

![]()
Herkese Merhabalar! Bu yazımda metin verisi için çoklu sınıflandırma problemlerini inceleyeceğiz. Bir önceki yazımda derin öğrenme yaklaşımını kullanarak ikili sınıflandırma problemini ele almıştım. Yani sahte ve gerçek haberler arasında ayrım yapabilen bir derin öğrenme modeli oluşturmaya çalışmıştım. Bu yazıda ise yine metin verisinden yararlanarak çoklu sınıf tahmini yapan bir model oluşturmaya çalışacağım.
Veri Seti
Bu çalışma kapsamında University of Carolina – Irvine tarafından oluşturulan “20 news group” veri setinden yararlanılmıştır. Veri seti, 20 kategoriye ait toplam 18846 ingilizce metinden oluşmaktadır. 20 kategori şu konuları içermektedir:
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware',
'comp.windows.x', 'misc.forsale', 'rec.autos',
'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey',
'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space',
'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast','talk.politics.misc','talk.religion.misc']Çalışma kapsamında ise sadece 7 tane konuya odaklanılmıştır. Bu seçimin özel bir nedeni yok. Uzay haberleri hariç 🙂
İncelenen haber konuları: ‘sci.space’, ‘sci.crypt’, ‘talk.politics.guns’, ‘talk.religion.misc’, ‘comp.graphics’, ‘rec.sport.hockey’, ‘rec.autos’ (Uzay, Kriptografi, Politika-Silah, Bilgisayar-Grafiği, Din, Hokey, Otomobil Haberleri).
Peki verinin içeriği nelerden oluşuyor ?
Bunun için ilk olarak verinin yüklenmesi gerekiyor . “20 news group” verisi sklearn kütüphanesi tarafından sunulan hazır veri setidir. Aşağıdaki kod bloğunda, “fetch_20newsgroups()” fonksiyonu kullanılarak veri setinin yüklendiği görülmektedir.
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
print("------------ VERI ------------")
print(data.data[0].strip())
print("\nLABEL:", data.target_names[data.target[0]],
"=", data.target[0])------------ VERI ------------
From: lerxst@wam.umd.edu (where's my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15
I was wondering if anyone out there could enlighten me on this car I saw
the other day. It was a 2-door sports car, looked to be from the late 60s/
early 70s. It was called a Bricklin. The doors were really small. In addition,
the front bumper was separate from the rest of the body. This is
all I know. If anyone can tellme a model name, engine specs, years
of production, where this car is made, history, or whatever info you
have on this funky looking car, please e-mail.
Thanks,
- IL
---- brought to you by your neighborhood Lerxst ----
LABEL: rec.autos = 7Yukarıda da görüldüğü üzere mevcut bütün içeriklere ihtiyacımız yok. Bu sebeple veri içerisinden header (üstbilgi), footers (altbilgi) ve quotes (tırnak işaretleri) kısımlarını çıkartalım. Bu çalışma kapsamında “metin“, “metnin hangi sınıfa ait olduğunu belirten değer” yeterli olacak. Bu adımları yapmamız sklearn kütüphanesiyle çok kolay. Veri setinin kendisi 3 parçadan oluşuyor (“All”, “Train (eğitim)” ve “Test”). Veri setini ister test ve train diye ayrı ayrı alın isterseniz benim yaptığım gibi bütün (“all”) veriyi çekip daha sonra ayırın. Veri setini yüklemek için tekrardan fetch_20newsgroups() fonksiyonunu kullandık. Fakat yukarıdaki kısımda belirtiğimiz durumları sağlayacak parametreleri de ekleyerek. Aşağıdaki kod bloğunda sadece veri setini yüklemedik ayrıca pandas kütüphanesini kullanarak onu bir data frame haline getirdik.
categories = ['talk.religion.misc', 'comp.graphics', 'sci.space', 'talk.politics.guns', 'rec.sport.hockey',
'rec.autos', 'sci.crypt']
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), categories=categories)
df_ = pd.DataFrame([newsgroups.data, newsgroups.target.tolist()]).T
df_.columns = ['text', 'target']
targets = pd.DataFrame(newsgroups.target_names)
targets.columns=['topic']
df = pd.merge(df_, targets, left_on='target', right_index=True)
df.head()
Şekil-1: Örnek Veri
Görüldüğü üzere çalışacağımız veri seti metin, hedef sınıf ve onun karşılığı konu içeriğinden oluşmaktadır. Şekil-1’i incelediğinizde metin analizde hoşumuza gitmeyen karakterlerin mevcut olduğunu görmekteyiz. Örneğin; “\n”, “:”, “>” vb. İlk adım olarak bunları temizleyelim.
Metnin Ön İşleme ve Sayısallaştırma Süreci
Önceki yazılarımda bahsettiğim üzere metin ön işleme yaklaşık 5 işlemden oluşuyor. Bunlar:
- Lower-case
- Noktalama işaretleri, özel karakterlerin ve sayıların silinmesi
- Tokenize işlemi
- Stop-words’lerin silinmesi
- Stemming / Lemmatization
Bu adımları pythonun Regex, NLTK veya Gensim gibi kütüphanelerini kullanarak rahatlıkla gerçekleştirebilirsiniz.
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
import nltk
stemmer = SnowballStemmer('english')
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return " ".join(result)
processed_docs = df['text'].map(preprocess)
df['cleaned_text'] = processed_docs
Şekil-2: İlgili metinlerim temizlendiğini gösteren örnek veri.
Şekil-2’de “cleaned_text” kolonunu incelediğinizde metnin ön işleme adımlarının gerçekleştiğini görebilirsiniz. Metin ön işleme adımlarını tamamladıktan sonra sırada metnin sayısallaştırılması var.
Metnin sayısallaştırılması için vektör uzay modelinden yararlanılmıştır. Vektör uzayları, metinlerin yapısal olmayan formdan sayısal hale getirilmesini sağlayan en geniş kabul gören yöntemdir. Her metin, mevcut kelimelerden oluşan MxN büyüklüğünde bir vektördür. Kısacası vektörler üst üste eklenerek döküman-terim matrisi oluşturulur. Bu matris, M adet haber ve n adet terimden oluşmaktadır. Terim ağırlığını hesaplamak için ise TF-IDF metodundan yararlanılmıştır. TF-IDF yaklaşımında hem ilgili terimin haber içerisindeki sıklığına (Term Frequency – TF) hem de bütün haberler içerisindeki önemine bakılır (Inverse Document Frequency – IDF).
Aşağıdaki kod parçasında TF-IDF yönteminin Python ile nasıl gerçekleştirildiği gösterilmiştir.
from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vector = TfidfVectorizer(min_df = 0., max_df = 1., use_idf = True) tfidf_matris = tfidf_vector.fit_transform(df.cleaned_text) tfidf_matris = tfidf_matris.toarray() # tfidf vector içerisindeki tüm özellikleri al terimler = tfidf_vector.get_feature_names() # dokuman - terim matrisini göster tfidf_df = pd.DataFrame(np.round(tfidf_matris, 3), columns=terimler)
Modelin Oluşturulması
Bu aşamada derin öğrenme modelimizi oluşturma aşamasına geldik. Bilindiği üzere yapay sinir ağları toplam 3 kısımdan oluşmaktadır. Bunlar girdi, gizli ve son olarak çıkış katmanı. Bu çalışma kapsamında oluşturulan model toplam 4 katmandan oluşuyor. Bu arada her ne kadar giriş katmanını yukarıda belirtmiş olsamda toplam katman sayısı belirtilirken giriş katmanları sayılmamaktadır. Bu durumda 3 gizli katman 1 tanede çıkış katmanına sahibiz. Gizli katmanların her birinde “ReLU” aktivasyon fonksiyonu kullanıldı ve her bir katman toplam 64 düğüme sahip. Unutulmamalı ReLU yerine başka aktivasyon fonksiyonlarıda kullanılmaktadır. Fakat ReLU fonksiyonunun işlem yükü, sigmoid ve hiperbolik tanjant fonksiyonlarına göre daha azdır. Bu durum ReLU fonksiyonun tanımı itibariyle aslında şaşılacak bir sonuç değil. Çünkü kendisi [0, +∞) arasında tanımlanmakta yani değerler almaktadır. Unutulmaması gereken dezavantajı ise negatif değerlerde yani fonksiyonun 0 aldığı değerlerde öğrenme işleminin gerçekleşemiyor oluşudur. Çünkü türevide 0 oluyor. Bu durumdan kurtulmak için literatürde başka aktivasyon fonksiyonları kullanılmaktadır (Leaky ReLU gibi).
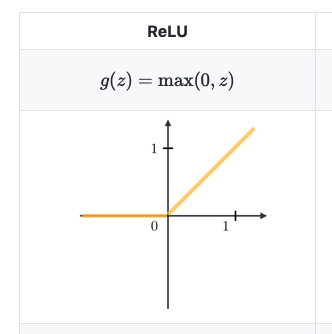
Şekil-3: ReLU fonksiyonu.
Bu çalışma kapsamında çoklu sınıflandırma problemiyle uğraştığımız için çıkış katmanında aktivasyon fonksiyonu olarak “softmax” fonksiyonunu tercih ettim. Çıktı katmanımız bu sefer 7 düğümden oluşuyor. Bunun sebebi 7 farklı sınıf mevcut. Sonuç olarak her girdi için 7 boyutlu bir vektör çıkacak ve elde edilen değerin hangi sınıfa ait olup olmadığının olasılığını gösterecektir. Yani 1 tam olasılık 7 ayrı sınıfa paylaştırılıyor.
input_dim = x_train.shape[1] # Öznitelik Sayısı num_classes = 7 # Sınıf sayısı # Model oluşturuluyor model = Sequential() # Modele üç gizli katman ekliyoruz. Katmandaların üçünde de 64 düğüm var ve her birinde "relu" aktivasyon fonksiyonunu kullanılıyor. model.add(layers.Dense(64, input_dim=input_dim, activation='relu')) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(64, activation='relu')) # Modelimizin ezberlemesini önlemek için Dropout katmanını kullanıyoruz. # Dropout katmanı her adımda belirtilen orandaki girdiyi rassal olarak sıfıra eşitleyerek modelin veriye aşırı uyum sağlamasının önüne geçer. # Dropout değeri 0 ile 1 arasındadır. model.add(Dropout(0.5)) # Son eklediğimiz katman ise çıktı katmanıdır. Çoklu sınıflandırma problemi üzerine çalıştığımız için "softmax" aktivasyon fonksiyonunu kullanıyoruz. model.add(layers.Dense(num_classes, activation='softmax'))
Ağımızı eğitmeden önce 3 önemli kısım mevcut:
- Kayıp Fonksiyonu (Loss Function)
- Eniyileme (Optimizer) Algoritması
- Metrik
Bu çalışmada kayıp (loss) fonksiyonu olarak “categorical_crossentropy” kullanılmıştır. Temelde “categorical_crossentropy” iki olasılık dağılımı arasındaki mesafeyi ölçer. Ayrıca eniyileme yöntemi olarak “rmsprob” (root mean square error propability) ve takip edilecek “ölçüt” (metric) olarak “accuracy” (doğruluk) kullanıldı.
Peki neden “rmsprob” kullanıldı?
Eniyileme algoritmaları, kayıp fonksiyonuna göre ağın nasıl güncelleneceğini belirler. Literatürde birçok eniyileme algoritması mevcuttur. Peki hangi eniyileme algoritmasını kullanmamız gerekiyor? Seçiceğimiz en uygun öğrenme oranı ne olacak? Bu duruma net bir cevap veremiyorum. Çünkü ilgilendiğimiz probleme, seçtiğimiz kayıp fonksiyonuna hatta son katmanda seçilen aktivasyon fonksiyonuna göre çarşı karışabiliyor. Uygulamalarda en çok SGD (Stokastik Gradyan İnişi), Adagrad, Rmsprop, Adam, SGDNesterov gibi algoritmalar kullanılmaktadır. Temelde bu algoritmalar arasında başarım ve hız farkı bulunuyor diyebiliriz. Genel itibariyle bu algoritmalar, bir diğer algoritmadaki eksikleri gidermek için oluşturulmuşlardır. Örneğin, SGD algoritması kullanıldığında eniyileme işlemi uzun sürebilmektedir. Çünkü bazı durumlarda fonksiyon, genel minimum noktaya ulaşamayabilir. Veya ıskalayabilir. Bu durumda RMSprop kullanılarak salınımın azaltılması sağlanabilir. Yani daha hızlı bir şekilde en küçük değere ulaşmak mümkün olur.
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()Model eğitilirken verilerin tamamı aynı anda eğitime katılmaz. “Batch_size” olarak adlandırılan parçalar halinde eğitimde yer alırlar. Bu örnekte modelimiz 40 epokta, 128’lik mini-yığınlar kullanılarak eğitilmiştir. Ayrıca kayıp değeri ve modelin başarısı doğrulama veri setinden gözlenmiştir. Bunun için %20’luk bir veri seti ayrılmıştır.
Fakat bu noktada unutulmaması gerek bir noktaya işaret etmek istiyorum. Çoklu sınıflandırma ile ilgilendiğimiz için etiketleri kategorik olarak etiketlememiz gerekiyor. Yani çıkış katmanından 7 farklı rakam yerine 0 veya 1 değerinin elde edildiği durum. Bu sayede doğru rakama karşılık gelen etiketin indeksi 1 iken diğer tüm etiketler için bu indeks 0 değerini alır. Bu şekilde etiketlerimizi bir vektöre dönüştürmüş oluyoruz. Bu işlemi Keras kütüphanesinde yapmak çok kolay.
from keras import utils one_hot_y_train = utils.to_categorical(y_train, num_classes) one_hot_y_test = utils.to_categorical(y_test, num_classes)
Artık modelimizi eğitebiliriz.
history = model.fit(x_train, one_hot_y_train,
epochs=40,
verbose=-1,
validation_split=0.2,
batch_size=128)Elde edilen sonuç ……
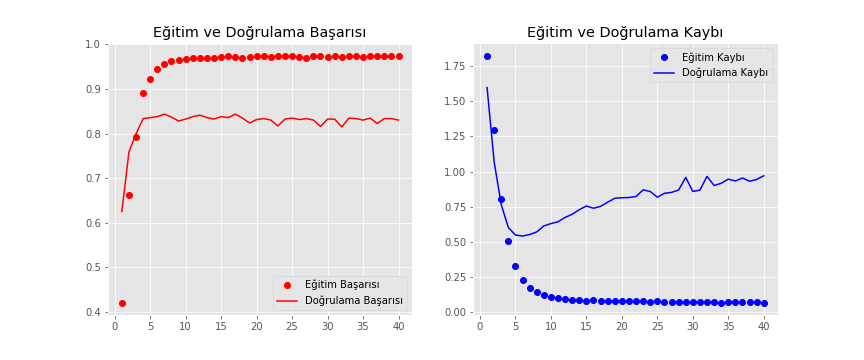
Şekil-4: Sol tarafta eğitim ve doğrulama başarısı. Sağ tarafta ise eğitim ve doğrulama kaybı görülmektedir.
Şekil-4’de görüldüğü üzere eğitim kaybı her epokta düşerken eğitimin başarısı artmaktadır. Bununla birlikte sağ taraftaki grafikte eğitim ve doğrulama kaybının gittikçe düştüğü, yani modelin başarısının gittikçe arttığı, bununla birlikte yaklaşık 6. epoktan sonra eğitim veri seti için kaybın düşmeye devam ettiği fakat buna karşılık doğrulama veri seti için bu değerin arttığı görülmektedir. Yani “aşırı uydurma” söz konusu. Bu durumu önlemek için 6. epoktan sonra eğitimi durdurmalıyız.
Bu sefer 6. epokta duracak şekilde ağımızı tekrardan eğitelim.
model = Sequential()
model.add(layers.Dense(64, input_dim=input_dim, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
history2 = model.fit(x_train, one_hot_y_train,
epochs=6,
verbose=1,
validation_split=0.2,
batch_size=128)result = model.evaluate(x_test, one_hot_y_test, batch_size=128)
>>> result [0.5542471011479696, 0.8204732512740932]
Bu model sonucunda elde edilen başarı oranı %82 olarak belirlenmiştir. Unutulmamalı ki farklı eniyileme algoritmaları veya katman sayılarıyla bu değer artabilirde azalabilirde. Bu çalışma kapsamında bu sonuç yeterli olur diye düşünüyorum 🙂
Başarı oranı haricinde diğer model performans parametrelerini incelediğimizde elde edilen sonuçlar şöyle:
>>> print(classification_report(one_hot2_class, y_pred_class))
precision recall f1-score support
0 0.88 0.87 0.88 299
1 0.70 0.89 0.78 285
2 0.91 0.91 0.91 270
3 0.78 0.81 0.79 299
4 0.93 0.78 0.85 311
5 0.75 0.78 0.77 265
6 0.84 0.67 0.74 215
accuracy 0.82 1944
macro avg 0.83 0.82 0.82 1944
weighted avg 0.83 0.82 0.82 1944Elde edilen karmaşıklık matrisi ise:
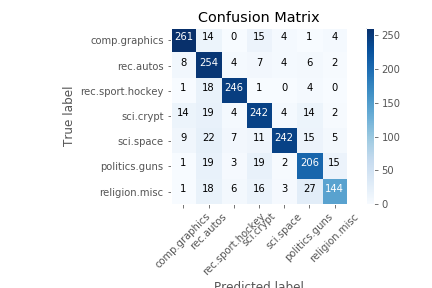
Şekil-5: Elde edilen karmaşıklık matrisi (Confusion Matrix)
Sonuçlar
Bu çalışma kapsamında çoklu sınıflandırma problemi derin öğrenme modeliyle ele alınmıştır. Derin öğrenmeye giriş düzeyindeki bu yazıyla amaçlanan, tek etiketli çoklu sınıflandırma problemini çözen bir modelin oluşturulmasıydı. Yukarıda da görüldüğü üzere %82 başarı oranıyla 7 farklı konu sınıflandırılabilmiştir.
Bu yazı kapsamında sizlere aktaracaklarım bu kadar. Umarım faydalı olabilmişimdir.
Bilimin mihraplarında bilginin peşinde koşmanız dileğiyle.Sağlıcakla Kalın 🙂
Kaynaklar
1- Deep Learning with Python, François Chollet, Manning – (Python ile Derin Öğrenme, Bilgin Aksoy, Buzdağı Yayınevi)
2- https://scikit-learn.org/0.19/datasets/twenty_newsgroups.html
3- http://qwone.com/~jason/20Newsgroups/
4- https://medium.com/@ayyucekizrak/derin-öğrenme-için-aktivasyon-fonksiyonlarının-karşılaştırılması-cee17fd1d9cd
5- https://stanford.edu/~shervine/l/tr/teaching/cs-230/cheatsheet-convolutional-neural-networks#activation-function (Şekil-3)
6- https://unsplash.com/photos/Oaqk7qqNh_c (kapak fotografı)
7- https://medium.com/deep-learning-turkiye/derin-ogrenme-uygulamalarinda-en-sik-kullanilan-hiper-parametreler-ece8e9125c4
Ek Bilgi:
- Bu çalışma kapsamında derin öğrenme modeli oluşturmak için keras kütüphanesinden yararlanılmıştır. Keras kütüphanesi içerisinde üç arka uç (backend engine) motoru mevcuttur. Bunlar Tensorflow, Theano ve CNTK. Bu çalışma kapsamında arkaplanda Tensorflow kullanılmıştır.
- Kullanılan Python versiyonu: 3.7.3
- Keras versiyonu: 2.2.5
- Sklearn versiyonu: 0.21.3
- Tensorflow versiyonu: 1.14.0
- İşletim sistemi: macOS