
Merhaba, bu yazımızda, özellikle sanal...


Yeniden merhaba! Hemen hemen her...

Herkese merhaba! Bugünkü yazımızda yine...

Merhaba, bu yazıda Airflow EmailOperator'ü...

Bu yazımda sizlere Google’ın yakın...

Merhabalar! Bu yazımda derin öğrenme (deep...

Daha önceki SSIS (SQL Server...

Merhabalar. Bu yazımızda Apache Flink...

Merhabalar. Apache Spark Structured Streaming...

Herkese merhabalar, MXNet ile derin...

Merhabalar! Uzun bir aradan sonra...

En sık kullanılan boosting algoritmalarının...

Herkese merhaba, Serinin ilk bölümünde...

Bu uygulama yazısında, Kaggle’dan alınan...

Catboost, Yandex şirketi tarafından geliştirilmiş...

Merhabalar, önceki yazımda Apache Kafka'ya...

Herkese merhabalar. C++ ile görüntü...

Makine Öğrenmesi dünyasının “Merhaba Dünya”...
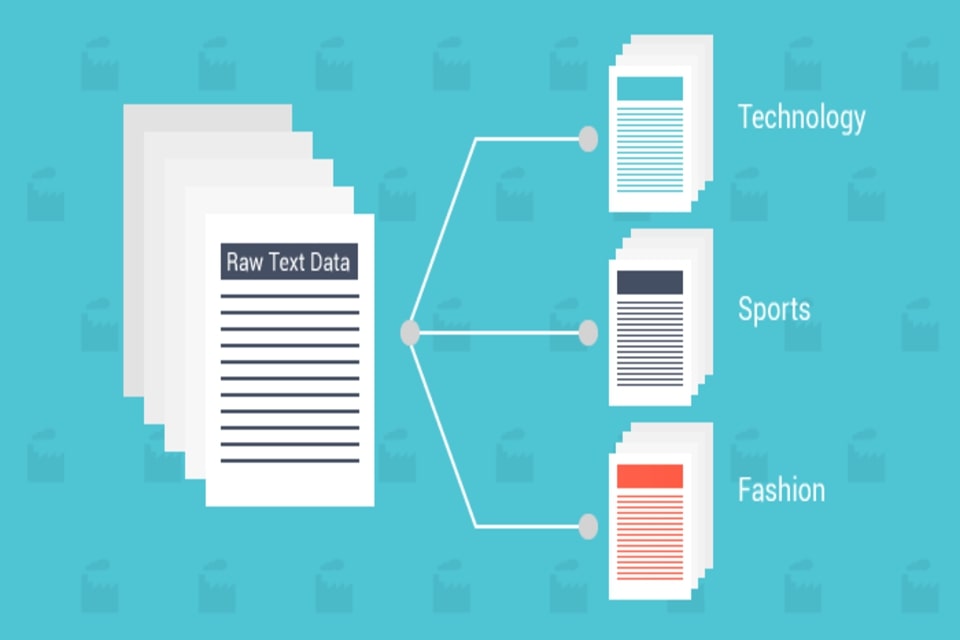
Merhaba VBO okuyucuları, bugün size...
Herkese merhabalar. Serimizin 3. bölümüne...