

Merhabalar. Bu yazımızda Apache Spark AWS S3 entegrasyonu yapacağız. Bu kapsamda bir Spark dataframe’i AWS S3’e nasıl yazacağımızı ve S3’den Spark ile nasıl veri okuyacağımızı öğreneceğiz. Bu işi lokal makinemizdeki Spark ile yapacağız. Peki bunun yazı haline gelecek neyi var diye sorarsanız, ben de “Biraz gıcık bir iş, ben çektim siz çekmeyin” derim. Aslında birkaç püf nokta var dikkat edilmesi gereken, onları tamam yaptığınızda kolay iş. Örneğimiz basit bir csv dosyasını lokal diskimizden okumak ve bunu S3’e yazmak olacak. Daha sonra yazdığımızı tekrar S3’ten okuyup ekrana yazdıracağız.
Kurulum, Konfigürasyon ve Uygulama
Ortam Bilgileri
Spark: 3.0.0 (Hadoop 3.2)
Java: 1.8.0
Python 3.6.8
İşletim Sistemi: CentOS7
IDE: Jupyter Notebook
Yukarıda paylaştığım bilgiler benim bu çalışmayı yaptığım anda sahip olduğum ortam bilgileridir. Aynı uygulamayı yapmak için aynı ortam ve sürümleri kullanmak zorunlu değildir. Ancak Spark’ın Hadoop 3.2 derlemesini kullanmanızı tavsiye ederim zira bu S3 işinde en püf nokta maven repo’dan uygun sürümün seçilmesi. Ayrıca S3 yerine minio falan da kullanırsanız minio Hadoop 2.7 derlemesini kabul etmiyor veya iyi çalışmıyor, birşeyleri eksik yapıyor, tam hatırlayamadım.
Varsayımlar
AWS S3 bucket’iniz yaratılmış durumda, accessKeyId ve secretAccessKey elinizde mevcut.
Kodlama
Spark’ı findspark ile bulalım.
import findspark
# /opt/manual/spark: this is SPARK_HOME path
findspark.init("/opt/manual/spark")
Spark kütüphanelerini indirelim
from pyspark.sql import SparkSession, functions as F from pyspark import SparkConf, SparkContext
S3 Bağlantısı için Gerekli Kütüphaneler
Şimdi burada S3 bağlantısında kullanılacak ilave kütüphaneleri (jar dosyalarını) indirip Spark’ın diğer jar dosyaları arasına koyacağız. Bunun elbette başka yöntemleri de var. Ancak burada bunu tercih ettim.
Maven repo’dan dosyaları indirirken mutlaka spark-hadoop sürümüne dikkat etmelisiniz (Bunu spark’ı indirip kurarken karar veriyorsunuz ve bir çok derleme arasından seçiyorsunuz bendeki örnek Spark 3.0.0. Hadoop 3.2).
-
hadoop-aws-3.2.0.jar maven içinde arama:
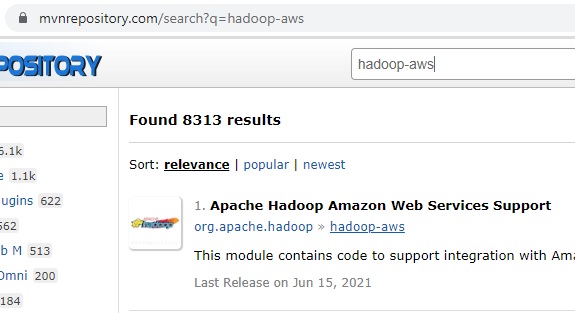
-
Doğru versiyonun seçimi:
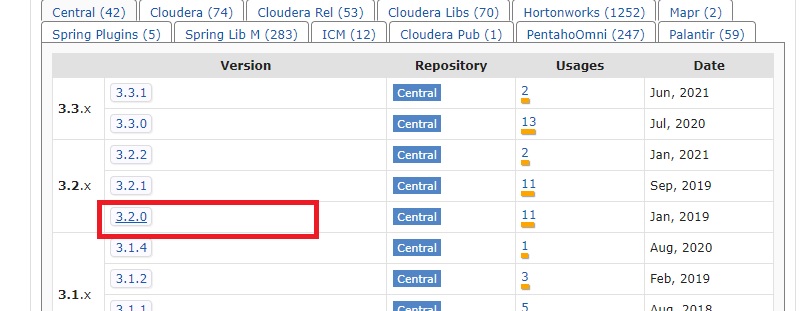
-
Hadoop-AWS jar linkinin kopayalanması:
Aynı sayfadan uyumlu sürüm olan aws-java-sdk-bundle linkine erişilmesi.
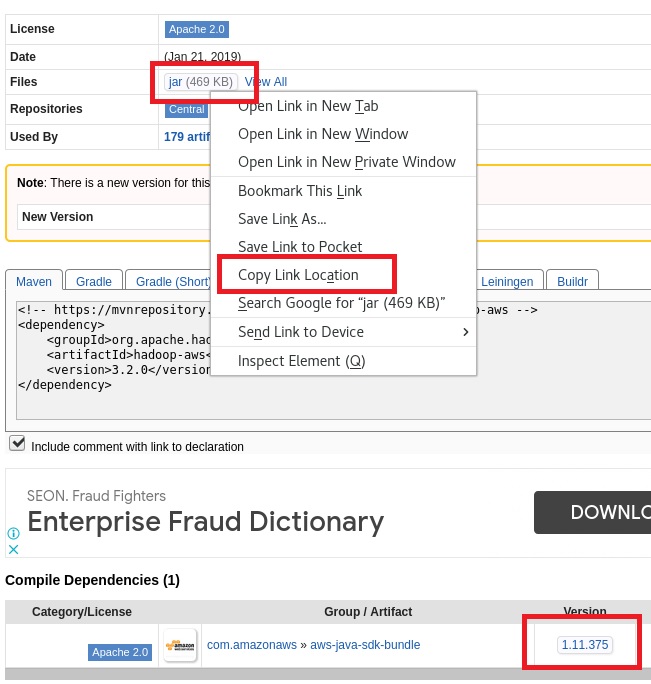
-
AWS SDK jar Linkinin Kopyalanması

Doğru jar dosyalarına ait linkleri elde ettikten sonra kopyalama ve taşıma işi:
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.375/aws-java-sdk-bundle-1.11.375.jar mv aws-java-sdk-bundle-1.11.375.jar hadoop-aws-3.2.0.jar /opt/manual/spark/jars/
Spark Session
spark = SparkSession.builder.getOrCreate() spark.verision Output 3.0.0
Konfigürasyon
Önce erişim anahtarlarını değişkenlere atayalım. İsterseniz bunu ortam değişkenlerine de tanıtabilirsiniz. Ancak bu anahtarları github gibi repolara göndermeyin, başkasıyla paylaşmayın, şüpheniz varsa anahtarları iptal edip yenilerini üretin.
accessKeyId='Buraya_kendi_access_id_nizi_yazın' secretAccessKey='Buraya_kendi_access_secretinizi_yazın'
Şimdi konfigürasyonları bir fonksiyon ile tanımlayalım ve SparkContext’e ekleyelim:
def load_config(spark_context: SparkContext):
spark_context._jsc.hadoopConfiguration().set('fs.s3a.access.key', accessKeyId)
spark_context._jsc.hadoopConfiguration().set('fs.s3a.secret.key', secretAccessKey)
spark_context._jsc.hadoopConfiguration().set('fs.s3a.path.style.access', 'true')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.impl', 'org.apache.hadoop.fs.s3a.S3AFileSystem')
spark_context._jsc.hadoopConfiguration().set('fs.s3a.endpoint', 's3.amazonaws.com')
load_config(spark.sparkContext)
Veri setini okuyalım. Buradan erişebilirsiniz.
df = spark.read \
.option("inferSchema",True) \
.option("header", True) \
.csv("file:///home/train/datasets/simple_data.csv")
Veri setine göz atalım:
df.show(3) +------+-----+---+--------+--------+-----------+ |sirano| isim|yas| meslek| sehir|aylik_gelir| +------+-----+---+--------+--------+-----------+ | 1|Cemal| 35| Isci| Ankara| 3500| | 2|Ceyda| 42| Memur| Kayseri| 4200| | 3|Timur| 30|Müzisyen|Istanbul| 9000| +------+-----+---+--------+--------+-----------+ only showing top 3 rows
Spark Dataframe’i AWS S3’e Yazma
Yukarıda gerekli ve uygun sürümlere sahip kütüphaneleri indirdikten ve Spark konfigürasyonunu yaptıktan sonra artık bu notada iş çocuk oyuncağı ve lokal diske yazmaktan farksız.
df.write.format('csv').option('header','true') \
.save('s3a://spark-s3-example-bucket/simple_data', mode='overwrite')
Sonucu AWS üzerinden kontrol edelim.

Spark ile AWS S3’ten Veri Okuma
Şimdi bu veriyi Spark ile tekrar okuyalım.
df_s3 = spark.read.format('csv').option('header','true') \
.load('s3a://spark-s3-example-bucket/simple_data')
Ekranda görelim:
df_s3.show(3) +------+-----+---+--------+--------+-----------+ |sirano| isim|yas| meslek| sehir|aylik_gelir| +------+-----+---+--------+--------+-----------+ | 1|Cemal| 35| Isci| Ankara| 3500| | 2|Ceyda| 42| Memur| Kayseri| 4200| | 3|Timur| 30|Müzisyen|Istanbul| 9000| +------+-----+---+--------+--------+-----------+ only showing top 3 rows
Bir yazımızında burada sonuna geldik. Gökten 3 elma düştü; biri S3’e, diğeri Cassandra’ya, öteki HDFS’in kafasına düşsün. HDFS’e boşuna öteki demedik 🙂
Kapak: Photo by Francesco Ungaro on Unsplash
https://unsplash.com/photos/VSwlS0PpWwc