

Bu yazımızda birliktelik kurallarının en yaygın kullanılan algoritması olan Apriori ile uygulama yapacağız. Birliktelik kurallarından en çok kullanılanı sepet pazar analizidir. A ürününü alan muhtemelen B ürününü de alır. Örneğin; cips alan muhtemelen meşrubat da alır.
Biz de bu veri seti üzerinde Apriori algoritmasını kullanarak şu ürünü alan müşteriler şunları da almış diyebileceğiz.
setwd('Calisma_Dizniniz')
Apriori algoritması için R’da kullanılacak kütüphane arules kütüphanesi eğer bu kütüphane bilgisayarınızda yok ise install.packages(‘arules’) komutuyla yükleyebilirsiniz. Şimdi gerekli kütüphaneyi belleğe yükleyelim.
library(arules)
Veri setimizi indirelim. Buradan indirebilirsiniz.
dataset = read.csv('Birliktelik_Kurali_Market_Satis_Kayitlari.csv', header = FALSE)
view(dataset)
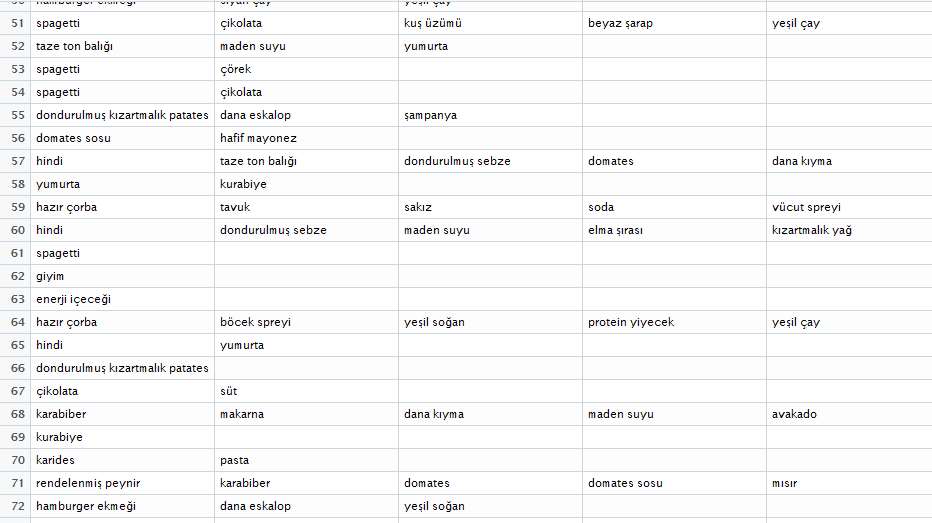
Yukarıdaki resimde veri setinden bir parça görüyoruz. Veri, toplam 7500 müşterinin farklı zamanlarda marketten satın aldığı 120 farklı ürüne ait satın alma kaydından oluşuyor. Üyelik kartıyla kimlerin hangi ürünü aldığı belirlenmiş. Her bir satır, bir müşteri tarafından aynı anda alınan ürünlerin listesini göstermektedir. Genel olarak tabloların tüm hücrelerinin dolu olmasına alışkınız. Burada boşluklar çok, biraz farklı değil mi? Evet. Buna benzer veri yapısına seyrek matris (sparse matrix) denir. Veri setini seyrek matris olarak tekrar yükleyelim. Bu arada tekrar eden kayıtlar varsa onları kaldıralım.
dataset = read.transactions('Birliktelik_Kurali_Market_Satis_Kayitlari.csv', sep = ',', rm.duplicates = TRUE)
Konsoldan 5 satırın mükerrer kayıt içerdiğini görüyoruz. summary() fonksiyonu ile veri seti hakkında daha fazla bilgi alabiliriz.
summary(dataset)
transactions as itemMatrix in sparse format with
7501 rows (elements/itemsets/transactions) and
119 columns (items) and a density of 0.03288973
most frequent items:
mineral water eggs spaghetti french fries chocolate (Other)
1788 1348 1306 1282 1229 22405
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 18 19 20
1754 1358 1045 815 667 493 392 324 258 139 102 67 40 22 17 4 1 2 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 3.000 3.913 5.000 20.000
İlk paragrafta verinin sparse formatta olduğunu ve 7501 satır, 119 sütun ve yoğunluğun 0.032 olduğunu belirtiyor. Bunun anlamı; 7501 satır ve 119 sütundan sadece bu oranda bir doluluk var geri kalanı hep sıfır demek. Daha sonra en sık tekrarlanan ürünler var. 1-20 arasında sıralanmış rakamların altındaki rakamlar sepetleri üstündeki rakamlar ise sepette bulunan ürün sayısını ifade ediyor. Örneği en sağda 1 sepette 20 ürün olduğunu, en solda da 1754 sepette de 1 ürün olduğunu belirtiyor.
Şimdi en sık satılan ürünlerin grafiğini görelim. Bunun için itemFrequency() fonksiyonu kullanılacak.
itemFrequencyPlot(dataset, topN = 10)
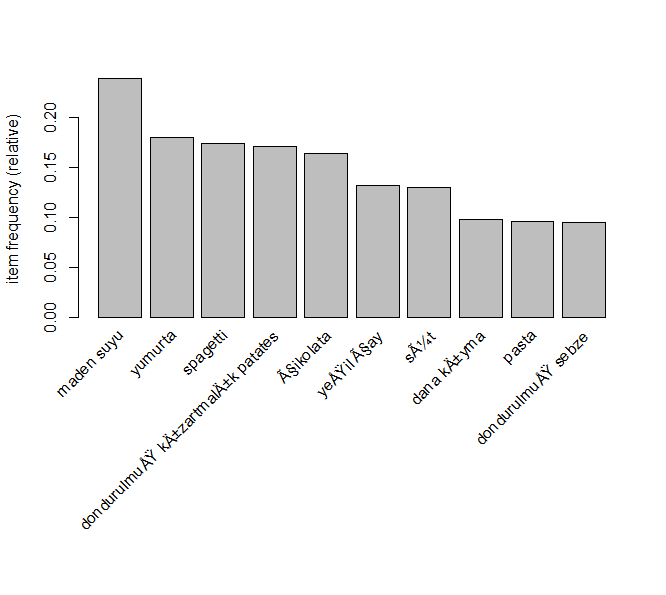
En sık 10 ürüne ait bar grafik yukarıda görülmektedir. Şimdiye kadar veri ile oynadık hep. Şimdi modelimizi oluşturup eğitelim.
rules = apriori(data = dataset, parameter = list(support = 0.004, confidence = 0.2))
ilk argümanımız dataset. Diğer argümanımız parameter liste halinde. Listenin ilk elemanı destek seviyesi, ikinci argüman ise güven seviyesi. Destek ve güven seviyesinden önceki yazımızda bahsetmiştik. Bu iki değer ne kadar yüksek seçilirse elde edilen kurallar da o kadar sağlam olur demiştik. Mesela destek seviyesi yükseldikçe az tekrarlanan ürünler modele giremeyecektir. Bu değerler en iyi ve güçlü kurallar oluşturana kadar defalarca değiştirilebilir. Sonuçlar aşağıdadır.
Apriori Parameter specification: confidence minval smax arem aval originalSupport maxtime support minlen maxlen target ext 0.2 0.1 1 none FALSE TRUE 5 0.004 1 10 rules FALSE Algorithmic control: filter tree heap memopt load sort verbose 0.1 TRUE TRUE FALSE TRUE 2 TRUE Absolute minimum support count: 30 set item appearances ...[0 item(s)] done [0.00s]. set transactions ...[118 item(s), 7501 transaction(s)] done [0.00s]. sorting and recoding items ... [113 item(s)] done [0.00s]. creating transaction tree ... done [0.00s]. checking subsets of size 1 2 3 4 done [0.00s]. writing ... [822 rule(s)] done [0.00s]. creating S4 object ... done [0.00s].
Modelin Apriori olduğunu görüyoruz. Toplamda 822 kural oluşturulmuş. Bakalım en güçlü kurallara. Lift’e göre en güçlü 10 kuralı sıralayalım.
inspect(sort(rules, by = 'lift')[1:10])

Gördüğümüz gibi hafif krema alanların % 29’u tavuk da almış. Domates ve zeytin yağı alanların % 61’i spagetti almış.
Hoşçakalın…
Merhabalar öncelikle güzel çalışma. bende öğrenciyim. Apriori çalışmak istiyorum. Bu çalışmayı paylaşma şansınız var mı? şimdiden teşekkürler.
Merhaba. Maalesef bu yazı dışında çok fazla Apriori çalışma şansım olmadı. Kolay gelsin.