
GİRİŞ
Merhaba,
Bu yazımda aşırı öğrenme konusunu genel olarak ele alacağım. Amacım aşırı öğrenmenin nasıl birşey olduğunu tanımlamak ve zihinlerde daha anlaşılır hale getirmek. Aşırı öğrenme problemi için alabileceğimiz önemleri inceleyerek, probleme bakış açımızın öneminden bahsedeceğim.
Kurduğunuz modellerin çok iyi sonuç vermesini nasıl karşılarsınız? Modelin %95 doğruluk ile çalışması kulağa hoş gelmiyor mu? Peki gerçekten sonuçlar öyle değilse.
Aşırı öğrenme (over fitting) , algoritmanın eğitim verisi üzerinden en alt kırılıma kadar çalışıp, sonuçları ezberlemesi ve sadece o veriler üzerinde başarı elde edebilmesidir. Eğitim verisi ile kurduğunuz modeli, test verisi üzerinde çalıştırdığınızda muhtemelen sonuçlar eğitim verisine göre çok düşük çıkacaktır.
Aşırı öğrenme konusunu şöyle hayal edebiliriz belki; herkesi mutlu edemezsin! Algoritma tüm değerleri doğru tahmin edeceğim aman hiç bir değer dışarda kalmasın derse uç noktalara, her kenar köşeye gidecektir. Halbuki yaptığımız modelin amacı, her şeyi tahmin etmesi değil genel bir doğru elde etmesi yani genel bir örüntü bulmasıdır ve bu genel doğrunun(örüntünün) sonraki verilere de uygulanabiliyor olmasıdır.
Algoritma çok karmaşık ise veri içindeki örüntüyü bulmak yerine, öğrenme süreci gürültüyü ezberlemek ile sonuçlanabilir. Aşırı öğrenme problemi olan modeller yüksek varyans problemi içerebilir.
K katlamalı çapraz doğrulama ile raslantısallığı azaltarak sonuç metriklerin tutarlılığını sağlamak ve sonuçları doğru değerlendirmeye çalışıyoruz.
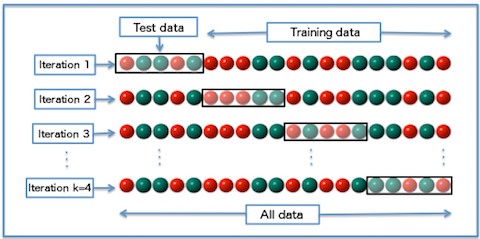
Sonuçları doğru değerlendirmek için eğitim verisi ve test verisinin benzer özelliklere sahip olması gerekir. K katlamalı çapraz doğrulama (k-fold cross validation) yöntemi kullanarak verinin tüm parçalarının eğitim ve test verisinde yer almasıyla daha doğru bir öğrenme süreci oluşturmak, performans göstergelerini bu şekilde incelemek aşırı öğrenme hakkında bize daha net bilgi verecektir.
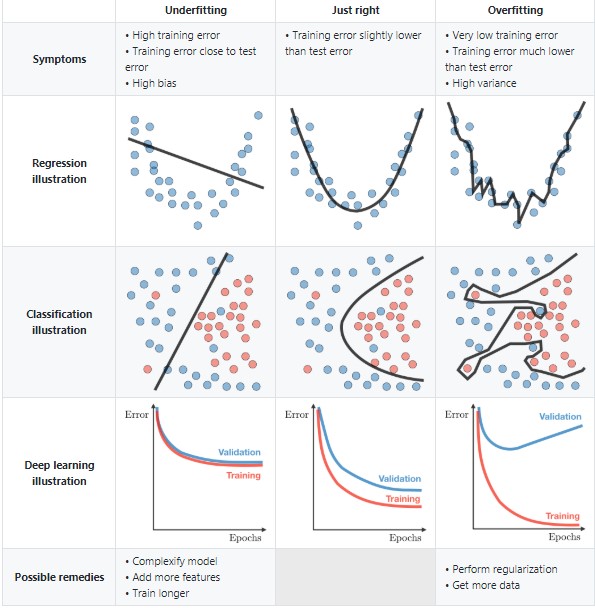
Aşırı öğrenme problemini nasıl çözebiliriz?
- Değişkenleri Azalt
Model girdilerini azaltabilirsin, çok fazla değişken modelin aşırı öğrenmesine sebep olabilir. Temel Bileşen Analiz (PCA) kullanarak değişken sayısını indirmiş, birbiri ile korelasyonlu olan girdileri elemiş olursun. Doğru açıklayıcı değişkenleri bularak basit bir model kurmak daha mantıklıdır.
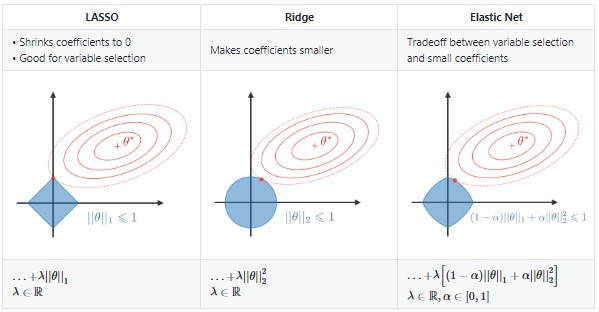
- Düzenlileştirme(Regularization)
Düzenlemeler kayıp fonksiyonunu cezalandırıyor. Ridge Regresyonu ve Lasso Regresyonu düzenlileştirme çözümlerinin aralarındaki fark cezalandırma derecesidir. Ridge Regresyon önemsiz değişkenin kat sayısını azaltır ama yinede tüm değişkenleri kullanır, Lasso ise değişken kat sayısını tamamen sıfır yaptığı için sadece belli değişkenleri seçmiş olur.
- Ridge Regresyonu (Önemsiz değişkenlerin kat sayılarını küçült.)
- Lasso Regresyonu (Önemsiz değişkenlerin kat sayılarını 0 yap.)
- Elastic Net (Değişken seçimi ve kat sayı küçültmesi arasında denge)
- Daha fazla veri eklemek
Eğer aşırı öğrenme problemi, eğitim verisinde az veri olmasından, dolayısıyla tek tip veri olmasından kaynaklanıyor ise daha fazla çeşitli veri eklemek gerekir. Burada engele takılmamak için veri hazırlığını dikkatli yapmak, eğitim verisi ve test verisi ayrımını dikkatli incelemekte fayda var.
- Erken Durdurma
Eğitim verisi ile test verisi hataları arasındaki fark açıklığı belli bir seviyeye geldiğinde eğitimi durdurur. Bazı algoritmalar bunu sürekli kontrol ederek otomatik olarak yapar.
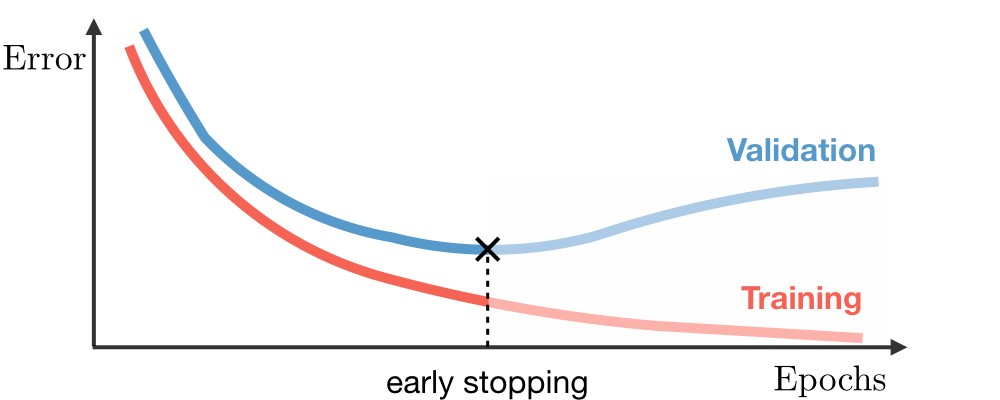
Eğitim verisi ve test verisi sonuçları aynı ama halen bir problem var ?
Yukarıda paylaştığım bilgileri internette kolaylıkla bulup, okuyup hızlıca kendi probleminize adapte edecek hale gelebilirsiniz. Fakat probleme aşırı sistematik bakarsanız gözden kaçırdığınız bazı durumlar olabilir, o yüzden çözmeye çalıştığınız problemi çok iyi anlamanız gerekir. Şöyleki;
Model öncesi önlemlerimizi k katlama çapraz doğrulama ile aldık, model sonrasında da eğitim ve test verisini karşılaştırdığımız sonuçlar benzer çıktı. Yani model eğitim verisini doğru tahmin ediyor, test verisini edemiyor gibi bir durum yok. Her iki grup içinde benzer sonuçlar geliyor. Eğitim ve test hata grafiklerinde de bir problem yok. Modelleme kısmında da topluluk öğrenmesi(ensemble) yöntemlerle birden fazla model kurduğumuzu düşünelim. Fakat yine de başarı oranımız çok yüksek. Sonuçlara güvenebilir miyiz?
Modelden aşırı yüksek derece başarı aldığımızda mutlaka şüphelenmemiz gerekir. Problemin sonucunu bu derecede doğru tahmin etmesi, en baştan hatalı bir data hazırladığınız anlamına gelebilir.
Diğer taraftan siz elinizdeki problemi bir hayal edin, hesaplama olarak tabi ki insan zekasından çok üstün makineler ama iyice düşünün gerçekten bu model sizin hiç düşünmediğiniz birşeyi tespit etmiş ve burada %90 üstü doğruluk sonucu mu elde etmiş ?
En önemli açıklayıcılığa sahip değişkenleri incele.
Modelde en önemli açıklayıcılığa sahip değişken ile hedef değişken arasında nasıl bir ilişki var? Aralarındaki korelasyona bakman gerekir çünkü hedef değişkeni doğrudan temsil eden veya çok yüksek seviyede temsil eden bir değişken verdiysen girdi değişken olarak, o zaman tabi ki sonuçlar yüksek çıkacaktır. Korelasyona da bakmadan önce şunu da düşünmen gerekir, o hedef değişkeni girdi değişkenin içerisinde bir parça olarak yer alıyor olabilir. Yani zaten girdi değişken ile hedef değişken içiçe durumu varsa model tabi ki o yönde ilerleyecektir.
İşte bu durumda sadece karmaşıklık matrisi veya eğitim ve test verisi sonuç parametlerini karşılaştırarak, burada aşırı öğrenme durumunu bulamazsın. Çünkü modelin aşırı öğrenmesine sebep olan şey girdi değişkenlerden bir tanesidir ve bu değişken eğitim ve test gruplarında aynı şekilde bulunmaktadır. Burada ki problemde modelin belki bir suçu yok ama sonuçta tahmin üretirken model aşırı korelasyon olan bir girdi değişkeni kullandığı için sonuç bu şekilde gelmektedir.
Daha net olması için örnek ile ifade edelim;
Örnek : Sınıflandırma problemi olarak müşterinin terk etme eğilimini hesapladığımızı düşünelim, müşterinin çıkmadan hemen önce çağrı merkezi araması, şikayet kaydı bırakması, mail göndermesi veya ürün üzerinde yaptığı başka bir işlem artık standart bir hale dönüştüyse yani sonuca giden yola çok yakın zamanda süreç olarak mutlak gerçekleşiyor ise işte bu da senin aslında hedef değişkenin sayılır. Bu değişkenleride modele koyduğun zaman model tabi ki çok iyi tahminler üretir. Ama sana bir faydası olmaz çünkü terk etme durumu gerçekleşmek üzeredir veya belki de gerçekleşmiştir artık bu aşamada da karşı bir önlem alman için yeterli zamanın yoktur. Burada çözüm olarak hedef değişkenini oluşturan girdilerin belli bir periyodunu veri hazırlığında iken çıkartmak, yani müşterinin terk etmesinden önceki 1-3 haftalık ( iş bilgisine problemine göre değişir bu süre) bilgiyi çıkarman gerekir.
Örnek : Regresyon problemi olarak ürünün fiyatını tahmin etmeye çalıştığımızı düşünelim ve öyle bir girdi değişkeni var ki zaten her zaman fiyatın belli bir yüzdelik kısmı alınarak oluşan bir girdi değişkeni olsun. Algoritma zaten o bağıntıyı yakalayıp yüzde yüz doğru tahmin üretecektir. İşte burada zaten modele ihtiyacın yok, kural tanımlama ile zaten problemi geriden gelerek çözüp sonuca ulaşabilirsin.
Örnek : Bir restorandaki ödenen yemek tutarı ile bahşiş tutarı arasındaki ilişkiyi hesaplamak istediğinizi düşünelim. Eğer bahşiş tutarı toplam tutarın içinde ise korelasyon testini yapmadan önce, ödenen yemek tutarının içerisinden bahşiş tutarını çıkartmamız gerekir. (Vahit Keskin’in Veri Bilimi ve Machine Learning eğitimde korelasyon analizi kısmından alınan örnektir.)
Kendi iş probleminize göre sizinde bu tarz gerçek hayattan örnekleriniz var ise lütfen yorumlar kısmında paylaşınız. Çünkü gerçek hayatın içinde yaşanan problemlerin standart kitaplarda veya internette yazan problemlere göre daha değerli olduğunu düşünüyorum.
SONUÇ
Değişkenlerinizi sorgulayın!
Nobel ödüllü ekonomist Ronald H. Coase‘un güzel bir sözü var; “Veriye yeteri kadar işkence yaparsanız itiraf eder”, işte bu yüzden değişkeni sorgulamak ve eleştirel yaklaşmak çok önemlidir. Artistik cümlelerden bir tane daha söyleyelim, çöp girerse çöp çıkar(ingilizcesi daha da artistik garbage in garbage out!), yani eğer sen veri hazırlığı kısmında eksik, hatalı, yanlı bir durum oluşturduysan veya bu zaten öyle geldiyse sonuçlarda aynı şekilde o doğrultuda çıkacaktır.
Şüphe ve sorgulama isteğinizin hiç bitmemesi , sağlıklı, lezzetli ve faydalı modeller oluşturmanız dileğiyle.
Kaynak:
https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-deep-learning-tips-and-tricks
Kapak görseli : https://towardsdatascience.com/my-journey-into-machine-learning-class-4-eb0f681cec65
Elinize, emeğinize sağlık,..