

![]()
Veri Bilimi Projesi Nasıl Yapılır?
Her DS (data science) projesini kapsayan akış döngüleri yapmak çok mümkün olamamaktadır. Fakat yine de içerisinde ML çıktısı olan projeler için bir DS proje döngüsü nasıl olmalıdır sorusu yanıtlanmaya çalışılacaktır.
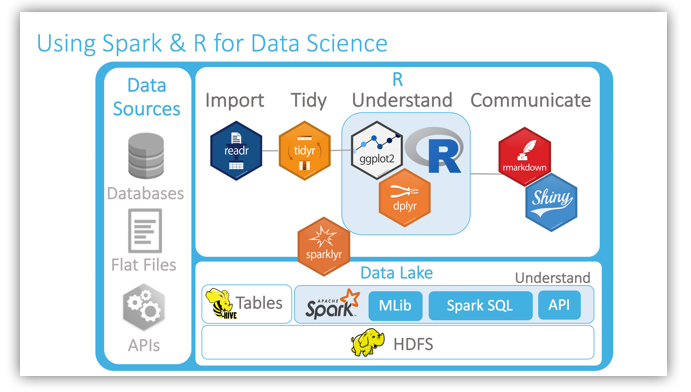
Microsoft’un dökümanlarında yer alan bir görsel:

Hadley Wickham’ın R for Data Science kitabında yayınlanan görsel:
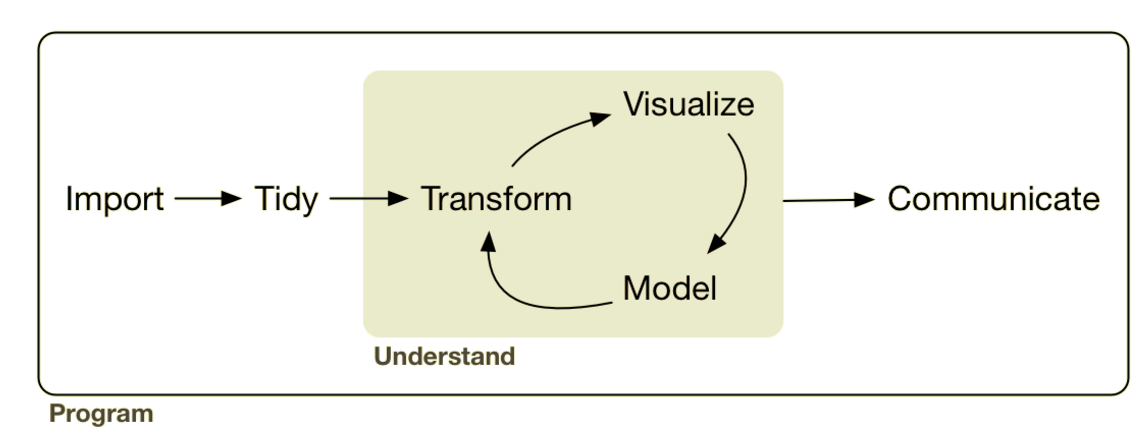
Yukarıdaki döngülerin hangi araçla yapılabileceği(R için):
sahibinden.com S-DS ekibi tarafından ML çıktısı odaklı geliştirilen iş planı formu:

A. İş Bilgisi (Business Understanding)
Bu madde içerisindeki tüm maddeler kurumsal şirketler içerisinde geliştirilen projeler için en önemli maddelerdir.
a. İş Domainini Anlamak ve Problemi Apaçık Tanımlamak

Bir problemi çözmek için 1 saatim varsa 55 dakikayı problemi anlamaya 5 dakikayı da çözüme ayırırım. Albert Einstein
Bir problemi tam anlamıyla ifade etmek çözümün kendisini göstermesini sağlayacaktır (Anonim)
b. Veri Bilimi Projesi Beklenti Yönetimi
Problem tam anlamıyla ifade edildikten sonra yine çok çok önemli olan ikinci madde DS projesi için ilgili birimlerin beklentilerinin yönetilmesidir. Bir çoklarımız deneyimlemiştir ki yola çıkılan an ile proje bitimindeki anda beklentiler bir çok kez uyuşmamazlık gösterebilmektedir. Bu durumun sebebi tüm ilgililerin proje ile ilgili aynı sonuçları bekliyor olması gerektiği durumunun gerçekleşmemesidir. Bununla birlikte ilgili konuda az ya da çok deneyimi olan herkes ile gerekli fikir alışverişleri yapılmalıdır. Data’ya bakarak karar verme anlayışı yerini dataya bakarak ve iş bilgisine başvurarak karar verme şekline dönüşmelidir.
c. Projenin Başarı Metriğinin Ne Olacağının Belirlenmesi
Diğer bir ifade ile projenin başarısı projenin içerisinde kullanılan ML modelinin tahmin performansı mı olacak yoksa entegre edilecek canlı bir sistem sonrası oluşacak geri dönüşümler üzerinden mi belirlenecek? Yoksa ikiside bir başarı değerlendirme yolu mu olacak? Bu soruların cevabı kritize edici tüm kişilerce çalışmanın en başında bilinmelidir. Bu çok çok önemli olan bi diğer maddedir.
Problemin tastamam tanımlanması, ilgili kişilerin proje çıktısı beklentilerinin sabitlenmesi ve başarı ölçümün ne şekilde olacağı belirlendikten sonra literatür taraması ve best practice araması basamağı gelmektedir.
B. Literatür Taraması ve Benzer En İyi Uygulamaların Araştırılması (Literature and Best Practice Search)
Dünyayı yeniden keşfetmeye gerek olmadığından Dünya’nın ilgili konularda ne tür çözümler bulduğunun araştırılması ve varsa uygulama noktasında başarı sağlandığı bilinen yaklaşımların ilgili proje için uygunluğunun araştırılması. Çalışma neticesinde Dünya’nın yaklaşımını biliyor olmak bize projemize başlamak için bir fikir verecektir.
Dünya’da direk karşılığı bulunamayacak olan problemler için elimizdeki analitik düşünce, doğru soruları sormak, SL, ML yöntemlerini kullanarak çözümler üretmemiz gerekecektir. Bu durum bir Veri Bilimci için en değerli özelliktir. Yaklaşım geliştirmek. Varsayımlar yapmak…, bunları test etmek…, sonuçlara göre kararlar verip ilerlemek. İşin matematiğini bilmek ve problemlere modifikasyonlar yaparak yaklaşabilmek.
C. Veriyi Anlamak (Data Understanding)
Bu madde de veriyi anlamak olarak kastedilen şirket içi veri yapısının anlaşılmasıdır. Çok büyük miktarda veri yok ise bu madde fazla önemli değildir. Geliştirilecek proje için yapılan teorik ön inceleme ve araştırma sonrasında şirket içi verilerin ilgili proje için uygun olup olmadığının araştırılmasıdır. Projenin dokunacağı tabloların belirlenmesi, gerekiyorsa aggregate edilmiş tabloların oluşturulması ve yine gerekiyorsa veri platformları arasında gerekli verileri aktarılması.
D. Özellik Mühendisliği (Feature Engineering)
ML odaklı bir proje geliştirme sürecinden bahsettiğimiz için tidy süreci, keşifçi veri analizi ve veri manipülasyonu başlıklarını bu başlık altında toplayabiliriz. Bu başlıkların her birisi ayrı bir öneme sahip. Hem bu basamaklar hemde modelleme basamağı içerisinde yer alacak olan feature engineering işlemi için detaylı yazılara yer verilecektir.
Tidy Süreci:
Tidy süreci ile alakalı şu yazımızı incelemelisiniz. Tıkla. Burada çok detaya girilmeyecektir fakat tidy süreci özetle: analitik herhangi bir çalışma öncesinde verinin yapısal anlamda düzenli hale getirilmesidir. Buradaki düzenli ifadesi her bir satırın ilgilenilen gözlem birimini ve her bir sütunun bir değişkeni ifade etmesi gerektiğini ifade etmektedir. Diğer bir ifade ile her bir satırda sadece tek bir gözleme ait değişken değerleri var olmalıdır.
Keşifçi Veri Analizi:
Araba alacağız diyelim hem para vereceğiz hemde kendisine bir açıdan hayatımızı emanet edeceğiz. Sadece şöyle bir kaportasına bakıp o arabayı alır mısınız?
İnsan bir merak eder yahu. Kaç km, boya varmı, değişen var mı, otomatik mi manuel mi, dizel mi benzinli mi, yakıt tüketimi nasıl?
Hedef sadece araba almak ise ve sadece bu sonuç ile ilgileniliyorsa başarılısın arabayı aldın.
İstatistiksel Öğrenme ve Keşifçi Veri Analizi barındırmayan DS projelerinin çıktıları maalesef sadece araba almaktan ibarettir.
İstatistikçilerin yıllardır Descriptive Statistics olarak isimlendirdiği bu süreç Veri Bilimi süreçlerinin en kritik basamaklarından birisidir. Veri Bilimcinin özelliklerini sayarken ifade ettiğimiz mevcut durumu anlama ve veri içerisindeki yapıları ortaya çıkarma işlemleri bu basamakta yapılmaktadır. Bunun içerisine pattern detection ve veri görselleştirme tekniklerinin tamamı dahildir.
Hazır scriptleri al, uygula. Ezberlemeyin, mantığını öğrenin! Algoritmaya verdim inputları aldım outputları dünyasında olanlar olmaya devam etsinler. “Script Scientist” olarak tanımladığımız ve hatta kendi aramızda SS dediğimiz bu arkadaşlar 90’ların web dünyasında “lamer” olarak adlandırılıyordu.
Hatırlayanlar vardır emeğe saygı kavramı vardı bir de forumlarda, yazıların sonunda emeğe saygı gifleri falan yer alırdı. Bu sebeple emeğe saygı duyalım arkadaşlar 🙂 Yazımızı paylaşarak, yorum atarak, geri bildirimlerde bulunarak tek mazotumuz olan etkilişimi sağlayın ki arabamız gitsin 🙂
Bir de eğer veriyi satır ve sütunlardan ibaret zannedenlerden isen hemen tövbe et 🙂 Satır ve sütun denmez onlara. Veri canlıdır. İçinde hayat barındırır. Sizin o satır dediğiniz şeyler varya onlar satır değil gözlem, yani bir nitelikleri var. Önce buradan başlayın. No satır ve sütunlar, Yes Gözlemler ve değişkenler .
Peki feature’da deniliyor bunlara hatta baya da kallavi adamlar diyor. Çok doğru! Mükemmel bir nokta. Aynı zamanda variable diyenlerde var… Bu konunun ayrımı nedensellik ilkesi isimli yazıda dile getirilecektir. Evet bunlara her zaman gözlem denmez. Bazen satır oluverirler. Bazen feature oluverirler. Önemli olan ayrımının farkındalığını taşımaktır.
Evet veri seti içerisindeki gözlemlerin değişkenler odağındaki değişimlerinin inceleceği bu bölüm bir veri bilimi projesinin süprizlere en açık kısmıdır. Bu bölüm ile alakalı oldukça detaylı yazılar yer alacaktır. Şimdilik mevcut durumun analizinin bu basamakta yapılacak olduğunu ve bu basamak olmadan diğer basamaklara geçmenin eksiklik olacağını ifade etmiş olalım.
Veri Manipülasyonu & Feature Engineering:
Bu basamakta tidy hale getirilmiş ve daha sonrasında veri görselleştirme adımında yapısı anlaşılmış olan veri üzerinde eksik veri analizi, aykırı gözlem incelemesi, tutarsızlıkarın incelenmesi gibi çok değişkenli istatistiksel yaklaşımların uygulanması basamakları yer almaktadır. Bu başlıktaki tüm maddeler ele alınacaktır. Bu basamakta en dikkat çekici olan durum feature engineering işlemleri için Veri Bilimcinin yaratıcılığını kullanması ve fiziki olarak var olmayan değişkenleri nedensellik bağlamını göz önünde bulundurarak oluşturmaya çalışmasıdır.
Tabi ki uçak geçikmelerini tahmin etmek için fok balıklarının ölüm oranlarının modele alınmasını kastetmiyoruz! Aynı zamanda korelasyonu da kastetmiyoruz! Korelasyon her zaman nedensellik ifade etmez! ist 101.
E. Modelleme ve Model Başarı Değerlendirme (Modelling & Model Evaluation)
Elimizde her türlü kirlilikten dağınıklıktan ve anormalliklerden arınmış bir data var ve sıra geldi kahinlik yapmaya!
Soru Şu: Tahminsel bir model kuracağım, elimde bir çok algoritma var. Ama en havalısı kaggle’da gördüğüm bir yarışmada kullanılan X algoritması. Ben tahminsel modelimi bu algoritmayı kullanarak yapacağım ne dersin?
Cevap: Akşam dışarı çıkacaksın, arkadaşlar ile rock konserine gidiyorsun, dolapta bir sürü elbise var ama en havalısı smokin, sen onu giy.
DS süreçlerinde en önemli basamaklardan birisi mevcut analitik yaklaşımlar (SL + ML) ile bir iş problemini çözebilmek için yaklaşım geliştirebilmektir.
Gözlemlerimiz ve işe alım süreçlerinde en sık karşılaştığımız problemlerden birisi bir iş probleminin çözümü için istatistik ve makine öğrenmesi kullanılarak problemlere çözüm geliştirilememesidir. Bir kaç örnek verilecek olursa:
- En önemli madde: İlgili problem için işin teorisine bakılması gerektiği! İktisat teorisi ne diyor? Davranış bilimleri ne diyor? …
- Makine öğrenmesi takıntısı!
- Her problem için aynı algoritmayı kullanma eğiliminde olmak. Olası onlarca belki yüzlerce model arasından performans karşılaştırmaları yapılarak model seçilmesi gerekir.
- Çok bariz bir şekilde bağımlı değişkeni sürekli değişken olan problemlerin çözümü için ısrarla sınıflandırma algoritmalarına yönelim olması.
- Bağımlı değişkenin sınıflarının belli olduğu ve sınıf sayısının 2’ten fazla olduğu durumlar için -örneğin 10- bağımlı değişkenin 10 sınıflı olmasının hiç sorgulanmadan algoritma seçmelere girilmesi.
- Kümeleme ile sınıflandırma problemlerinin karıştırılıyor olması.
- Makine öğrenmesi ve nedensellik ilkesi ayrımının farkında olmamak. Bunu açıkca ifade edebiliriz ki Türkiye’de -iş dünyasında- bu konudaki farkındalık oldukça az.
- Gerekliliği var ise teorik varsayımların incelenmesi
F. Çalışmanın Canlı Sistemlere Entegrasyonu (Running On Production)
Çalışmanın her zaman canlı sistemlere entegre edilmesi durumu tabi ki söz konusu değil. Bu bir çok projeye göre farklılık gösterecektir. Bu bir proje için bir SPSS çıktısının excel ile ilgili birimlere gönderilmesi şeklinde olabilir. Bir e ticaret sitesinde kişiler ile alakalı tavsiye sistemleri ile ilgili çalışıldıysa herhangi bir platformda geliştirilen proje çıktıları mysql tablolarına basılıp bunun aracılığı ile arayüzden konuşma sağlanıp ilgili sonuçlar elde edilebilir. Yine buna benzer olarak bir web sistemi içerisinde tahminsel sonuçlar mysql tablolarında tutulup ihtiyaç halinde çağırılarak kullanılabilir. Veya daha ileri düzeyde anlık olarak tahminsel bir model çalıştırılması gerekiyor olabilir. Bununla alakalı Mustafa Kıraç’ın genel hatları ifade eden güzel bir yazısı var.
Benzer şekilde job planlanması da her ihtiyaca göre değişebilir. Planlama yapmak gerekmeyedebilir. Bu basamakla ilgili ifade edilebilecek belki de en önemli madde:
Modeller kullanılarak üretilen sonuçlar sonrasında gerçekleşen kullanıcı hareketleri ve bu hareketlerin yapıları yani verileri modelleme için tekrar kullanıldığında modelleri kısır döngülere sokup ciddi yanlılıklara sebep olacaktır. Diğer bir ifade ile Job’lara bağlanmış canlı sistemlerdeki projelerin kullanıcı yönlendirmeleri ve bu yönlendirmeler sonrasında kullanıcıların verdiği tepkilerin ürettiği verilerin modelleme için tekrar çalışacak olan Job’lara dahil EDİLMEMESİ gerekir. Bu durum DS-ML süreçlerinde çok kritik öneme sahiptir.
Canlı sistemlere entegrasyon konusunda detaylı yazılar ele alınacaktır.
Ek olarak canlıya çıkan sistemlerinde testlerinin yapılması ve sürecin dönüşümlü olarak devam etmesi gerekiyor. Tüm bu bilgilerden sonra Microsoft’un yayınladığı görsel tekrar incelenecek olursa:
Veri bilimi alanında daha derinleşmek ve tüm bu süreçleri doğru bir kaynaktan öğrenmek isterseniz eğer Data Scientist Bootcamp eğitimine kayıt olabilirsiniz.
Yağ var, un var, şeker var helva ? 🙂 Çok güzel. Hemen izleyelim:
Motivasyon, SL & ML, Programlama Araçları var, ne duruyorsun?
Elimizde bir DS projesinin aşağı yukarı nasıl ele alınması gerektiği var olduğuna göre şimdi yapacak bir proje bulmak lazım!
Çok güzel bir paylaşım olmuş elinize sağlık.
Oldukça faydalı bir yazı. Çok teşekkürler.
Elinize kolunuza sağlık. Analiz adına sizden çok şey öğreneceğim. Lütfen bizleri geliştirmeyi bırkmayın. Sağlıcakla kalın.