

![]()
Apache Kafka, verilerin bir sistemden hızlı bir şekilde toplanıp diğer sistemlere hatasız bir şekilde transferini sağlamak için geliştirilen dağıtık bir veri akış mekanizmasıdır. Başlangıçta 2011’de Linkedin tarafından Java ile geliştirilen Kafka daha sonra Apache çatısı altında açık kaynak bir projeye dönüştürülmüştür. Günümüzde Linkedin, Netflix, Uber, Twitter gibi devasa boyutlarda veriye sahip olan birçok firma tarafından kullanılmaktadır.
Günümüzde veri ekosistemlerinde yapılandırılmış (structured) verilerin yanında kullanıcı hareketleri (arama ve tıklama verileri), log verileri, sensör verileri gibi yapısal olmayan (unstructured) veriler bulunmaktadır. Bu verilerin Spark ve Flink gibi teknolojilerle veya doğrudan Kafka Streams ile gerçek zamanlı analizi firmalar için çok önemli hale gelmektedir. Verilerin kaynak sistemlerden, bu analiz sistemlerine hatasız şekilde aktarılmasında Kafka kilit role sahiptir. Bu Kafka’nın kullanım amaçlarından sadece biridir. Kafka, büyük veriden, ilişkisel veri tabanlarına, veri ambarlarından, NoSql sistemlere kadar sayısız veri teknolojileri arasındaki veri akışının protokol ve sistemden bağımsız olarak sorunsuz bir şekilde yapılmasını sağlar. Üstelik bunu milisaniyeler seviyesinde bir gecikme ile yani gerçek zamanlı olarak yapar.
IoT cihazlarının daha da yaygınlaşması ve 5G’nin hayatımıza girmesiyle veri boyutları ile verinin üretim hızı ve çeşitliliği artacaktır. Dolayısıyla da verinin hatasız ve problemsiz bir şekilde aktarılmasını ve gerçek zamanlı analizini sağlayan Apache Kafka gibi platformlar daha da önemli hale gelecektir.
Yazının geri kalan kısmında, Kafka’nın mimarisini daha iyi anlayabilmek için topic, partition, producer, consumer gibi en temel Kafka bileşenlerini ayrıntısıyla inceleyeceğiz.
1. Topic ve Partition
Topic verilerin gönderilip alındığı veri kategorisinin adıdır. Kullanıcı tarafından isimlendirilirler. Bir Kafka cluster’ında binlerce topic olabilir.
Topic’ler partition’lara ayrılırlar. Partition’lar 0’dan başlayarak artan sayıda devam eder. Topic’de 1 partition oluşturulabileceği gibi senaryoya göre bin partition da oluşturulabilir. Topic yaratırken verdiğimiz partition sayısını sonradan değiştirebiliriz.
Veri bir kez bir partition’a yazıldıktan sonra bir daha değiştirilemez. (immutability)
Partition’ların 0’dan başlayarak artan sayıda giden ID’leri vardır. Bunlara offset denir. Offset partition’la beraber bir anlam ifade eder, 5. offset diyemeyiz mesela, partition 2’nin 5. offset’i diyebiliriz. Her partition’da farklı sayıda offset olabilir. (bkz Şekil – 1)

Partition’lar kendi içinde sıralıdır. Partition 2 için 7. offset’deki veri 8. offset’den önce yazılmıştır. Ama Partition 1’deki 5. offset’deki veri ile Partition 2’deki 5. offset’deki veriyi kıyaslayamayız, hangisinin daha önce yazıldığını bilme şansımız yoktur.
Partition sayısı değiştirilmediği sürece Kafka, aynı key ile gönderilen her mesajın aynı partition’a düşeceğini garanti eder. Partition sayısı değiştirilirse bu garanti ortadan kalkar. Key ile veri göndermenin avantajı o veriye daha sonra aynı key ile sıralı bir şekilde erişmektir. Key ile gönderilmeyen her veri partition’lara rastgele bir şekilde dağıtılır.
Partition sayısı 1 seçilirse consumer verilere producer’ın ilettiği sırada erişir.
Kafka veriyi belli bir süre (varsayılan 1 hafta) muhafaza eder, daha sonra veri silinir. Ancak eski veri silinse de, partition’a yeni veriler gelince offset değeri kaldığı yerden devam eder, bir daha sıfıra dönmez.
2. Broker
Broker’lar Kafka Cluster’ı oluşturan sunuculardır. Her broker birer sayıdan oluşan ID ile tanımlıdır. Kafka Cluster oluşturulurken broker sayısı üç gibi bir sayıyla başlar, gereksinim arttıkça ilave edilir. Yüzün üstünde broker koşturan sistemler de vardır.
Bağlandığımız sunucu bootstrap broker adını alır. Bootstrap broker’a bağlanınca tüm broker’ların bilgisinin tutulduğu metadata sayesinde diğer broker’ların adreslerine erişilir. Tüm kafka cluster’a bağlanmak için sadece bootstrap broker’a bağlanmak yeterlidir.
Kafka dağıtık yapıda olduğu için tek bir broker topic’in tamamını alamaz. Her broker topic’in belli kısımlarını (partition) alır. Brokerlara partition’ların dağıtımı, eşit şekilde yapılmaya çalışılır.

Örneğin Şekil – 2’deki gibi 101, 102 ve 103 nolu üç broker’ımız olsun. Topic A üç partition’dan oluştuğu ve üç broker’ımız olduğu için her broker Topic A’ya ait birer partition’a sahip olur. Dikkatinizi çekerse partition’lar broker’lara sıralı bir şekilde dağıtılmıyor; 101 nolu broker’a 2. partition düşerken, 102’ye 0. partition, 103’e 1. partition düşebiliyor. Topic B’ye ait 2 partition olduğu için Broker 101 ve Broker 102’ye birer partition düşüyor, Broker 103 boşta kalıyor. (Yine rastgele şekilde Broker 103’e partition atansaydı Broker 102 de boşta kalabilirdi.) Topic C’ye ait 4 partition iki broker’a birer tane, bir broker’a iki tane olacak şekilde dağıtılır.
3. Producer
Producer belli bir topic’e mesaj gönderen Kafka bileşenidir. Publisher (yayımcı) pozisyonundadırlar. Veriyi topic’e key ile ve key’siz olmak üzere iki farklı yolla gönderebilirler.
Key ile gönderme durumunda ilk gönderilen mesaj hangi partition’a gittiyse aynı key ile gönderilen diğer mesajlar da aynı partition’a gönderilirler. Belli bir sınıftaki verimize consumer tarafından sıralı bir şekilde ulaşılmasını istiyorsak key ile gönderme tercih edilir.
Key’siz gönderme yönteminde Kafka iş yükünü dağıtmak için (load balancing) sıralı bir şekilde (round robin) gönderecektir. Bu durumda verimize sonradan sıralı bir şekilde ulaşamayız.
Producer ile mevcut olmayan bir topic’e veri göndermeye çalışırsak Kafka önce bu topiği oluşturur. Ancak bu konudaki best practice, topic’i gereksinimlere göre replication ve partition belirterek kendimizin oluşturmasıdır.
Producer veriyi Kafka’ya gönderirken bir teyit mekanizması (acknowledgement) mevcuttur. Bunun için üç opsiyon vardır:
- acks=0: producer broker’a veriyi gönderir ancak verinin ulaştığına dair broker’dan teyit gelmez. Çeşitli sebeplerle (Broker’ın offline olması, veri aktarımı sırasında bir hata oluşması vb.) veri kaybı olursa Producer’ın bundan haberi olmaz ve veriyi tekrar göndermez.
- acks=1: varsayılan değerdir. gönderilen veriler için leader konumdaki broker’dan teyit istenir ama replica’lardan teyit istenmez. leader’den cevap gelmezse producer veriyi göndermeyi yeniden dener (retry). Broker’da verinin diske yazılması onay mesajının gönderilmesinin ardından olur. Replica sunucular veriyi kopyalayamadan leader sunucunun offline olması gibi durumlarda veri kaybı olur.
- acks=all: Gönderilen veriler için leader’den ve replica’lardan teyit istenir. Bir miktar latency (gecikme) karşılığında daha fazla güvenlik sunar. Eğer yeteri kadar replica’mız varsa veri kaybı olmaz.
4. Consumer
Consumer, belli bir topic’den mesaj okuyan Kafka bileşenidir. Subscriber (abone) pozisyonundadırlar.
Partition’lardan paralel şekilde okuma yapar. Partition bazında sırayla okur. Partition’lar arası sırayla okuma yapamaz. İki partition’dan okuma yapıyorsa birinde 5. indexde diğerinde 20. indexde olabilir.
Consumer’lar verileri consumer group’lar halinde okur. Tek de olsa her consumer’ın bir grubu vardır. Grubu biz oluşturmazsak Kafka otomatik olarak oluşturur.
Gruptaki her consumer belli partition’lardan okuma yapar. Mesela topic’imizde 3 partition varsa:
- 3 consumer’ımız varsa her consumer birer partition’dan okuma yapar.
- 2 consumer’ımız varsa biri tek partition’dan, biri kalan iki partition’dan okuma yapar.
- 4 consumer’ımız varsa biri inaktif olur diğer üçü birer partition’dan okuma yapar. Gruptaki bir consumer’ın çökmesi gibi durumlara karşı bazen bu şekilde partition sayısından fazla consumer kullanıldığı olur.
5. Topic Replication
Dağıtık sistemlerin avantajlarından biri, sunuculardan biri offline olsa bile sistemin sürdürebilir durumda olmasıdır. Kafka’da da replica’lar sayesinde sistemin devam etmesi ve veri kaybının önüne geçilmesi sağlanır.
Replication ile topic’lerin her partition’u birden fazla sunucuda saklanır. Bu sunuculardan biri leader’dir, diğerleri ISR (in-sync replica) denilen kopyasıdır. ISR’ler veriyi senkronize eden, kopyasını tutan pasif sunuculardır, veri alışverişi leader üzerinden sağlanır. Leader ve ISR’ler zookeeper tarafından belirlenir. Replication’lar topic oluşturulurken replication-factor parametresi ile belirtilirler.
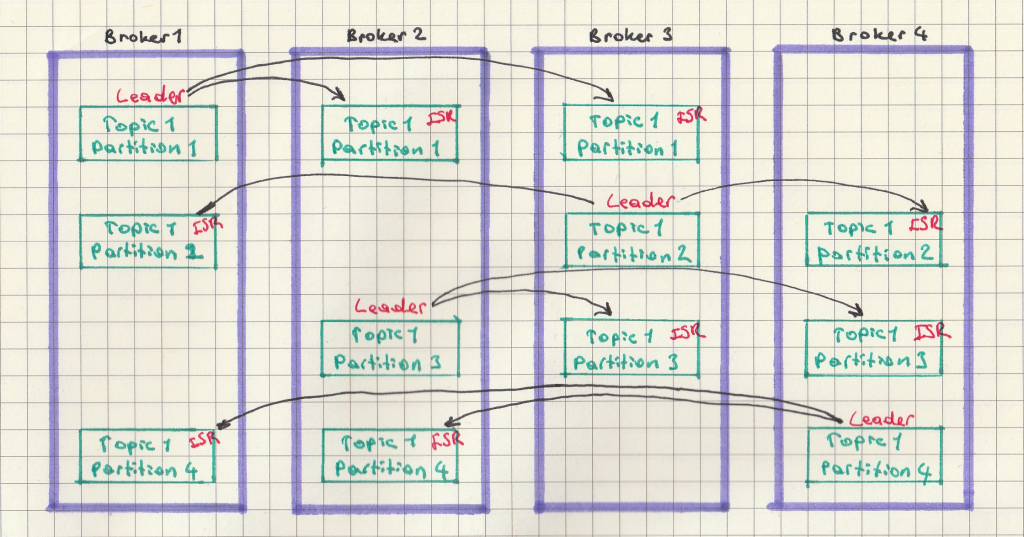
Şekil – 3’de replication factor’ü 3 ve partition sayısı 4 olan Topic 1 görünmektedir. Partition 1 için 1 nolu broker leader 2 ve 3 nolu broker’lar ISR pozisyonundadır. Partition 2 içinse 3 nolu broker leader 1 ve 4 nolu broker’lar ISR’dir. Bu şekilde her partition için lider ve replica’lar tüm broker’larda dağıtık olarak tutulurlar.
Her partition’un leader’i farklı broker’larda olabilir. Bir partition için aynı anda sadece bir tane leader vardır. Örneğin partition 1 için leader olan broker 1 offline olursa veya çökerse broker 2 veya broker 3 lider pozisyona geçecektir. Broker 1 ayağa kalkınca tekrar leader olacaktır.
Sonuç
Bu yazımda Apache Kafka’ya hızlıca giriş yapabilmek adına Kafka’yla ilgili temel kavramlardan bahsettim.
Apache Kafka’yla ilgili bir sonraki yazımda ileri seviye konfigürasyon ayarlarından ve güvenlikten bahsetmeyi planlıyorum. Kuşkusuz tüm bunlar Kafka’nın teorik kısmıdır. Uygulama kısmında, Kafka’yla komut satırında (CLI) kod yazılabileceği gibi, Java ve Python gibi yüksek seviyeli programlama dilleriyle de kod yazılabilmektedir. Nitekim gerçek hayat projelerinde Kafka genellikle bir programlama diliyle kullanılır. Sonraki yazılarımda Kafka’yla CLI, Java ve Python uygulamaları da yapmayı planlıyorum.
Apache Kafka’ya benzer şekilde farklı mesajlaşma kuyruğu platformları da vardır. Bunlara, açık kaynak olarak RabbitMQ ve ActiveMQ, AWS’nin bir bileşeni olarak da Kinesis örnek olarak verilebilir. Her platformun birbirinden ayrıldıkları noktalar ve avantajları/dezavantajları vardır. Ancak bu da farklı bir yazı konusudur.
Sonraki yazılarda görüşmek temennisiyle…
Hocam süper anlatım olmuş ellerinize sağlık. Herşeyi anlatmışsınız burada zaten. Teşekkürler.
Elinize saglik cok guzel bir yazi.
Gayet basit ve anlaşılır elinize sağlık