio Registry gibi uygulamalara, yapılandırılmış veritabanı üzerinden veri yönetimi sağlar.
- Apicurio Registry (apicurio-registry-kafkasql):
- Apicurio Schema Registry’nin ana bileşenidir ve şemaları Kafka ile yönetmek için kullanılır.
KAFKA_BOOTSTRAP_SERVERSortam değişkeni ile Kafka sunucusuna bağlanır.REGISTRY_FEATURES_GROUPS_ENABLEDayarı ise şema gruplarını etkinleştirir.- 8080 portunda çalışır ve Kafka servisine bağımlıdır, bu yüzden
depends_onifadesi ile Kafka servisi başlatıldıktan sonra aktif hale gelir.
- Apicurio Registry UI (apicurio-registry-ui):
- Apicurio’nun kullanıcı arayüzünü sağlar, kullanıcıların şemaları görsel olarak yönetmesine olanak tanır.
- 8081 portu üzerinden erişilebilirdir.
- apicurio-registry-kafkasql servisine bağlı olarak çalışır ve kullanıcıların şema yönetimi işlemlerini daha kolay bir arayüzle gerçekleştirmesini sağlar.
Özetledocker-compose.yaml yukarıdaki dört servisin bir köprü ağı (bridge network) içinde sorunsuz bir şekilde iletişim kurmasını sağlar.
Konteynerlarımızı başlatalım:
docker-compose up --build -d
Tüm konteynerlerin çalışıp çalışmadığını doğrulamak için docker ps komutunu kullanıyoruz.
(schema_project) (base) [train@trainvm schema_registry]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d13cb6f6ac39 apicurio/apicurio-studio-ui:0.2.62.Final-announce "/usr/local/s2i/run" 27 seconds ago Up 25 seconds 8080/tcp, 8443/tcp, 8778/tcp, 9779/tcp, 0.0.0.0:8081->8081/tcp, :::8081->8081/tcp schema_registry-apicurio-registry-ui-1 6fd76315c36f apicurio/apicurio-registry-kafkasql:2.6.5.Final "/opt/jboss/containe…" 27 seconds ago Up 25 seconds 8443/tcp, 8778/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 9779/tcp schema_registry-apicurio-registry-kafkasql-1 66f478f6b4b5 kafka:3.8.0 "start-kafka.sh" 27 seconds ago Up 26 seconds 0.0.0.0:9092->9092/tcp, :::9092->9092/tcp kafka 54bcb258c159 postgres:15-bullseye "docker-entrypoint.s…" 27 seconds ago Up 26 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp schema_registry-postgresql-1
Schema, Producer ve Consumer Oluşturulması
1. Schema
schema_registration.py dosyası, bir Avro şemasını Apicurio Registry’ye kaydetmeyi sağlar. Böylece belirli bir veri yapısının tanımı Apicurio’da depolanarak veri akışı ve doğrulaması yapılabilir.
Dosyayı oluşturmak için komut:
touch schema_registration.py
Dosya içeriği:
import requests
import json
# Avro Şeması Tanımı
schema = {
"type": "record",
"name": "Customer",
"fields": [
{"name": "RowNumber", "type": "int"},
{"name": "CustomerId", "type": "int"},
{"name": "Surname", "type": "string"},
{"name": "CreditScore", "type": "int"},
{"name": "Geography", "type": "string"},
{"name": "Gender", "type": "string"},
{"name": "Age", "type": "int"},
{"name": "Tenure", "type": "int"},
{"name": "Balance", "type": "float"},
{"name": "NumOfProducts", "type": "int"},
{"name": "HasCrCard", "type": "int"},
{"name": "IsActiveMember", "type": "int"},
{"name": "EstimatedSalary", "type": "float"},
{"name": "Exited", "type": "int"}
]
}
# Şemayı Apicurio Registry'ye kaydet
url = "http://localhost:8080/apis/registry/v2/groups/default/artifacts"
headers = {"Content-Type": "application/json"}
response = requests.post(url, headers=headers, data=json.dumps(schema))
if response.status_code == 200 or response.status_code == 201:
print("Şema başarıyla kaydedildi.")
else:
print("Şema kaydedilemedi:", response.status_code, response.text)
Çalıştırmak için:
python schema_registration.py
Beklenen sonuç:
'Şema başarıyla kaydedildi.'
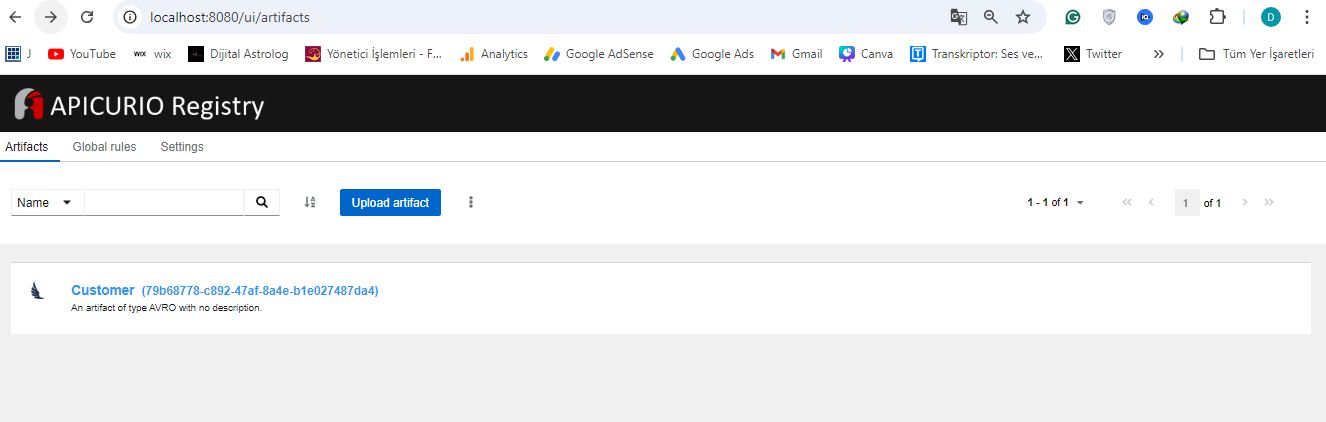
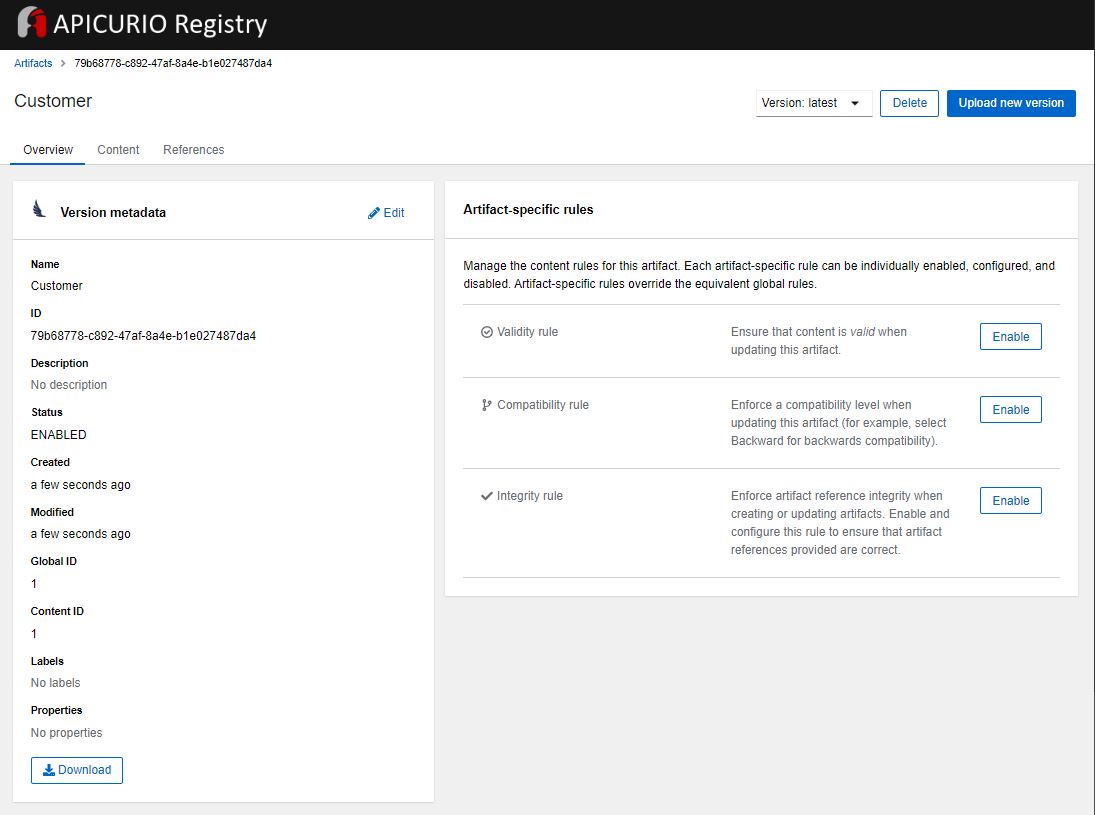
Ardından http://localhost:8080/ adresine giderek oluşan şemayı görebilirsiniz. Producer ve Consumer içinde ihtiyacımız olacak schema id’sini bu arayüzden görüyoruz.
2. Python Producer
producer.py Apicurio Registry’de kayıtlı Customer adlı Avro şemasını kullanarak, Churn_Modelling.csv veri setindeki müşteri bilgilerini churn-topic adlı Kafka konusuna Avro formatında gönderir. Veriler iki saniyelik aralıklarla Kafka’ya gönderilir.
Dosyayı oluşturmak için komut:
touch producer.py
Dosya içeriği:
import requests
import pandas as pd
from confluent_kafka import Producer
from avro.schema import Parse
from avro.io import DatumWriter, BinaryEncoder
from io import BytesIO
import json
import time
# Apicurio Registry ve Kafka bağlantı ayarları
REGISTRY_URL = 'http://localhost:8080/apis/registry/v2/groups/default/artifacts/33e4eff9-b9d6-47f4-9814-c1383d043625'
"""Şema id REGISTRY_URL'nin sonuna yazılacak! örn: 33e4eff9-b9d6-47f4-9814-c1383d043625"""
KAFKA_BOOTSTRAP_SERVERS = 'localhost:9092'
producer_config = {
'bootstrap.servers': KAFKA_BOOTSTRAP_SERVERS,
'client.id': 'my-producer',
'linger.ms': 10,
'acks': 'all'
}
# Producer'ı oluşturma
producer = Producer(producer_config)
# Veri setini yükleme
df = pd.read_csv("https://raw.githubusercontent.com/erkansirin78/datasets/refs/heads/master/Churn_Modelling.csv")
# Apicurio Registry'den şema alma
response = requests.get(REGISTRY_URL)
if response.status_code == 200:
schema_content = response.json()
if schema_content:
print("Şema başarıyla alındı.")
schema = Parse(json.dumps(schema_content)) # JSON string'e dönüştürdük
else:
print("Şema içeriği bulunamadı. Yanıt:", response.json())
exit(1)
else:
print(f"Şema alınamadı: {response.status_code}, {response.text}")
exit(1)
# Veriyi Avro formatında Kafka’ya hazırlayan fonksiyon
def send_avro_message(row):
writer = DatumWriter(schema)
bytes_writer = BytesIO()
encoder = BinaryEncoder(bytes_writer)
writer.write(row, encoder)
return bytes_writer.getvalue()
# Mesajları Kafka’ya Avro formatında gönderme
for _, row in df.iterrows():
avro_message = send_avro_message(row.to_dict())
time.sleep(2)
producer.produce("churn-topic", avro_message)
print(f"Sent message: {row.to_dict()}")
producer.flush()
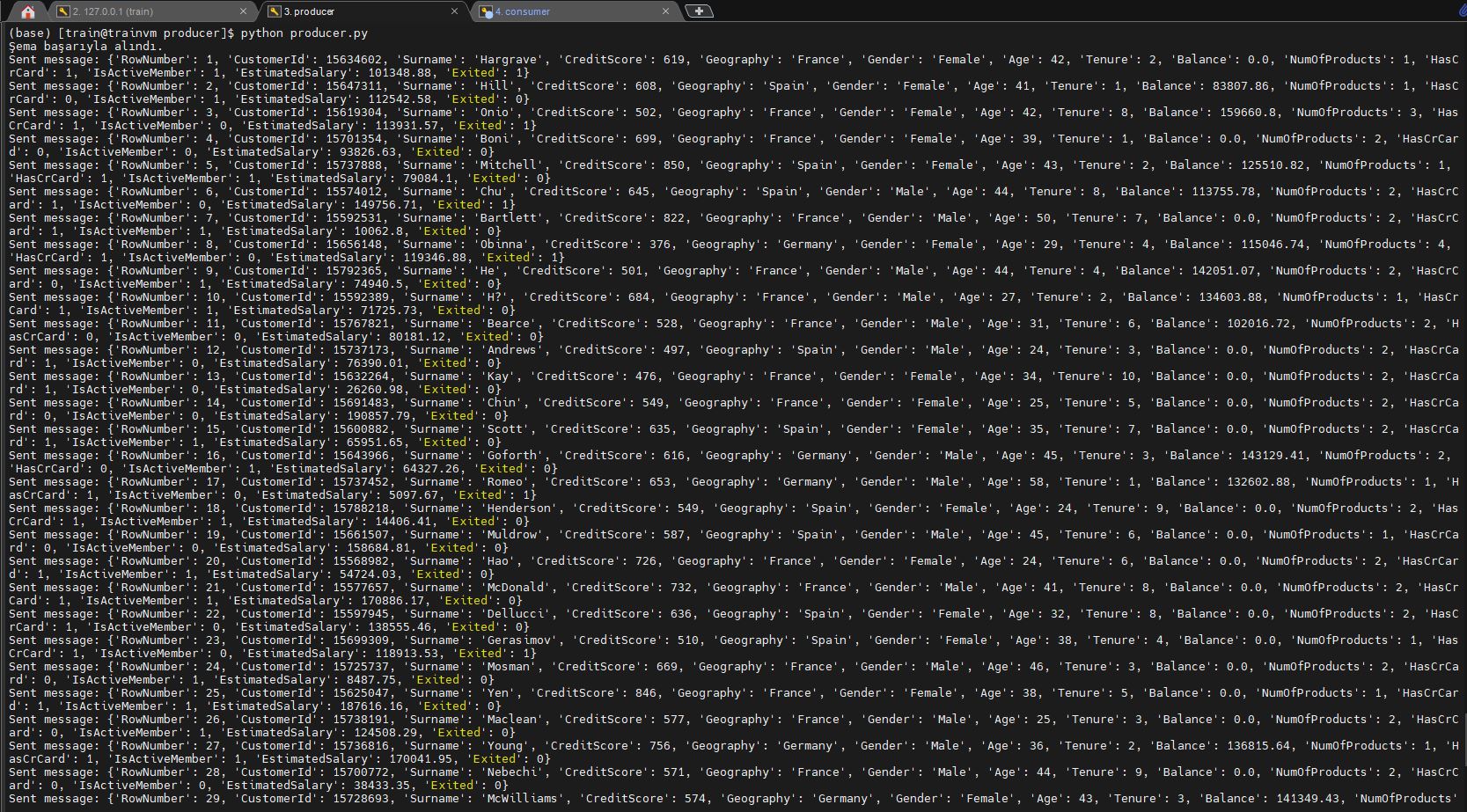
Özetleyecek olursak burada kullandığımız send_avro_message fonksiyonu, aldığı veriyi Avro şemasına göre serileştirerek (bayt dizisine dönüştürerek) Kafka’ya gönderilmeye uygun hale getirir. Bu sayede veriler Kafka’da yapılandırılmış bir şekilde saklanabilir ve Avro’nun sağladığı avantajlardan (schema evolution, sıkıştırma vb.) yararlanılabilir.
Çalıştırmak için: (Yeni sekmede açın, Env. aktif edin, dosya konumuna gelerek çalıştırın. )
python producer.py
Beklenen çıktı:
3. Python Consumer
consumer.py , Apicurio Registry’deki Customer Avro şemasını kullanarak churn-topic adlı Kafka konusundan gelen mesajları okur. Her mesaj Avro formatında çözülür ve PostgreSQL’de ChurnTable tablosuna kaydedilir. Yeni kayıtlar veritabanına eklenirken, mevcut kayıtlar göz ardı edilir.
Dosyayı oluşturmak için komut:
touch consumer.py
Dosya içeriği:
from sqlmodel import Field, SQLModel, create_engine, Session
import requests
from confluent_kafka import Consumer
from avro.io import DatumReader, BinaryDecoder
from io import BytesIO
from avro.schema import parse
import json
# Apicurio Registry URL ve Şema Bilgisi
REGISTRY_URL = "http://localhost:8080/apis/registry/v2/groups/default"
schema_id = "33e4eff9-b9d6-47f4-9814-c1383d043625"
# Şema çekme ve ayrıştırma
schema_response = requests.get(f"{REGISTRY_URL}/artifacts/{schema_id}")
schema = parse(json.dumps(schema_response.json())) # JSON'u string formatına dönüştürdük
# SQLModel Tablo Tanımı
class ChurnTable(SQLModel, table=True):
RowNumber: int = Field(primary_key=True)
CustomerId: int
Surname: str
CreditScore: int
Geography: str
Gender: str
Age: int
Tenure: int
Balance: float
NumOfProducts: int
HasCrCard: int
IsActiveMember: int
EstimatedSalary: float
Exited: int
# PostgreSQL bağlantısı
DATABASE_URL = "postgresql://myuser:mypassword@localhost:5432/mydatabase"
engine = create_engine(DATABASE_URL)
# Tabloyu oluştur
SQLModel.metadata.create_all(engine)
# Kafka Consumer ayarları
consumer_config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'my-group',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(consumer_config)
consumer.subscribe(['churn-topic'])
# Mesajları tüketme ve PostgreSQL'e ekleme
with Session(engine) as session:
while True:
message = consumer.poll(1.0)
if message is None:
continue
if message.error():
print(f"Consumer error: {message.error()}")
continue
# Avro verisini çözümleme
avro_bytes = BytesIO(message.value())
decoder = BinaryDecoder(avro_bytes)
reader = DatumReader(schema)
record = reader.read(decoder)
# SQLModel nesnesi oluştur ve veritabanına ekle
# Mevcut kaydı kontrol et
existing_record = session.get(ChurnTable, record['RowNumber'])
if existing_record is None: # Kayıt yoksa ekle
churn_record = ChurnTable(
RowNumber=record['RowNumber'],
CustomerId=record['CustomerId'],
Surname=record['Surname'],
CreditScore=record['CreditScore'],
Geography=record['Geography'],
Gender=record['Gender'],
Age=record['Age'],
Tenure=record['Tenure'],
Balance=record['Balance'],
NumOfProducts=record['NumOfProducts'],
HasCrCard=record['HasCrCard'],
IsActiveMember=record['IsActiveMember'],
EstimatedSalary=record['EstimatedSalary'],
Exited=record['Exited']
)
session.add(churn_record)
session.commit()
else:
print(f"Record with RowNumber {record['RowNumber']} already exists. Skipping.")
# Eklenen kaydı ekrana yazdır
print(f"Consumed Record: {record}")
# PostgreSQL ve Kafka Consumer bağlantılarını kapatma
consumer.close()Çalıştırmak için: (Yeni sekmede açın, Env aktif edin, dosya konumuna gelerek çalıştırın. )
python consumer.py
Beklenen çıktı:
POSTGRESQL Konteynerine Bağlanma
Verilerin doğru şekilde işlendiğini ve kaydedildiğini görmek için PostgreSQL veritabanına bağlanıyoruz. Ayrı bir sekme açalım, environmentı aktif edelim ve proje dizininde olduğumuzdan emin olalım.
Konteynere bağlanmak için komutu kullanalım:
docker exec -it schema_registry-postgresql-1 bash
Bu komut ile root’a bağlandık şimdi oluşturduğumuz kullanıcı ile mydatabase’e erişelim.
psql -U myuser -d mydatabase
ChurnTable tablosunda verilerin başarılı bir şekilde kaydedildiğini doğrulamak için örnek sorgular çalıştırıyoruz:
mydatabase=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------+-------+--------
public | churntable | table | myuser
(1 row)mydatabase=# select * from churntable limit(5);
mydatabase=#
RowNumber | CustomerId | Surname | CreditScore | Geography | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited
-----------+------------+----------+-------------+-----------+--------+-----+--------+----------------+---------------+-----------+----------------+-----------------+--------
3 | 15619304 | Onio | 502 | France | Female | 42 | 8 | 159660.796875 | 3 | 1 | 0 | 113931.5703125 | 1
1 | 15634602 | Hargrave | 619 | France | Female | 42 | 2 | 0 | 1 | 1 | 1 | 101348.8828125 | 1
2 | 15647311 | Hill | 608 | Spain | Female | 41 | 1 | 83807.859375 | 1 | 0 | 1 | 112542.578125 | 0
4 | 15701354 | Boni | 699 | France | Female | 39 | 1 | 0 | 2 | 0 | 0 | 93826.6328125 | 0
5 | 15737888 | Mitchell | 850 | Spain | Female | 43 | 2 | 125510.8203125 | 1 | 1 | 1 | 79084.1015625 | 0
(5 rows)
Makalemizin sonuna geldik. Apicurio Registry ile şema yönetimi, Kafka ve PostgreSQL ile veri akışı ve Docker ile ortam yapılandırmasının birleşimi, gerçek dünya uygulamaları için sağlam bir çözüm ortaya koyuyor. Bu yazıda, güvenli ve yapılandırılmış bir veri akış sisteminin nasıl kurulabileceğine dair kapsamlı bir örnek sunmaya çalıştım. Umarım veri yolculuğunuzda sizlere yardımcı olur.
Sevgiler,
Görsel Tasarım: Veri Akış Örneği – Merve Öztiryaki