

![]()
Herkese merhabalar, önceki yazımda Apache Spark’a giriş yapmıştık. Bu sefer daha derinliklere inip Apache Spark’ın çalışma mimarisine ve cluster moduna göz atacağız.
1. Spark’ın Cluster Moduna Bakış
1.1. Cluster manager
Spark Cluster’ı bir çok cluster manager (cluster kaynak yöneticisi) ile birlikte çalışabilmektedir. Standalone Spark’ın kendine ait cluster yöneticisidir, varsayılan olarak gelir. Apache Spark Hadoop ve big data teknolojilerinde yaygın olarak kullanılan Mesos ve YARN ile son yılların gözde container teknolojisi olan Kubernetes’i de cluster yöneticisi olarak kullanabilmektedir.
Spark’ın hangi cluster yöneticisini kullandığının bir önemi yoktur. Hepsi cluster içinde haberleşebilmeye ve kaynak tahsisine katkı sağlar. Şekil-1’de Spark’ın cluster yapısı görülebilir.
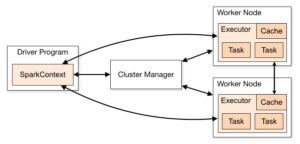
1.2. Driver Program ve SparkContext
Driver Program SparkContext’in oluşturulduğu main metodunun bulunduğu koddur. Bu kod Spark Shell’de olduğu gibi Python, Scala, Java gibi dillerle de yazılabilir. SparkContext master vazifesini gören nesnedir. SparkContext ile cluster’a erişilir, tasklar yönetilir ve kaynak yöneticisinden gerekli kaynaklar istenir.
1.3. Worker Node ve Executer
Diğer dağıtık uygulamalarda olduğu gibi Spark’ta da worker node’lar (işçi sunucular) hesapların yapıldığı, verinin depolandığı sunuculardır. Her worker node’da bir veya birden fazla executor bulunmaktadır. Executor’lar Spark kodlarının çalıştığı JVM’lerdir (Java Virtual Machine).
Cluster’a bağlanınca SparkContext uygulama kodlarını worker node’larda bulunan executor’lara gönderir. Daha sonra cluster yöneticisinden işlemler için kaynak tahsis edilmesini ister ve worker node’lara gerekli task’ları atayarak çalışma talimatı verir.
Uygulamaya tahsis edilen executor, program çalıştığı sürece ayakta kalır ve taskları çoklu thread’lar halinde çalıştırır. Her uygulama (SparkContext instance) kendi excecutor’una sahiptir. Bu sayede farklı uygulamalardaki taskların planlaması ve çalıştırılması birbirlerinden tamamiyle izole edilir. Ancak harici bir depolama birimine yazdırılmadığı sürece uygulamalar arasında veri alışverişi de olmamaktadır.
Driver program kullanım ömrü süresince executor’larla haberleşebilmelidir ve tercihen aynı yerel ağ içinde olmalıdır. Bu yüzden worker node’lardan adreslenebilmesi için gerekli konfigürasyon ayarları yapılmalıdır.
2. Transformation, Action Metodları ve Lazy Evaluation
2.1. Transformation ve Action Metodları
Spark’ta dağıtık veri üzerinde iki tip operasyon yapılabildiğini önceki yazımda bahsetmiştim. Bunlar transformation (dönüşüm) ve action (eylem) fonksiyonlarıdır.
Dönüşüm fonksiyonları adından da anlaşılacağı gibi bir Spark DataFrame’ini yeni bir DataFrame’e dönüştürür. Bu dönüşüm sırasında orijinal DataFrame aynı kalır, değişmez, sonuçlar yeni bir DataFrame olarak döner. Mesela filter() gibi bir dönüşüm fonksiyonu üzerinde filtreleme yapılan DataFrame’i değiştirmez, filtrelenmiş veriyi yeni bir DataFrame olarak döndürür.
2.2. Lazy Evaluation
Spark’ta dönüşüm fonksiyonlarının sonuçları hemen hesaplanmaz. Bu fonksiyonlar daha sonra çalıştırılmak üzere bir silsile halinde kaydedilir. Lazy Evaluation transformation operasyonlarının bir action metodu tarafından tetikleninceye kadar işleme konulmamasıdır. Bir action metodu çalıştırılacağı zaman o zamana kadar yazılan tüm transformation operasyonları da çalıştırılır. Bunu Spark’ın sorgu planında da gözlemlemek mümkündür, bir action metodu çalışmadıkça önceki dönüşüm fonksiyonları planda gözükmez. Şekil-2’de tüm transformation operasyonlarıyla yeni DataFrame’lerin yaratıldığı ve ancak bir action metodu çalıştığı zaman nihai haliyle kaydedilebildiği gösterilmiştir.
Lazy Evaluation yönetebilirliği artırır. Kod sadece gerekli zamanlarda çalıştığı için driver ve cluster arasındaki veri alışverişini azaltarak hıza katkı sağlar ve karmaşıklığı azaltır. Dönüşüm fonksiyonlarının bir dizi halinde çalıştırılması ve DataFrame’lerin değişmemesi, hata alınması halinde kodu verinin orijinal haliyle en baştan çalıştırmanıza imkan vererek hata toleransına ve esnekliğe katkı sağlar.
2.3. Narrow ve Wide Transformation
Transformation operasyonları narrow ve wide transformation olarak ikiye ayrılır.
Tek bir partition üzerinde işlem yapıp sonuç yine tek bir partition halinde veriliyorsa buna narrow transformation denir. Mesela filter() metodu bir narrow operasyondur, her partition’da bulunan veriler üzerinde ayrı ayrı filtreleme yapılır, en son sonuçlar birleştirilir. Bir shuffle işlemi yapılmaz.
Diğer partition’lardaki verilerin de okunduğu ve birleştirildiği yani shuffle işleminin yapıldığı dönüşümler ise wide transformation olarak adlandırılır. Mesela DataFrame üzerinde orderBy ile bir sıralama yapabilmek için sadece o partition’da bulunan verilere değil, tüm partition’lardaki verilere ihtiyaç vardır.
Shuffle’ın maliyetinden kaçındığı için narrow dönüşümler daha hızlıdır.
3. Spark Uygulamalarının Çalışma Adımları
Spark sorgu hesaplamalarını DAG (Directed Acyclic Graph) olarak oluşturur. DAG iş akışlarını ve bunların birbirlerine olan bağımlılıklarını göstermek için bilgisayar bilimlerinde yaygın olarak kullanılan bir kavramdır. Büyük veri dünyasında da bir çok teknolojide (Airflow, Tez, Presto vb.) kullanılır.
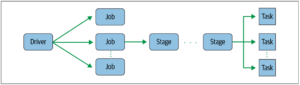
Driver tüm transformation ve action operasyonlarını alır ve bunları hesaplamaların ve dönüşümlerin olduğu DAG adımlarına dönüştürür. DAG aşamasında task ve stage’lerden oluşan iş akışını oluşturur.
Yazılan uygulama driver tarafından bir veya birden fazla Spark Job’una dönüştürülür. Job’lar action metotları tarafından tetiklenirler.
Her Job bir veya birden fazla Stage’den oluşur. Stage’ler uygulanacak olan operasyonlara göre hiyerarşik bir sırada oluşturulur.
Stage’ler de task’lara bölünürler. Task executor’larda çalıştırılan en temel birimdir. Her task verinin tek bir partition’unu işlemesi için executor’un tek bir çekirdeğine (core) atanır. Her task’ın belli çekirdeklere atanması ve her task’ın verinin belli partition’larını işlemesi Spark’ın paralel işlem gücünü oluşturur.
4. Spark Web UI
Her SparkContext başlatıldığında default olarak 4040 portunda kullanıcı arayüzü başlatılır. Birden fazla SparkContext başlatıldıysa kullanıcı arayüzü ardışık portlarda (4041, 4042…) başlatılır. Örneğin Spark’ı local’inizde çalıştırıyorsanız web arayüzüne tarayıcınızda http://<localhost>:4040 adresinden erişebilirsiniz.
Web UI ile Spark uygulamalarının job’lara, stage’lere ve task’lara ayrıştırılması izlenenebilir ve denetlenebilir. Web UI ile izlenebilecek belli başlı işlemler aşağıdaki gibidir:
- Çalıştırılmış (veya o an çalışan) stage ve task’ların listesi, zamanlayıcı’da gösterimi, DAG gösterimi
- RDD boyutlarının ve bellek kullanımının özeti
- Spark’ta kullanılan ortamlarla (Java home, Java version, Scala version vb.) ilgili bilgi
- Çalışan executor’larla ilgili bilgi
- Tüm çalışan SQL’lerin listesi, adım adım gösterimi
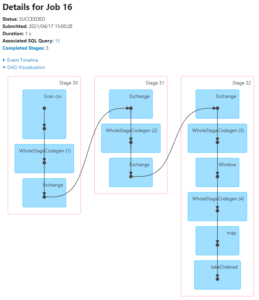
Spark’ın web arayüzünden alınmış bir Job’un DAG görseli ve Task’ların zaman çizelgesi üzerinde ayrıntılı gösterimi Şekil-4 ve Şekil-5’de gösterilmektedir.

Bir sonraki yazımda bir Kaggle verisi üzerinde Spark uygulaması yapmayı planlıyorum. Görüşmek üzere.
Kaynaklar
- https://spark.apache.org/docs/latest/
- Learning Spark – Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee – O’reilly 2020
Merhaba spark üzerinde büyük ölçekli veriler nasıl işlenir? Örneğin 1TB veri kümesi gibi
Merhabalar. Spark dağıtık yapısından dolayı büyük ölçekli verileri kolaylıkla işleyebilir. Sparkta veriler RDD’ler (dağıtılmış veri setleri) halinde tutulur. RDD’ler de partition’lar halinde cluster üzerindeki worker node’lara dağıtılır. Veriler öncelikle node’lar üzerindeki belleklerde (ram) işlenir ancak belleğin yeterli olmadığı durumlarda disk de kullanılabilir.