

Herkese merhaba!
Bugünkü yazımızda yine keyifli bir konuya değineceğiz. Diyelim ki veri tabanımızdaki değişiklikleri yakalamak ve başka bir sunucuya/buluta kesintisiz şekilde taşımak istiyoruz veya analiz/raporlama yapmak için gerçek zamanlı veri akışı sağlamak istiyoruz. Peki bunu nasıl gerçekleştirebiliriz? Gelin cevaplamak için hem veri değişikliklerinin yakalanması (Change Data Capture) işlemini hem de bunun için özelleşmiş bir araç olan Debezium‘u tanıyalım ve örnek bir uygulama ile MySQL veri tabanında bu işlemi gözlemleyelim😊
Veri değişikliklerinin yakalanması (Change Data Capture) nedir?
CDC, organizasyonların veri tabanı değişikliklerini otomatik olarak tanımlamasını ve yakalamasını sağlayan bir işlemdir. Bir veri tabanı olayı meydana gelir gelmez verileri sürekli olarak yakalayıp işleyerek gerçek zamanlı veri hareketleri sağlar. CDC işlemini gerçekleştirmenin farklı yöntemleri mevcuttur, ancak temelde aşağıdaki iki kategoriye ayırabiliriz:
- Log-based (Veri tabanı işlem loglarının takibi ile)
- Query-based (Trigger, Timestamp, Snapshot ile)
Yaygın ve etkili kullanım veri tabanı işlem loglarının kullanılmasıdır. Diğer yöntemler veri tabanına ek bir yük getirirken (örneğin “timestamp” yönteminde düzenli bir sorgu gerekmesi gibi), mevcut işlem loglarının okunmasında böyle bir durum yoktur.
Debezium nedir ve CDC işleminde nerede konumlanmaktadır?
En yaygın kullanımı temel alındığında, Debezium Kafka üzerine inşa edilmiş ve bir grup Kafka Connect uyumlu konnektör sağlayan bir araçtır. Mevcut veri tabanlarınızdaki bilgileri olay akışlarına dönüştürerek uygulamaların veri tabanlarındaki satır düzeyindeki değişiklikleri algılamasını ve bunlara anında yanıt vermesini sağlar. Bunun için, Debezium konnektörlerinin Kafka Connect kümesinde bulunması gerekir.
Kafka Connect’e de buradaki önemli rolü gereği kısaca değinecek olursak, Apache Kafka ve diğer sistemler arasında ölçeklenebilir ve güvenilir bir şekilde veri akışı sağlayan, Kafka’ya bağımlı bir araçtır. REST API arayüzü aracılığıyla konnektörleri Kafka Connect kümesine kolayca tanımlamak ve yönetmek mümkündür.

Debezium, Cassandra, Db2, MongoDB, MySQL, Oracle Database, Postgresql, SQL Server, Vitess veri tabanları için konnektör sunmaktadır. Bunlara ek olarak, özel Java uygulamalarında gömülü bir kütüphane veya tamamen bağımsız bir sunucu olarak kullanılabilmektedir.
Hazırsak uygulamaya başlayalım! 👇
Debezium MySQL Connector ile uygulama örneği
Hepimiz biliyoruz ki bir konuyu kavramanın en iyi yolu o konu hakkında pratik yapmaktır. Şimdi biz de bir uygulama ile yukarıda konuştuklarımız nasıl gerçekleşiyor bir görelim.
(Not: Örnek çalışmada CentOS7 kullanılmıştır, işlemler terminalde gerçekleştirilmiştir.)

- Yukarıdaki şemada görülen servislerimizi çalıştırmak için Debezium’un dokümanlarında tanımladığı adımlara uygun olarak sunduğu docker-compose-mysql.yaml dosyasını kullanalım. Burada önemli noktalardan biri “connect” için tanımlanan ortam değişkenleridir. Bu değişkenlere Debezium ihtiyaç duymaktadır. (Değişkenlerin açıklamaları için docker hub’da debezium/connect-base‘i ziyaret edebilirsiniz.)
version: '2'
services:
zookeeper:
image: quay.io/debezium/zookeeper:2.0
ports:
- 2181:2181
- 2888:2888
- 3888:3888
kafka:
image: quay.io/debezium/kafka:2.0
ports:
- 9092:9092
links:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
mysql:
image: quay.io/debezium/example-mysql:2.0
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=debezium
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
connect:
image: quay.io/debezium/connect:2.0
ports:
- 8083:8083
links:
- kafka
- mysql
environment:
# Debezium image needs the topics below (and more for advanced settings)
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1 # group id of kafka connect cluster
- CONFIG_STORAGE_TOPIC=my_connect_configs # store connector configurations.
- OFFSET_STORAGE_TOPIC=my_connect_offsets # store connector offsets.
- STATUS_STORAGE_TOPIC=my_connect_statuses # store connector status.
- Servislerimizi çalıştıralım ve durumlarını kontrol edelim.
docker-compose -f docker-compose-mysql.yaml up -d
docker-compose -f docker-compose-mysql.yaml ps

- Root kullanıcı ile MySQL veri tabanına bağlanalım ve mevcut kullanıcıları görüntüleyelim. Aşağıdaki görselde görülen mysqluser, konteyner oluştururken tanımlanan kullanıcıdır. Biz daha sonra debezium kullanıcısı ile işlemlere devam edeceğiz.
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -u root -pdebezium'
SELECT user,host FROM mysql.user;
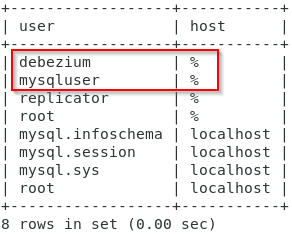
- Kullandığımız MySQL docker imajında yine mevcut veri tabanları bulunmaktadır. Biz “dataops” isminde yeni bir tane veri tabanı oluşturup, debezium kullanıcısına yetki tanımlayalım. Veri tabanlarını listeleyelim.
CREATE DATABASE dataops;
GRANT ALL ON dataops.* TO 'debezium'@'%';
FLUSH PRIVILEGES;
SHOW databases;

- Ctrl+D ile root kullanıcısından çıkıp, debezium kullanıcısı ile bağlanalım ve “example” isimli bir tablo oluşturalım. Tablolarımızı listeleyelim.
docker-compose -f docker-compose-mysql.yaml exec mysql bash -c 'mysql -u debezium -pdbz'
CREATE TABLE dataops.example(
customerId int,
customerFName varchar(255),
customerLName varchar(255),
customerCity varchar(255)
);
USE dataops;
SHOW tables;

Evet artık veri tabanımız ve tablomuz hazır. Kafka ve Kafka Connect ile ilgili adımlarımıza geçelim.
- Kafka Connect’e konnektör tanımlamak için bilgilerimizi bir json dosyasında tanımlamamız gerekiyor. Bunun için yine Debezium bir kaynak sunuyor. Biz de bunun üzerinden küçük değişiklikler yaparak json dosyamızı aşağıdaki şekilde ayarlayalım ve kısaca bir kaç konfigürasyon ayarını birlikte tanıyalım. (Tüm konfigürasyon ayarları için Debezium’un web sitesinden inceleme yapmanız faydalı olacaktır.)
- name : Konnektörün spesifik adı. Biz burada yeni bir isim verdik.
- topic.prefix : MySQL sunucusu veya kümesi için konu öneki.
- database.include.list : Belirtilen sunucu tarafından barındırılan veri tabanlarının listesi. Yeni oluşturduğumuz veri tabanını burada belirttik. (Değişimi takip edilecek veri tabanları buraya dahil edilecek)
{
"name": "dataops-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"topic.prefix": "dbserver1",
"database.server.id": "184054",
"database.include.list": "dataops",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "schema-changes.dataops"
}
}
- Terminalde yeni bir sekme açıp konnektör bilgilerimizi Kafka Connect’e iletelim. Şekil-7’de görüleceği şekilde konnektörümüz oluşturuldu.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @register-mysql.json

- Kafka topic listesine bir bakalım, dbserver1 ön eki ile topic oluştuysa artık dinlemeye geçebiliriz.
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-topics.sh \ --bootstrap-server kafka:9092 \ --list

- Yukarıda topicleri gördüğümüze göre, yeni bir terminal daha açalım ve topic olarak dbserver1.dataops.example’ı dinleyecek bir kafka-console-consumer oluşturalım. Ve bundan sonra artık pür dikkat MySQL veri tabanımızdaki değişiklikleri bu terminalden takip ediyor olacağız. Harika👌
docker-compose -f docker-compose-mysql.yaml exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.dataops.example
Peki, değişiklik yapmaya hazır mıyız?😊
- Önce MySQL in aktif olduğu terminalde birkaç veri/kayıt ekleme (insert) işlemi yapalım.
INSERT INTO example VALUES (1,"Richard","Hernandez","Brownsville"),\ (2,"Mary","Barrett","Littleton"),\ (3,"Ann","Smith","Caguas"),\ (4,"Mary","Jones","San Marcos"),\ (5,"Robert","Hudson","Caguas");
- Ve kafka-console-consumer’ın aktif olduğu terminale gidip neler olduğuna bakalım.👀 Aşağıda görebileceğimiz gibi, değişikliğe ait mesaj key-value olacak şekilde consumer tarafından alındı. Eklediğimiz 5 kayıt için de mesaj geldiğini göreceksinizdir.

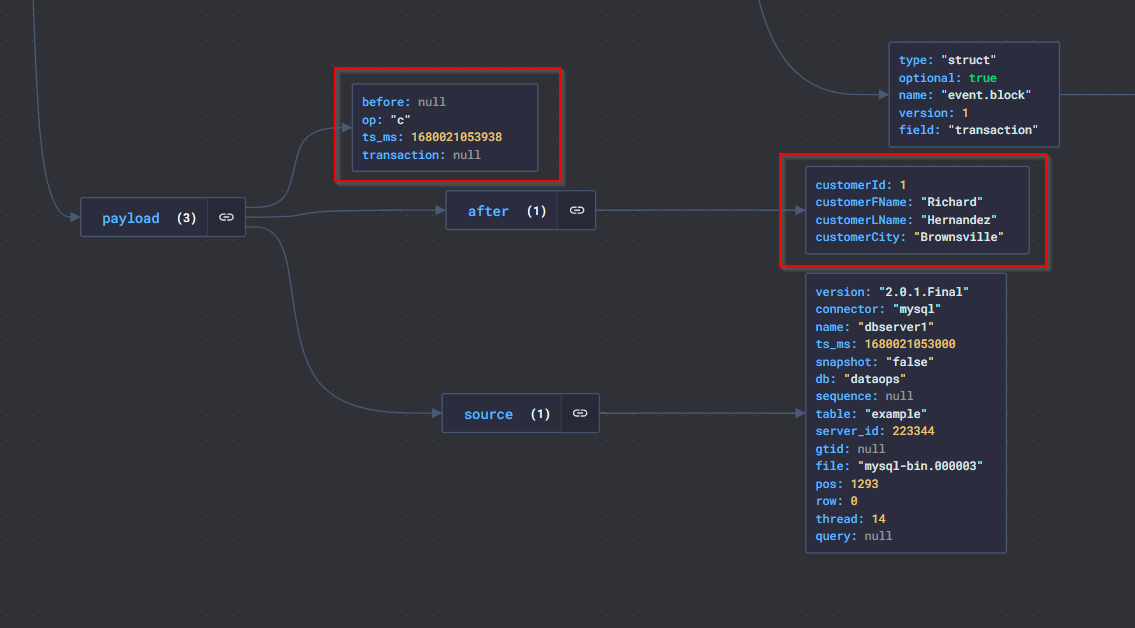
- JSON Crack ile yukarıdaki mesajı (value) bir inceleyelim. Burada bizi asıl ilgilendiren payload’un altındaki bilgilerdir. Şekil-10’da görebileceğimiz gibi before-after olacak şekilde veri tabanındaki değişikliği yakalamış olduk💕.
- before : Kaydın mevcut durumu
- after : Kaydın değişiklikten sonraki durumu
- op : Yapılan işlemin çeşidi (c: insert, u: update, d: delete)
- ts_ms : Değişikliğe ait zaman bilgisi
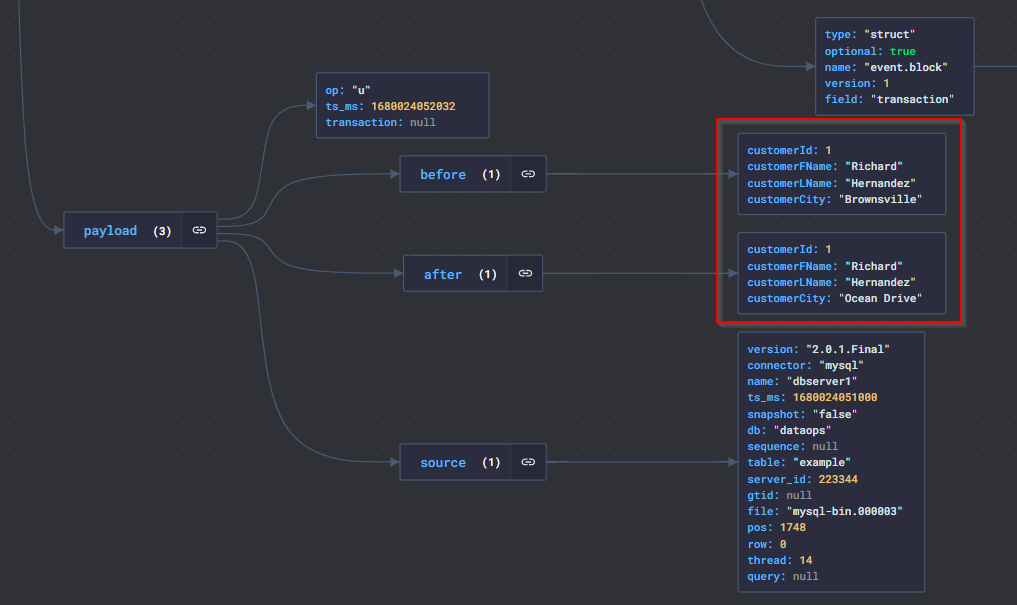
- Veriyi güncelleme (update) işlemi deneyelim, örneğin 1 numaralı müşterimizin il bilgisi değişmiş olsun.
UPDATE example SET customerCity = 'Ocean Drive' WHERE customerId = 1;
- Kafka-console-consumer’a düşen son mesajı yine incelediğimizde güncelleme işleminin before-after şeklinde yansıdığını görebiliriz.
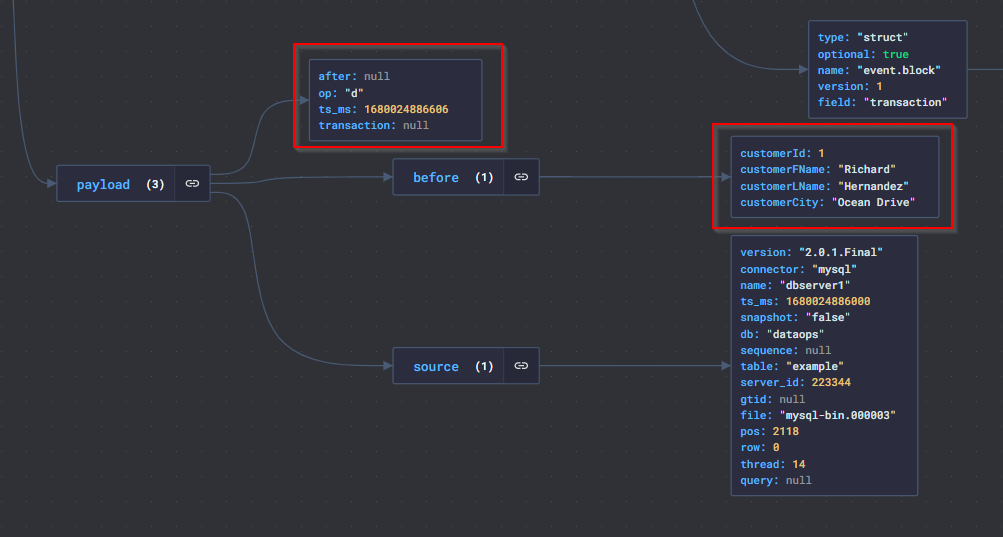
- Son olarak bir de silme (delete) işlemi yapalım. Burada dikkat etmemiz gereken konu şu, bir kayıt silindiğinde aynı “key”‘e sahip iki adet mesaj geliyor ve ikinci mesajın “value” kısmı “null” değerine sahip oluyor. Bu kayıt Kafka için bir belirteç görevi görüyor. (Bu anahtara sahip verilerin “log compaction” tarafından silinebileceği anlamına geliyor)
DELETE FROM example WHERE customerId = 1;
Yazımızın sonuna gelirken, Kafka’ya ve CDC konusunda gerçekten etkili bulduğum Debezium’a hayranlığımı buradan da dile getirmek istiyorum. Yukarıda birlikte de gördüğümüz gibi, bu araçlar sayesinde veri tabanındaki değişiklikleri yakalayıp önceki-sonraki durumlarını ve gerekli olabilecek diğer meta verileri eş zamanlı olacak şekilde almış olduk. Tabi bu özelliği ne şekilde kullanacağımız artık bizim iş ihtiyacımıza bağlı olarak değişecektir.
Umarım siz de bu uygulamadan benim kadar keyif almışsınızdır. Yeni paylaşımlarda görüşmek üzere.✌️
Kaynaklar:
https://www.qlik.com/us/change-data-capture/cdc-change-data-capture
https://debezium.io/documentation/reference/stable/tutorial.html
https://github.com/debezium/debezium-examples/tree/main/tutorial
https://kafka.apache.org/documentation.html#connect
https://debezium.io/documentation/reference/stable/connectors/mysql.html