
![]()
Bu yazıda son dönemlerde sık karşılaştığımız konulardan biri olan ve biz fark etmesek de yaşantımızın bir parçası haline gelmiş makine öğrenmesinden bahsedeceğim.
Makine öğrenmesinden bahsedildiğinde tam olarak ne olduğunu anlayamıyor musunuz? Gelin birlikte öğrenelim ve kafamızdaki soru işaretlerine bir son verelim.
Makine Öğrenmesi (Machine Learning) Nedir?
Makine Öğrenmesi, matematiksel ve istatistiksel işlemler ile veriler üzerinden çıkarımlar yaparak tahminlerde bulunan sistemlerin bilgisayarlar ile modellemesidir.
Makine Nedir?
Makine, bilgisayarların algılayıcı verisi ya da veritabanları gibi veri türlerine dayalı öğrenimini olanaklı kılan algoritmalardır. Algoritmalar, makine öğrenimine güç veren motorlardır.
Temel kavramlar
• Bağımlı değişken: Makine öğrenmesi probleminde tahmin etmek için hedeflediğimiz ana değişkendir. (Araç fiyatı ve benzeri)
• Bağımsız değişken: Bağımlı değişkeni tahmin etmemize yardımcı olan değişkendir. (Vites türü, marka ve benzeri)
• Aşırı Öğrenme (Overfitting): Veri setinin ezberlenmeye yakın çok iyi öğrenilmiş olmasına rağmen yeni gördüğü veri setinde tahmin yapmak istendiğinde hata yapması durumudur.
• Underfitting: Aşırı öğrenmenin tam tersidir. Bu durumda da veri setimizdeki önemli özellikleri yakalayamayıp gerekli öğrenmeyi yapamamamız durumudur.
Makine Öğrenmesi Türleri
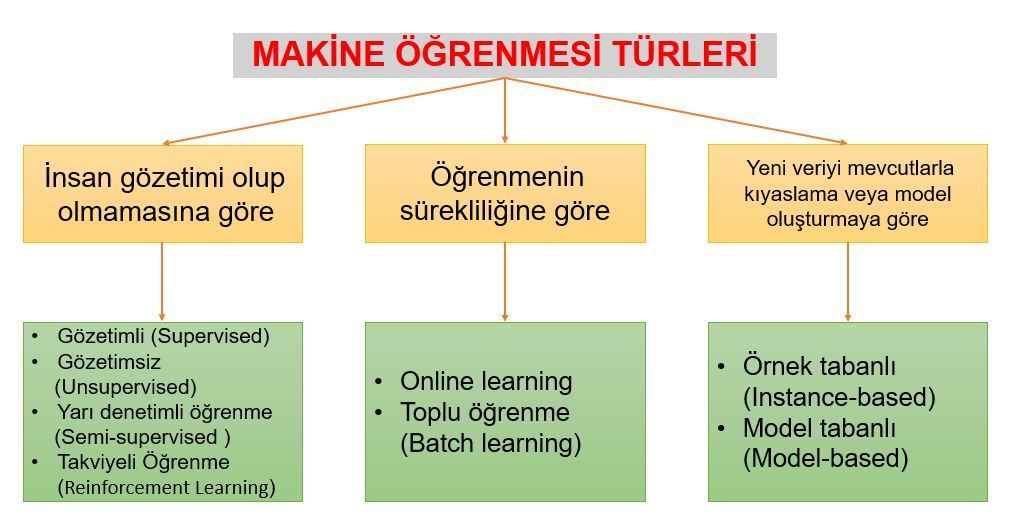
1. İnsan Gözetimi Olup Olmamasına Göre Öğrenme Türleri
1.1. Denetimli (Gözetimli) Öğrenme (Supervised Learning)
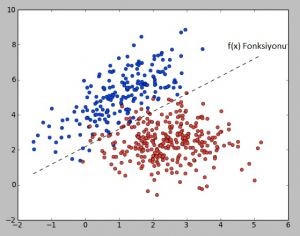
Verileri ve o verilerden çıkan sonuçları makineye tekrar baştan vererek bu bilgilerden bir fonksiyon çıkartılmasını sağlamaktadır. Böylece makine veriler arasındaki ilişkiyi öğrenmektedir.
Bu tanımı bir örnekle pekiştirelim. Ikea’dan bir mobilya aldığınızı düşünün. Almış olduğunuz mobilya kutusundan bir sürü parça çıkacaktır. Bu parçalar bizim verilerimiz olsun. Bu parçalar ayrı ayrı durumdayken bizim için hiçbir şey ifade etmeyecektir. Yine aynı kutu içerisinden çıkan kâğıt parçasıyla mobilyayı sıfırdan yapmamız gerekmektedir. Makine öğrenmesinde de makineye parçaları yani verileri nasıl birleştireceğini söylemeyiz. Ona parçaları yani verileri verir, kâğıt parçasını da eline tutuştur mobilyayı tamamlamasını bekleriz.
Bu durum denetimli makine öğrenmesine bir örnektir çünkü makineye hem verileri hem de o verilerle neler yapabileceğini öğretiyoruz. Bunun için bir algoritma yazıyoruz. Her parçayı nasıl birleştireceğini anlatmaktan çok daha kısa bir kodla işi bitiriyoruz. İşin güzel tarafı da makinenin aynı algoritmayla farklı mobilya türleri üretebiliyor olması. Makine öğrenmesinin bu özelliği işimizi çok kolaylaştıracak olan bir kısmıdır.
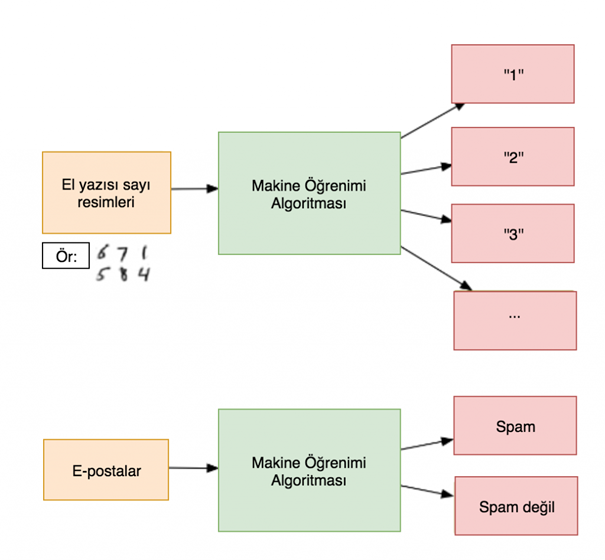
Yukarıdaki şemada da denetimli öğrenmeye bir örnek verilmiştir. Aynı algoritmayı kullanarak elle yazılmış sayıları tanımlamada kullanılabileceği gibi, bir satır kod değiştirmeden, e-postaları spam veya spam-değil olarak iki gruba ayırmadan da kullanabilir. Algoritma aynı algoritmadır ama farklı veri ile eğitildiği için farklı bir sınıflandırma mantığı oluşturur.
1.1.1. Denetimli Öğrenme’de Kullanılan Metotlar
1.1.1.1. Regresyon
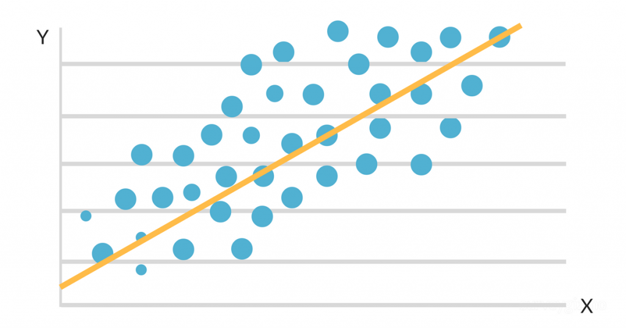
Regresyon analizinde, iki ya da daha çok değişken yer aldığı istatiksel modellerde, genellikle neden-sonuç ilişkileri araştırılır. Yani değişkenlerden biri ya da birkaçının, diğer bir ya da birkaç değişkeni ne ölçüde etkilediği incelenir. Eğer değişkenler arasında ilişki varsa, ilişkinin derecesi matematiksel bir fonksiyon olarak ortaya konur. Bu fonksiyona regresyon fonksiyonu denir.
Regresyon analizi; bağımsız değişkenler (X1,X2…..Xn ) ile bağımlı değişken (Y)’deki değişimi açıklamayı hedefler. Örneğin; bir öğrencinin başarısı ve çalışma saati arasındaki ilişki araştırıldığında; bağımlı değişken Y olarak tanımlanır ve çalışma saati bağımsız değişkeni X olarak tanımlanır.
Regresyon modeli iki ya da daha fazla değişken arasındaki ilişkinin fonksiyonel şeklini göstermekle kalmaz, değişkenlerden birinin değeri bilindiğinde diğeri hakkında tahmin yapılmasını da sağlar.
Aralarında ilişki araştırılması istenen değişkenler sayılabilir veya ölçülebilir nitelikte olabilir. Üzerinde durulan değişkenlerden bağımlı değişken y, bağımsız değişken x ise, y=f(x) şeklindeki fonksiyona regresyon modeli denir. f(x) fonksiyonu farklı şekiller alabilir.
1.1.1.1.1. Lineer Regresyon
Lineer regresyon, bağımlı değişkenin sürekli olduğu durumlarda tercih edilir. Değişkenler arasındaki ilişki lineer bir çıktı verir. Lineer regresyon modeli aykırı değerlere çok hassastır. Veri havuzu içerisinde ortalamadan fazlaca sapan değerler lineer regresyon eğrisinin görünümünü bütünüyle değiştirebilir. Bu yüksek hassasiyet incelenen duruma göre istenen veya istenmeyen bir özellik olabilir.
1.1.1.2. Sınıflandırma
Makine öğrenmesi ve istatistikte; sınıflandırma, bilgisayar programının verilen veri girişinden öğrendiği ve sonrasında yeni gözlemleri sınıflandırmak için bu öğrenmeyi kullandığı denetimli öğrenme yaklaşımıdır. Bu veri setleri sadece bi-class (kişinin erkek ya da kadın , bir e-postanın spam ya da spam olmadığını belirlemek gibi) ya da multi-class (Makine öğreniminde çok sınıflı sınıflandırma, örnekleri üç veya daha fazla sınıftan birinde sınıflandırma sorunudur) olabilir .
1.1.1.2.1. Lojistik Regresyon
Lojistik regresyon, bağımlı değişken çıktısının sadece iki olasılıklı sonuçlar (evet/hayır, 0/1, doğru/yanlış) verdiği durumlarda kullanılır. Bağımsız değişken davranışına göre bağımlı değişkende meydana gelen değişim net bir şekilde gözlenir. Özellikle sınıflandırma gerektiren problemlerde sıkça kullanılır.
Örneğin; makine öğrenmesini kullanan CRM yazılımları müşterilerin ilgi duydukları ürünler ile alım tercihleri arasındaki ilişkiyi kurarken lojistik regresyona başvurur. Güvenilirlik oranının yükseltilmesi için geniş bir veri örneği ile çalışmak lojistik regresyonda önemlidir. Modelin uygulandığı veri aralığının dar olması çıktının genellemeden uzak olmasına dolayısıyla kesinlikten uzaklaşmasına sebep olur.
1.1.1.2.2. Karar Ağacı/Şeması
Karar ağacı yöntemi, verileri sınıflandırmada kullanılan etkili yöntemlerden biridir. Kümeleme yönteminden farkı, denetimli makine öğrenmesi tarafından kullanılmasıdır. Yani elimizdeki verilerin etiketlenmiş olduğu durumlardaki ayrımlarını görmek için kullanıyoruz. Adından da anlaşılacağı üzere, veriler bir akış şeması halinde alt başlıklar veya ilişkili başlıklar olarak sınıflandırılır. Verileri yorumlamak ve veriler arası ilişki kurmak açısından avantajlı bir yöntemdir. Makine öğrenmesinde uygulandığı örneklerin arasında; karakter tanıma, kullanıcı davranışları belirleme, ses tanıma, hastalık teşhisi, kredi dolandırıcılığı tespiti gibi uygulamalar bulunur.
1.1.1.2.3. Rastlantısal Orman (Random Forest)
Karar ağacı algoritmasını hatırlarsak bir tane ağaç yapısı oluşturuyorduk. Daha sonra ağaç yapısı için bir kök ve değişkenlerin değerlerine göre dallar oluşturulup sonuca ulaşmaya çalışıyorduk. Elimizde olan veri setindeki değerleri rastgele olarak kullanarak, bu ağaçlardan n tane oluşturuyorsak buna rastgele orman algoritması deniyor. Yani rastgele değerlere göre oluşturulmuş dalları olan ağaçlar bütünüdür. Buna da haliyle orman deniyor. Hem sınıflandırma hem de regresyon için kullanılabilinir.
KNN (K En Yakın Komşu), Naive Bayes, Support Vector Machine, Yapay Sinir Ağları (Artificial Neural Networks), Convolutional Neural Networks, Recurrent Neural Networks vs. makine öğrenmesinde kullanılan birçok metot bulunmaktadır.
1.2. Denetimsiz (Gözetimsiz) Öğrenme (Unsupervised Learning)
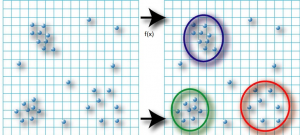
Denetimsiz öğrenme, modeli denetlemenize gerek olmayan bir makine öğrenme tekniğidir. Bunun yerine, modelin bilgileri keşfetmek için kendi başına çalışmasına izin vermeniz gerekir.
Denetimsiz öğrenme algoritmaları, denetimli öğrenmeye kıyasla daha karmaşık işleme görevleri gerçekleştirmenizi sağlar.
Yine Ikea örneğini hatırlayacak olursak bir girdi ve bir de çıktı vardı. Parçalar girdi, mobilya çıktıydı. Denetimsiz öğrenmede çıktı bulunmamaktadır. Parçalar vardır ama mobilya üretilmeyecektir. Yani elimizde sadece etiketsiz veri vardır.
Denetimsiz Öğrenmenin temel görevi verileri sınırlandırmaktır. Google fotoğraflardaki yüzler, hayvanlar ve bitkiler sınıflandırması denetimsiz öğrenmeye örnek gösterilebilir.
1.1.2. Denetimsiz Öğrenme’de Kullanılan Metotlar
1.1.2.1. Kümeleme Yöntemi
Kümeleme yöntemi, makine öğrenmesinin bir çeşidi olan gözetimsiz öğrenmede kullanılan bir istatistiksel yaklaşımdır. Gözetimsiz öğrenmede kullanılan etiketlenmemiş veriler kümeleme yöntemi ile gösterdikleri özelliklere göre sınıflandırılır. Elinizde bir veri havuzu olduğunu düşünelim, binlerce veri benzer özelliklerine göre kümelere ayrılır sonuç olarak verilerin birbirine yakınlığına bağlı olmak üzere elinizde belli sayıda veri kümesi oluşur.
1.1.2.2. Temel Bileşenler Analizi (Principal Component Analysis)
Temel Bileşenler Analizi, çok değişkenli bir veri seti içerisindeki bilgiyi daha az değişkenle ve minimum bilgi kaybıyla açıklamanın bir matematiksel tekniğidir. Başka bir tanımla PCA, çok sayıda birbiri ile ilişkili değişkenler içeren veri setinin boyutunu, veri seti içerisindeki veriyi koruyarak daha küçük boyuta indirgenmesini sağlayan bir dönüşüm tekniğidir. PCA, büyük boyutlu veri setlerindeki boyutsallığı azaltır. Teknik, boyut küçültme işleminde veri seti içerisindeki değişken sayısını azaltmayı hedefler. Dönüşüm sonrasında elde edilen değişkenler ilk değişkenlerin temel bileşenleri olarak adlandırılır. İlk temel bileşen olarak varyans değeri en büyük olan seçilir ve diğer temel bileşenler varyans değerleri azalacak şekilde sıralanır.
PCA’nın Özellikleri
- PCA, boyut azaltmada çok faydalı bir yöntemdir.
- PCA, çok boyutlu verileri yaklaşık olarak ve daha az boyutlu veriyle temsil eder.
- PCA, orijinal veriler için dik-olan-en-büyük-varyans-yönleri bulup orijinal verileri bu koordinat sisteminde gösterir.
- PCA, çok boyutlu verilerin görsel gösterilmesi ve incelenmesi için kullanılabilir.
- PCA, makine öğrenmesi olarak, verilerin boyutu azaltabilir–az değişen PCA özellikleri modelleme için önemsiz olabilir, bu şekilde modelleme ile ilgili hesaplama hızlandırabilir.
- PCA, veri sıkıştırma içinde kullanılabilir.
PCA’nın üç temel amacı vardır:
- Verilerin boyutunu azaltma
- Tahminleme yapma
- Veri setini, bazı analizler için görüntülemek
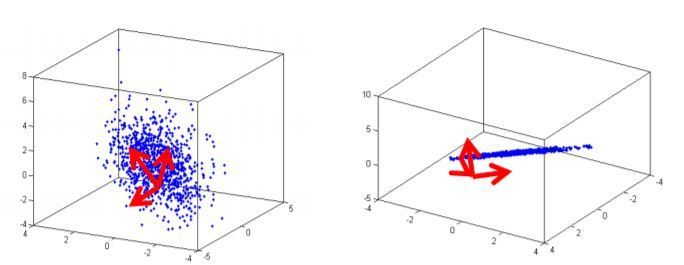
Çok boyutlu verilere doğru açıdan bakarak genellikle verideki ilişkiler açıklanabilir. PCA’nın amacı bu “doğru açıyı” bulmaktadır.
PCA kilit noktası, problemi çözmek üzere görsel inceleme için uygun bir “açı” yani uygun bir koordinat sistemi seçmektir. Uygun “açıdan” verilere bakmak, bu koordinat sistemi kullanarak verileri incelemek demektir.
PCA’nın Uygulanışı
- Birinci eksen olarak, verilerin en büyük değişiminde olan yön seçilir.
- İkinci eksen olarak, önceki birinci eksene dikey olan ve verilerin en büyük değişiminde olan yön seçilir.
- Üçüncü eksen olarak, önceki birinci ve ikinci eksene dikey olan ve kalan verilerin en büyük değişiminde olan yön seçilir.
- Böyle – her zaman yeni eksen olarak verilerindeki en büyük kalan değişimde olan yön seçilmektedir.
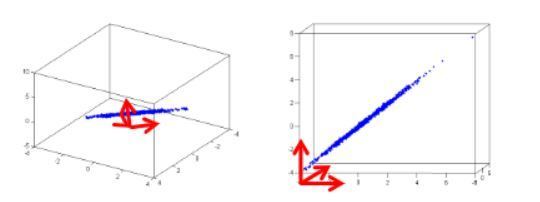
Yeni koordinat sisteminde verinin görüntüsü elde edilmiştir.
Özetle PCA, istatistiksel bir metottur. Bir veri setindeki örüntünün tanımlanmasında, veri setinin açıklanmasında, veri içerisindeki benzer ve farklı desenlerin tanımlanmasında kullanılabilir. PCA verinin sıkıştırılmasına boyut azaltarak imkan sağlamaktadır.
1.3. Yarı Denetimli Öğrenme (Semi-supervised Learning)
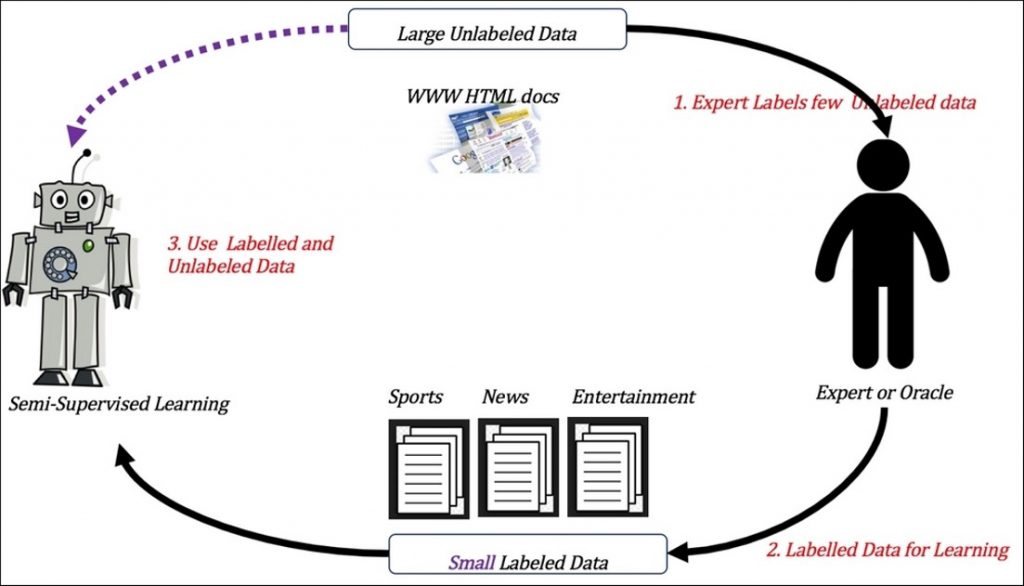
Yarı denetimli öğrenme, denetimli ve denetimsiz öğrenmenin arasında yer alır. Çok fazla etiketlenmemiş veri ile etiketlenmiş küçük boyutlu verinin birlikte kullanılmasından oluşmaktadır. Daha çok genetik sıralama, ağ sayfası sınıflandırmada kullanılmaktadır.
1.4. Takviyeli (Pekiştirmeli) Öğrenme (Reinforcement Learning)
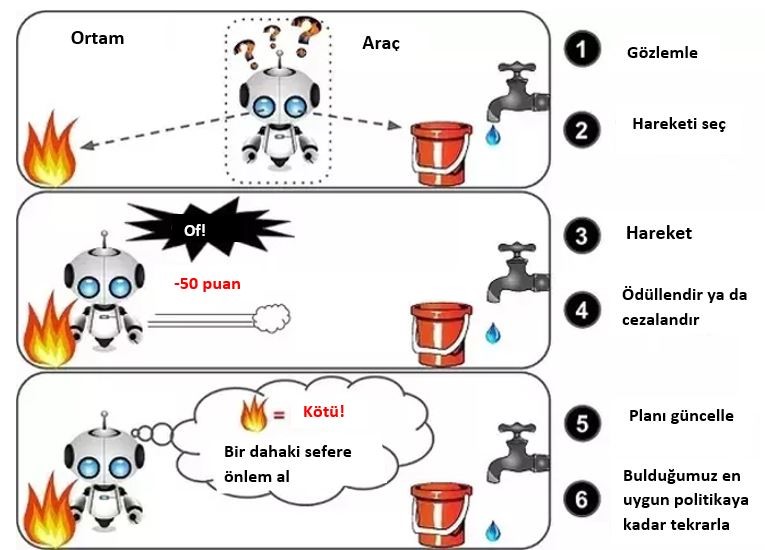
Takviyeli öğrenme denetimli-denetimsiz öğrenmeden farklıdır. Takviyeli öğrenmede, bir ödül-ceza sistemi bulunmaktadır. Burada makinenin amacı istenilen eyleme ulaşılan doğru yolu bulmaktır, doğru yola giderken yaptığı hatalardan çıkarımlar yapar ve belli bir ödül-ceza temeli üzerinde çalışır. Ardından çıkarımlarından en az hata ile doğru eylemi bulmaya çalışır.
Takviyeli öğrenmede asıl amaç çevreyle etkileşime girerek çevreden geri bildirim alıp ödülleri maksimuma çıkartarak hareket tarzı bulmasıdır.
Örneğin; bir bebeğin sıcak suya dokunup elinin yanması ve aynı sıcak suya elini sokmaktan çekinmesi takviyeli öğrenmedir. Bu durumda bebek çevreyle etkileşiminden negatif geri bildirim almıştır.
2. Öğrenmenin Sürekliliğine Göre Öğrenme Türleri
2.1. Toplu Öğrenme (Batch Learning) ve Tekli Öğrenme (Online Learning)

Toplu eğitimde eğitim kümesinin tamamı tek seferde ağa verilirken, tekil öğrenmede eğitim örnekleri birer birer ağa verilmektedir. Her iki yöntemin diğerine göre avantaj ve dezavantajları bulunmaktadır. Tekil eğitimin daha hızlı yakınsadığı, daha iyi lokal minimumları bulduğu, buna karşın birçok öğrenme algoritmasının sadece toplu eğitim için uygulanabildiği bilinmektedir. Toplu eğitim paralel hesaplama yapılabilirken, tekil eğitim
paralel hesaplama yapılamamaktadır.
Paralel hesaplama ya da Koşut hesaplama, aynı görevin, sonuçları daha hızlı elde etmek için çoklu işlemcilerde eş zamanlı olarak işletilmesidir. Bu fikir, problemlerin çözümünün ufak görev parçalarına bölünmesi ve bunların eş zamanlı olarak koordine edilmesine dayanır.
3. Yeni Veriyi Mevcutlarla Kıyaslama veya Model Oluşturmaya Göre Öğrenme Türleri
3.1. Örnek Tabanlı Öğrenme (Instance-Based Learning)
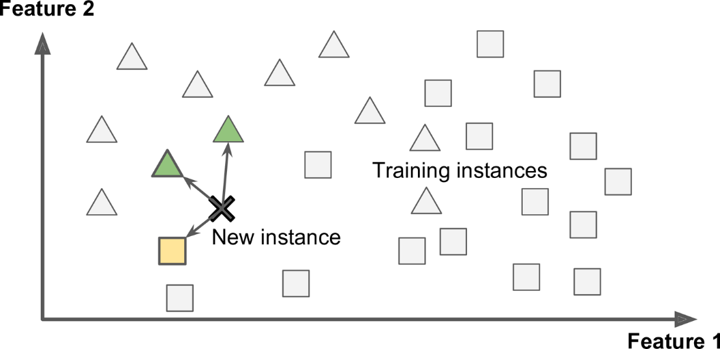
Bu öğrenme modelinde algoritma, yeni bir örnekle karşılaştığında hafızada saklanan eğitim verilerinden alınan örneklerle bu yeni örneği karşılaştırarak ona bir sınıf etiketi verir.
Uzaktan algılanmış görüntülerin sınıflandırılmasında yaygın olarak kullanılan örnek tabanlı sınıflandırıcılar, pikseller arasındaki hayali uzaklıkların ya da benzerliklerin belirlenmesi ile sınıflandırma işlemini gerçekleştirmektedir.
3.2. Model Tabanlı Öğrenme (Model-Based Learning)
Model gerçek dünyada (ör: robotlar) veya bilgisayarda (ör: oyunlar) eylem gerçekleştirir. Daha sonra ödülü olumlu ya da olumsuz olsun çevreden alırlar ve değer işlevlerini güncellerler.
Öğrenmeyi hızlandırma avantajına sahiptir, çünkü öğrenmeye devam etmek için çevrenin yanıt vermesini beklemenize veya çevreyi bir duruma sıfırlamaya gerek yoktur.
Makine Öğrenmesi Nerelerde Kullanılır?
- Büyük markaların tavsiye sistemleri
- e-postaların iyi kötü ayrıştırılması (istenmeyen e-postalar)
- Mesajlarda kelime ve cümlelerin tamamlanması
- İşverenlerin adayları tanımlaması ve nitelendirmesi
- Sahtekarlıkların tespit edilmesi ve hisse senedi fiyatlarını tahmin edilmesi.
- ERP/ERM (Kurumsal kaynak planlaması) uygulamaları: Varlık arızası ve bakımını tahmin etmek, kalite güvencesini geliştirmek ve üretim hattı performansını artırmak.
En kısa tanımıyla makine öğrenmesi nedir?
Özetleyecek olursak; makine öğrenmesi, kod yazmanıza gerek kalmadan veriler ile oluşturacağınız bir algoritmanın veriye dayanarak kendi mantığını oluşturması ve diğer işlemleri de aynı mantıkla yapmaya devam edebilmesi işlemidir.
Başka bir yazıda görüşmek dileğiyle hoşça kalın …
Kaynak
- https://gelecegiyazanlar.turkcell.com.tr/konu/makine-ogrenmesi
- https://www.oracle.com/tr/artificial-intelligence/what-is-machine-learning.html
- https://medium.com/@cerebro.tech
- https://peakup.org/
- https://github.com/erkansirin78/machine-learning-with-python/raw/master/presentations/01_ML_Genel_teori.pptx
- http://www.zafercomert.com/IcerikDetay.aspx?zcms=78