

![]()
Hedefli içerik ilgimizi çekebilecek ya da ilgilendiğimiz içeriklerdir. Örnek verecek olursak bir siteden aradığımız ürünü bulup aldığımızda daha sonrasında “o ürünü alan bu ürünü de inceledi“ gibi uyarı çıkmasının sebebi de yapay zeka uygulamalarıdır.
Yapay zekayı tek başlık altında ele almak yanlış olur. Makine öğrenimi (Machine learning), Derin öğrenme (Deep learning) gibi kavramlar yapay zekayı oluşturan kapsayıcı terimlerdir.
Örnek Uygulamalar
- Müşteri segmentasyonu
- Kanser hastalık teşhisi
- Şirketlerin gelir tahmini, yıl sonunda kazancının ne kadar olacağını tahmin etmesi
- Başvuru değerlendirme sistemleri
- Doğal afet gerçekleştirme olasılıkları etkileri
- Oyun sonuçların tahmin edilmesi
- Otonom araçlar
- Sürücüsüz ring araçları
- Nesne tanıma ve takip uygulamaları
- Sahte videolar
- Eski resimlerin canlandırılması
- Resimleri var olmayan kişiler
- Merdivenleri çıkan ve görevleri yerine getirmeye çalışan robotlar
Veri setlerinde bulunan verileri inceleyerek, bu veriler üzerinden ilgilendiğimiz konuyu ve bazı yapıları algoritmalar aracılığıyla öğrenebiliriz. Mesela bankacı olduğumuzu düşünelim. Bir kişi de kredi başvurusunda bulunsun. Biz, o kredi başvurusunda bulunan kişiye, kredi verilebilir ya da verilemez olduğuna karar verirken krediye başvuru yapan kişinin birçok özelliğine bakarız. Bu özellikler kredi alacak olan kişinin krediyi geri ödeyip ödeyemeyeceğini gösteren özelliklerdir. Bu özelliklere örnek verecek olursak; gelir durumu, varlık durumu, yaş, eğitim durumu, çalıştığı şirket, çocuk sayısı gibi özellikler olabilir. Ve sonunda bu özelliklere bakarak karar veririz. Yapay zeka ise birçok veri setlerini öğrenerek krediyi ödeyenlerin ve krediyi ödeyemeyenlerin farkını bulup tahmin etmeye çalışır. Yapay zeka sistemine değişken değerlerini verdiğimizde sistem bize geçmiş verilere bakarak, “bu kişi krediyi öder veya ödeyemez” diye geri dönüş yapar.
Veri uzmanları web, akıllı telefonlar, müşteriler, sensörler ve diğer kaynaklardan toplanan verileri analiz etmek üzere istatistik, bilgisayar bilimi ve iş bilgisi dahil olmak üzere bir dizi beceriyi bir araya getirir. Bu örneklerin meydana gelmesi için teorik altyapıyı sağlayan algoritmalara makine öğrenmesi algoritmaları denir. Ürünlerin oluşması ve hayatımıza girdiği haline ise yapay zeka denmiş olur. Yapay zekanın temelinde makine öğrenmesi, veri madenciliği, derin öğrenme ve büyük veri alanları barındırır.
Peki biz nasıl hayatta kalırız?
Hayatta kalmak için: Programlama, matematik, istatistik, veri analizi, veri bilimi, büyük veri, yapay zekâ, derin öğrenme, makine öğrenmesi, nesnelerin interneti, veri madenciliği hakkında bilgi sahibi olmamız gerekir. Yeni sorular sormak, araştırmak, problem çözmek ve kavramların mantıklarına odaklanmak önemlidir.
Algoritma genel anlamıyla, belli bir amacı yerine getirmek için gerçekleştirilen işlemler dizisidir. Yapay zeka, algoritmaları veri ile besler ve makine öğrenmesi algoritmaları kullanarak onlara öğrenme kabiliyeti kazandırırsak bizi bizden daha iyi tanır hale gelebilirler. Sosyal medya beğenileri bunda önemli rol oynar. Bizi bizden daha iyi tanımlayarak isteklerimizi ve eğilimlerimizi tahmin edebilir.[2]
Veri bilimi nedir?
Veri bilimi veriden anlamlı bilgi çıkarma ve verilerden değer elde etmek üzere bilimsel yöntemleri, süreçleri, algoritmaları ve sistemleri kullanan bir bilimdir. Elimizdeki veri kaynaklarından, veri analitiğini kullanarak bazı bilgiler çıkarıp ve bu bilgileri aksiyona çevirdiğimiz bilimdir. Veriden anlamlı bilgi çıkarma sürecini yöneten kişilere ise veri bilimci denir. Yani veri kaynakları var, bu verileri analitik düşünce becerimizle inceliyoruz, analiz ediyoruz ve bazı bilgiler çıkartıyoruz.[3]
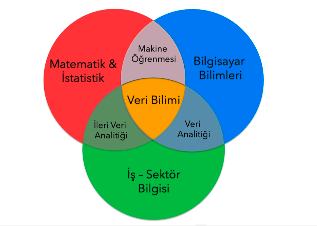
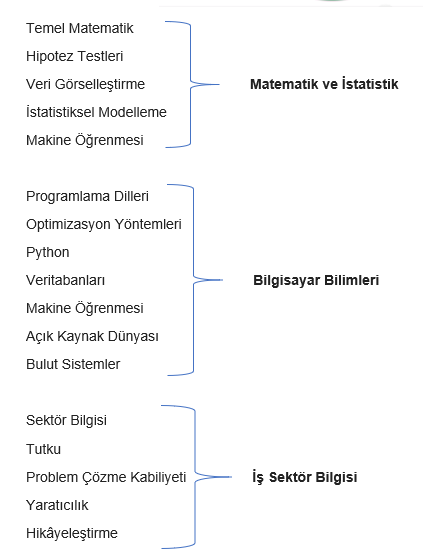
Veriden Faydalı Bilgi Çıkarmak Nasıl Gerçekleşir?
Betimleyici Analitik: “Ne olmuş?” sorusuna yanıt aranır. Veriyi betimlediğimizde mod, medyan, standart sapma veya görselleştirme teknikleriyle basit raporlar oluşturduğumuzda betimleyici analitik yapmış oluruz. Şirketin ilk üç ay ne kadar ürün sattığını gösteren çizelge yapmak buna örnek olarak verilebilir.
Teşhis Tanı Analitiği: “Neden, Neden olmuş, Nasıl olmuş?” sorularının yanıtını verir. Betimledikten sonra görmüş olduğumuz durumun neden olduğunu sorgular, yani teşhis tanı analitiği yapmış oluruz.
Tahminsel Veri Analitiği: “Ne olacak?” sorusuna yanıt verir. Geleceksel tahmin yapmak için kullanılır. Satışların ne olacağını tahmin etme örnek olarak verilebilir.
Yönergeli Analitik: “Nasıl olmalı, Ne olmalı?” sorularına yanıt verir. Olasılıkları tahmin ettikten sonra, başarıyı arttırmak için ne yapmalıyım diye soru gelirse, iş-aksiyon kararları alarak başarıyı arttırmaya çalışmaktır.
CRISP Nedir?
Bir veri bilimi projesine nereden başlanacağı, hangi adımların izlenmesi gerektiği, projenin aşamalarının çıktıları ve
proje süresince ölçülebilir adımları CRISP-DM olarak kısaltılan yöntemle yönetilebilmektedir.CRISP-DM modeli veri madenciliği için CROSS Endüstriler Arası Standart İşleme Süreci olarak tanımlanmaktadır. Cross-Industry Standard Process for Data Mining (CRISP-DM) olarak kısaltılmıştır. [4]
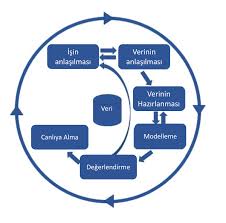
CRISP sürecinde kullanılan aşamalar: İş anlayışı, veriyi anlamayı, verinin hazırlanması, modelleme, başarısının değerlendirme ve kullanıma sokulması. Şimdi bunlardan bahsedelim.[3]
1.İş Anlayışı: İş probleminin, ele alıp çözülmek üzere veri bilimi takımına gelmiş olmasıdır. Örneğin, kullanıcılar araçlarını satmak istiyor ve buna uygun fiyat belirleme işlemi yapacaklar. Ama piyasayı sürekli takip edemedikleri için, yapay zekâ ile gerçekleştirilmiş bir programa ihtiyaçları vardır. “Kazası var mı, Araçta boya mevcut mu, Çizik var mı?” gibi birçok soru sorularak bir veri seti oluşturulur. Öncelikle model oluşturmak, bizim ana amacımız olarak görülür. Bu model;
Y = x1*b1 + x2*b2 + … + xp*bp
yani fonksiyon gibi düşünülecek ve bilinmeyen yerlere özellikler yazılıp nihai çözüme gidilecektir.
2.Veriyi Anlamak: Veri kaynaklarında veriler vardır ve bunlar veritabanı ortamları olarak geçer. Veri, basit bir excel tablosuna benzeyen özelliklerin olduğu setlerdir.
Veri kaynaklarından veriyi aldığımızda, veriyi anlayıp incelememiz gerekir. Ortalama, standart sapma, özetle istatistiksel sonuçlar çıkarmamız gerekir. Veriyi anlayacağımız hale getirmek için işlemler gerçekleştirmeliyiz. Verinin yapısını öğrendikten sonra verinin hazırlanması basamağına geçeriz.
3.Verinin Hazırlanması: Modelleme çalışmasına geçmeden önce veri setini hazırlamamız gerekir. Veri setindeki yapısal bozuklukları ve hazırlanması gereken yerleri düzenlememiz gerekmektedir. Düzenlenmesi gereken veriler;
- Missing value: Kaybolmuş değer anlamına gelir, eksik veridir.
- Aykırı değer: Verinin yapısının oldukça dışında kalan değerlere denir.
- Gürültü: Bozuk değer anlamına gelir.
Bu aşamada verinin bozukluğu giderilir.
4.Modelleme: Veri içerisinde yer alan yapıların algoritmalara, fonksiyonlara öğretilmesi olayıdır. Arabanın özelliklerini girdiğimizde fiyatını verecek dediğimiz şey fonksiyondan ibaret olacaktır. Veri setinin içindeki yapıların öğrenilmesi gereken özelliklerini, katkılarını ve etkilerini bulmamız gerekir. Bu sebeple çoklu doğrusal regresyon modeli önemlidir. Veri setine çoklu doğrusal regresyon modelini verip aralarında ki ilişkiyi modellediğimizde;
Y = x1*b1 + x2*b2 + … + xp*bp
fonksiyonunu bulmaya çalıştığımızı biliyoruz.
Y: tahmin fonksiyonu
X değişkenleri: veri setinin içinden öğrenecek olduğumuz değişkenlerin etki düzeylerini ve yönlerini belirtecek olan katsayılardır. Yönünü ve şiddetini etkileyecek katsayıları ortaya çıkarır.
5.Değerlendirme (Model başarı değerlendirme): Kurulan modelin başarısının ve doğruluğunun değerlendirilmesi gerekir. Makine öğrenmesi modeli kurup değerlendirme işlemini ele alalım. Değerlendirme derken performans ele alınır.
Modele, çıktısının ne olduğunu bildiğimiz değerler verilir ve tahmini olarak ne değer vereceği, gerçek değer ile modelin tahmin ettiği değer karşılaştırılır. Başarısı değerlendirilir. Gerçek değerler ile tahmin edilen değerler arasındaki farkları minimum seviyeye indirgemek için farklı algoritmalar denenebilir.
6. Kullanıma Sokma: Nihai olarak karar verilen şekliyle, canlı sistemlere entegrasyon yapılır. Bu excel tablosu, veritabanı tablosu sekliyle ya da rapor şeklinde kullanıma sokulabilir. Bir web sitesine de entegre edilebilir.
“Peki netice olarak nedir bu Veri Bilimi ile ilgili son bakış açımız, yorumumuz?”
Benim anlayışıma göre Veri Bilimi veriden faydalı, anlamlı bilgilere ulaşmayı amaçlayan bir bilimdir. Bu açıdan bakıldığında kapsamı çok geniş olmakla birlikte tam teşekküllü bir tanımını yapmak oldukça zor. Özet olarak Yapay Zeka ise bilgisayarların insan gibi düşünebilmelerini sağlamayı amaçlayan bir alan fakat insanın duygusal zeka ve yaratıcılık yeteneklerine sahip değil, hiçbir zaman da olmayacaktır.
Kaynakça
1.https://www.oracle.com/tr/data-science/what-is-data-science.html
2.https://www.mediaclick.com.tr/blog/yapay-zeka-nedir
3.https://gelecegiyazanlar.turkcell.com/
4.http://ybsansiklopedi.com/wp-content/uploads/2018/08/crispdm.pdf
Yapay zeka uygulamalarında veya makine öğrenmesi için yüksek miktarda veriye ihtiyaç duyulmasının nedeni