
![]()
Sqoop Giriş
Merhabalar. Bu yazımda Sqoop User Guide 1.4.6 sürümü referans alarak Sqoop hakkında bilgi vermeye çalışacağım. Yazıda HDFS ve RDBMS üzerinde duracağım mainframe veri setinden bahsetmeyeceğim. Sqoop adını SQL ve Hadoop kelimelerinin evliliğinden almış. İşlevi de aslında adının içinde gizli. SQL’den Hadoop’a bir köprüdür Sqoop, yani ilişkisel veri tabanlarından HDFS’e. Bunu yapabilmek için MapReduce hareketini çekiyor. RDBMS’den Hadoop’a aktarma yaparken satır satır okur. MapReduce hareketini çekebildiği ve böylelikle paralel çalışabildiği için veriyi parça parça çeker ve HDFS’de belirgin bir ayraç (delimiter) ile satır ve sütunları ayırarak dosya halinde yazar. Bunun tersine de HDFS’e yazılmış ayraçlı dosyaları okuyup RDBMS’de yeni bir tabloya yazar. Sqoop sadece veri aktarmakla kalmaz veri tabanlarını incelemenize de olanak verir. Örneğin Hadoop ortamında Sqoop ile MSSQL Server veri tabanına bağlanıp veri şemesını inceleyebilir, sorgular çalıştırıp sonucunu ekranınızda görebilirsiniz. Örnek araçlar:sqoop-list-databases, sqoop-list-tables, sqoop-eval.
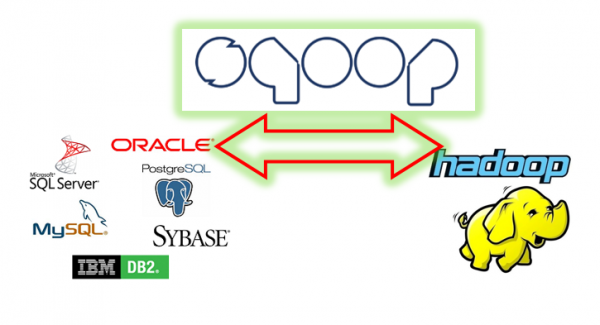
Gerek içeri aktarımlarda gerekse dışarı çıkarmalarda Sqoop size bir çok kişiselleştirme seçeneği sunar. Örneğin ayraç türünü belirleme, belirli satırları veya sütunları alma, dosya formatını belirleme vb. Yazımdaki örnekleri aşağıdaki resimde görülen basit mimari üzerinden vereceğim.

Sqoop Araçları
Sqoop aslında birbiriyle ilişkili araçlar kümesi, ihtiyacınıza uygun araç ve argümanları seçip kullanacaksınız.
\$ sqoop aracın-adı [aracın argümanları]
Yardım komutu ile bilgi almak istediğimiz araçlar hakkında bilgi alabiliriz. Örneğin import aracı hakkında bilgi alalım: sqoop import --help
Sqoop Import
Import, RDBMS’den HDFS’e doğru bir hareketi ifade eder. Import ile ilgili önemli operasyonları kullanıcı rehberi şu şekilde sıralamış. Biz de bu rehber doğrultusunda ilerleyelim:
7.2.1. Sqoop ile bir veritabanı sunucusuna bağlanmak
Sqoop’un temel işlevi bir veri tabanından başkasına veri aktarmak olduğu için ilk adımı bir veri tabanına bağlantı kurmak ile yapar. Bunun için kullanılan argüman --connect argümanıdır. Bu argüman bir bağlantı stringi ister. Örneğin "jdbc:sqlserver://192.168.12.188;database=AdventureWorks2012" Bu bağlantı stringi şunu söyler: “Java Database Connectivity kullanarak sqlserver veri tabanına bağlanacaksın. Sunucu ip adresi: 192.168.12.188 ve veri tabanı adı: AdventureWorks2012’dir.” Bu Sqoop’un nereye neyle gideyim kardeşim sorularının temel cevabıdır. Taksiye bin (jdbc) ve şu siteye (sqlserver), şu apartmana (ip) ve şu daireye (veritabanı) git. Sunucu adresinde sakın localhost kullanmayın çünkü dağıtık yapıda herkesin local hostu kendi hosts dosyasında tanımlı. Yani herkesin local hostu kendine.
Peki adrese gittik kapıyı çaldık demeyecekler mi sen kimsin lo? Burada ile biz buyuz ve bu veri –username ve –password tabanında şu işi yapma yetkimiz var istersen veri tabanındaki listeye bak, adımızı ve şifremizi göreceksin diyoruz. Bu ikilinin ilişkisel veri tabanındaki username ve password olduğunu hatırlatalım. Yer gök username ve password dolu karıştırmayalım. Sqoop operasyonumuz genişliyor. Şimdi bu haldeyiz:
sqoop import --connect "jdbc:sqlserver://192.168.12.188;database=AdventureWorks2012" --username sa --password Çorum19
Sqoop mysql gibi bazı veri tabanlarını destekler. Eğer Sqoop’u başka JDBC uyumlu veritabanları ile kullanmak istersek sürücülerini Sqoop’un bulunduğu Hadoop Cluster makinesinde (bende Namenode) \$SQOOP_HOME/lib dizinine indirmemiz gerekir. Sürücü .jar uzantılı bir dosyadır.
Bağlantı esnasındaki argümanları rehber üç ayrı grupta ele almış; genel, doğrulama ve kontrol.
| Argüman | Açıklama |
|---|---|
--append | Import edilen veriyi HDFS’deki mevcut veriye ekler |
--as-avrodatafile | Veriyi Avro Data Files olarak import eder |
--as-sequencefile | Veriyi SequenceFiles olarak import eder |
--as-textfile | Veriyi plain text olarak import eder. Varsayılan format budur. |
--as-parquetfile | Veriyi Parquet Files olarak import eder |
--boundary-query <statement> | Sorguya kullanıcı tarafından konan sınırdır. |
--columns <col,col,col…> | Tablonun hangi sütunlarını seçeceğimizi bildiririz. |
--delete-target-dir | Eğer hedefte böyle bir dizin varsa onu siler. |
--direct | Veri tabanı için varsa doğrudan bağlantı kullanır. |
--fetch-size <n> | Çağrılacak satır sayısına sınır koyulur. 50 satır getir gibi. |
--inline-lob-limit <n> | Bir satırda bulunacak maksimum LOB genişliği. |
-m,--num-mappers <n> | Kaç tane paralel map görevinin paralel çalışacağını belirten rakamdır. |
-e,--query <statement> | Import the results of statement. |
--split-by <column-name> | Tablonun hangi sütun baz alınarak bölüneceğini belirtir. --autoreset-to-one-mapper ile aynı anda kullanılamaz. |
--autoreset-to-one-mapper | Eğer tabloda primary key yok ise ve bölünecek sütun da belirtilmemişse tek bir mapper kullanılır. Aynı anda --split-by <col> seçeneği ile kullanılamaz. |
--table <table-name> | Okunmak istenen hedef tablonun ismi |
--target-dir <dir> | Hedef HDFS dizini |
--warehouse-dir <dir> | HDFS parent for table destination |
--where <where clause> | Eğer import esnasında WHERE koşulu kullanmak istiyorsak. |
-z,--compress | Sıkıştırmayı açmak istiyorsak |
--compression-codec <c> | Hadoop codec kullanımı (varsayılan gzip) |
--null-string <null-string> | Sütun string ise ve null ise bunun yerine yazılacak string. Örneğin null geldininde “Boş” yazılmasını istersek. |
--null-non-string <null-string> | Sütun string değil ise null değerler için alacak değer |
7.2.2. Import edilecek veriyi seçmek
Sqoop tablo odaklı çalışır. Yukarıda veri tabanı sunucusuna kadar gittik, veri tabanını seçtik username ve password ile kandimizi tanıttık. Bu aşamada hangi tabloyu, view veya tablonun hangi sütunlarını seçeceğimizi where koşulu kullanıp kullanmayacağımızı belirtiyoruz. Örneğimize tablo ismini de ekleyelim.
sqoop import --connect "jdbc:sqlserver://192.168.12.188;database=AdventureWorks2012" --username sa --password Çorum19 --table HumanResources.Department
7.2.3. İsteğe bağlı sorgu ile import (Free-form Query Imports)
Sqoop tablo adı, sütun isimleri ve where koşulu gibi parametreleri almak yerine salt olarak bir sorguyu hedef veri tabanında çalıştırıp sonucunu da döndürebilir. Bu seçenekte --target-dir ile mutlaka hedef dizin belirtmek gerekir. Ancak bu seçenekte çok karmaşık sorgular çalıştırmamak gerekir. Örneğin WHERE koşulunda OR kullanmak veya fazla join yapmak gibi. Sqoop’un temel işlevinin ortamlar arası veri aktarmak olduğunu unutmayalım. Bu seçeneği kullanırsak örneğimiz şöyle olabilirdi:
sqoop import --connect "jdbc:sqlserver://192.168.12.188;database=AdventureWorks2012" --username sa --password Çorum19 --query 'SELECT DepartmentID, Name, GroupName FROM HumanResources.Department WHERE \$CONDITIONS' --split-by DepartmentID --target-dir /user/cloudera/AdventureWorks2012
Eğer işlem paralel yapılacaksa Sqoop bu sorguyu her map görevine gönderecek şekilde bölmelidir bu sebeple \$CONDITIONS ve --split-by kullanılır.
7.2.4. Paralel çalışma kontrolleri
Sqoop genelde işini paralel yapar. Bunu hedef tabloyu parçalara bölüp map görevlerine paylaştırarak yapar. -m veya --num-mappers argümanları ile kaç tane görev olacağını rakamla belirtebiliriz. Hiçbirşey belirtmek isek varsayılan görev sayısı 4 olarak belirlenir. Bu sayı sizin clusterınızın kaynakları ve hedef veri tabanının karşılayabileceği bağlantı miktarına uygun seçilmelidir. Ne kadar köfte o kadar ekmek mantığı yürütülmemelidir. Sqoop paralel import yaparken iş yükünü parçalara bölmek için bir kritere ihtiyaç duyar. Bunun için bir sütun kullanılır. Sqoop bunun için varsayılan olarak primary key sütunu kullanır. Bu sütun incelenir ve en düşük ve yüksek değerler tespit edilir. Görev ikinin katları olan bir rakama bölünür. Varsayılan mapper 4 ide bizim tablomuzda 16 satır var ve primary key DepartmentID 1’den başlayıp 16’da bitiyor. O halde her bir görev parçacığında 4 satır olacaktır. Şayet tabloda primary key yok ise ve --split-by ile bir sütun belirlenmemişse Sqoop import görevi hata verecektir. Bunu aşmanın bir yolu tek mapper kullanmaktır; --num-mappers 1 veya --auto-reset-to-one-mapper.
7.2.5. Dağıtık cache kontrolleri
Sqoop cache için her görevde jar dosyalarını \$SQOOP_HOME/lib dizinine atar. Ancak Oozie kulanıldığı durumlarda buna gerek kalmaz çünkü Oozie kendi paylaşımlı lib dizinini kullanır.
7.2.6. Controlling the Import Process
Varsayılan olarak import süreci JDBC kullanır. JDBC markalar arası veri aktarım kanalıdır. Hedef dizin olarak herhangi bir şey belirlemediğimizde Sqoop kendisi HDFS içinde /user/kullanici_adiniz/tablo_adi/(import edilen dosyalar) şeklinde bir dizine yazar. Aynı şekilde tabloyu Hive veri ambarına yazmak istersek --warehouse-dir /shared kullanabiliriz. Veri ambarı için farklı bir dizin varsa onu --target-dir ile belirtiriz. --target-dir ile --warehouse-dir aynı anda kullanılmaz. Eğer hedef dizinden aynı isimli dosya varsa Sqoop üzerine yazmayı reddeder.
7.2.9. Incremental Imports
Sqoop sadece yeni kayıtların eklenmesi için arttırımlı import modunu kullanır. İki tür arttırımlı import vardır ilki append ikincisi lastmodified. Eğer kaynak tabloda güncelleme olmuyor ve sürekli yeni kayıtlar ekleniyorsa ve bu otomatik artan primary key gibi bir sütundan takip edilebiliyorsa append modu kullanılır. Şayet kaynak tabloda daha önce yüklediğimiz satırlarda güncelleme varsa lastmodified modu kullanılır.
7.2.10. File Formats
Sqoop veriyi ya ayrık metin dosyası (delimited text file) ya da sekans dosyası (SquenceFiles) olarak import eder. Ayrık metin dosyası varsayılan formattır. Bu formatta kaynak tablodaki tüm sütunlar stringe çevrilerek virgül, tab veya belirlenen başka bir ayraç ile ayrılarak metin dosyasına yazılır. Her satır bir kayıttır. İstenirse veri sıkıştırılabilir --compress.
7.2.12. Importing Data Into Hive
Veriyi HDFS dosya yerine Hive tablosuna yazmak --hive-import seçeneği kadar kolaydır. Şayet Hive tablosu zaten varsa --hive-overwrite seçeneği ile tablonun üzerine yazılır. Eğer birden fazla hive kurulu ise veya hive \$PATH’de değilse --hive-home seçeneği kullanılır. Hive’a aktarım yapılacağı zaman -escaped-by, --enclosed-by, ya da --optionally-enclosed-by seçenekleri kullanılmamalıdır.
Hoşçakalın…