

![]()
Yapay öğrenme, veri bilimi ve makine öğrenmesi son yılların en popüler kavramlarından. Model deployment öncesinde bir çok insan bu alanda, özellikle model geliştirme sürecinde bilgi sahibi olmak ve yetenek kazanmak için çabalıyor. Bu kadar ilgi olmasına rağmen ne yazık ki model geliştirmek ve iyi bir başarı skoru elde etmekle sürecin sona erdiği gibi bir eksik algılama var. Bunun en önemli sebeplerinden birisi Kaggle platformunda, yarışmalarda veya eğitimlerde modelden geçirilen test seti tahmin sonuçlarının elde edilmesiyle sürecin sonlanıyor, yarışmanın/eğitimin bitiyor olmasıdır. Aslında modeller gerçekten bir fayda üretmek için geliştirilirler. Bu faydanın elde edilmesi için model geliştirmenin sonrasındaki ilk adım model deployment’dır. Bu yazımızda FastAPI, Docker ve Terraform kullanarak ML model deployment örneği yapacağız. Önce problemi anlayacağız. Sonra onu çözmek için model geliştireceğiz daha sonrasında bu modeli FastAPI ile geliştirdiğimiz bir API ile sunacağız ve bu API’yi Docker üzerinde çalıştıracağız. Docker imajı oluşturma ve container’ı ayağa kaldırma işini ise Terraform ile yapacağız.
Ortam bilgileri
- CentOS7
- Docker Engine Community 20.10.12
- Terraform 1.3.6
- Python 3.8
Problem Nedir?
Problemimiz meşhur Advertising problemidir. TV, gazete ve radyo reklam harcamalarına bağlı olarak satış miktarını makine öğrenmesi (regresyon) modeli ile tahmin edeceğiz.
Python Paketleri
Projemiz için gereksinimler aşağıdaki gibidir.
- requirements.txt
pandas==1.4.1 scikit-learn<=1.0.2 joblib fastapi[all]==0.86.0 uvicorn[standard]==0.18.3
Model Geliştirme
Aşağıdaki python kodları veri setini okumaktan model geliştirmeye ve modeli lokal diske kaydetmeye kadar yapmaktadır.
- train_advertising_model.py
import pandas as pd
# read data
df = pd.read_csv("https://raw.githubusercontent.com/erkansirin78/datasets/master/Advertising.csv")
print(df.head())
# Feature matrix
X = df.iloc[:, 1:-1].values
print(X.shape)
print(X[:3])
# Output variable
y = df.iloc[:, -1]
print(y.shape)
print(y[:6])
# split test train
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# train model
from sklearn.ensemble import RandomForestRegressor
estimator = RandomForestRegressor(n_estimators=200)
estimator.fit(X_train, y_train)
# Test model
y_pred = estimator.predict(X_test)
from sklearn.metrics import r2_score
r2 = r2_score(y_true=y_test, y_pred=y_pred)
print("R2: ".format(r2))
# Save Model
import joblib
joblib.dump(estimator, "saved_models/03.randomforest_with_advertising.pkl")
# make predictions
# Read models
estimator_loaded = joblib.load("saved_models/03.randomforest_with_advertising.pkl")
# Prediction set
X_manual_test = [[230.1,37.8,69.2]]
print("X_manual_test", X_manual_test)
prediction = estimator_loaded.predict(X_manual_test)
print("prediction", prediction)Şuan elimizde saved_models/03.randomforest_with_advertising.pkl kayıtlı modelimiz oluştu.
Model Deployment
Aşağıdaki kodlar basit bir FastAPI uygulamasıyla /prediction/advertising uç noktasından modeli sunmaktadır.
- main.py
from fastapi import FastAPI, Request
from pydantic import BaseModel
import joblib
# Read models saved during train phase
estimator_advertising_loaded = joblib.load("saved_models/03.randomforest_with_advertising.pkl")
class Advertising(BaseModel):
TV: float
Radio: float
Newspaper: float
class Config:
schema_extra = {
"example": {
"TV": 230.1,
"Radio": 37.8,
"Newspaper": 69.2,
}
}
app = FastAPI()
# prediction function
def make_advertising_prediction(model, request):
# parse input from request
TV = request["TV"]
Radio = request['Radio']
Newspaper = request['Newspaper']
# Make an input vector
advertising = [[TV, Radio, Newspaper]]
# Predict
prediction = model.predict(advertising)
return prediction[0]
# Advertising Prediction endpoint
@app.post("/prediction/advertising")
def predict_iris(request: Advertising):
prediction = make_advertising_prediction(estimator_advertising_loaded, request.dict())
return predictionDocker İmajı Oluşturma
Model deployment API’sinin bir container olarak çalışabilmesi için öncelikle bir imaj oluşturmamız gerekir. İmaj oluşturmak için ise bir Dockerfile kullanmalıyız.
- Dockerfile
FROM python:3.8 COPY requirements.txt requirements.txt RUN pip install --upgrade pip RUN pip install -r requirements.txt COPY . /opt/ WORKDIR /opt EXPOSE 8000 ENTRYPOINT uvicorn main:app --host=0.0.0.0 --port=8000
Hemen imaj oluşturmayacağız. Bunu Terraform yapacak.
Terraform
terraform {
required_providers {
# We recommend pinning to the specific version of the Docker Provider you're using
# since new versions are released frequently
docker = {
source = "kreuzwerker/docker"
version = "2.23.1"
}
}
}
# Configure the docker provider
provider "docker" {
}
# Create a docker image resource
resource "docker_image" "my_fastapi_res" {
name = "my_fastapi"
build {
path = "."
tag = ["my_fastapi:develop"]
build_arg = {
name : "my_fastapi"
}
label = {
author : "vbo"
}
}
}
# Create a docker container resource
resource "docker_container" "fastapi" {
name = "fastapi"
image = docker_image.my_fastapi_res.image_id
ports {
external = 8002
internal = 8000
}
}Terraform projesi oluşturalım. Bunun için
terraform init
Bu komut git init ile benzer işleve sahiptir. Proje oluştuktan sonra artık terraform’u başlatabiliriz.
terraform apply --auto-approve
Kontrol edelim bakalım container oluşmuş mu?
docker ps
- Çıktı
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a2286793fc51 97ada9660876 "/bin/sh -c 'uvicorn…" 15 seconds ago Up 13 seconds 0.0.0.0:8002->8000/tcp fastapi
Arayüz
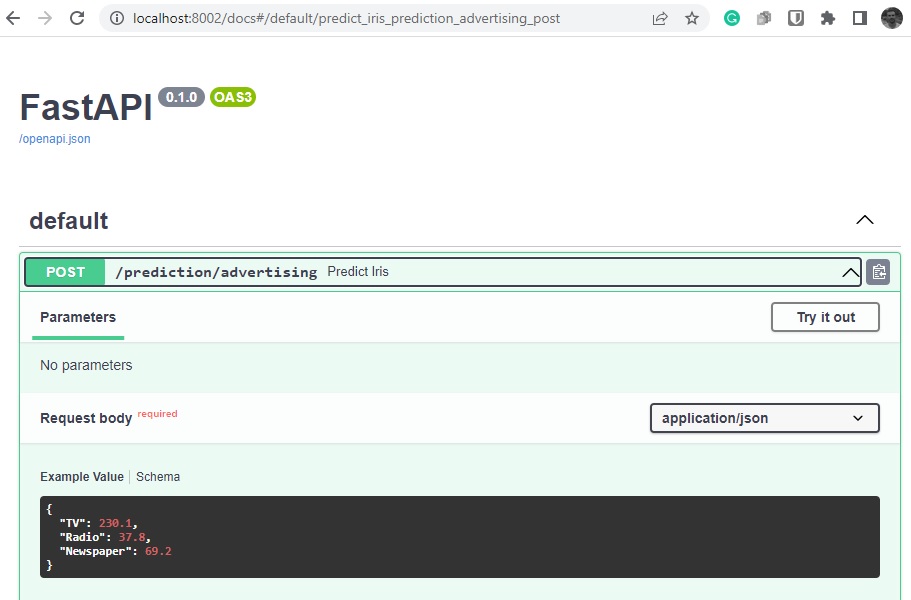
Tebrikler! Operasyon başarılı. Modelinizin keyfini çıkarın.
Tüm kodlara buradan ulaşabilirsiniz.
Bu konuyu ve buna benzer bir çok farklı model deployment, mlops, ml engineer konularını uygulamalı seviyede öğrenmek istiyorsanız VBO MLOps Bootcamp‘i şiddetle tavsiye ederim.
Tekrar görüşünceye dek çav…