

![]()
Merhaba bu yazımda sizlere Apache Hudi’yi kısaca tanıtmaya çalışacağım.
Veri dünyasında uzun süredir konuşulan konuların en başında Real Time(Gerçek Zamanlı) veriler geliyor. Gerçek zamanlı veri işleme gerçekten her alanda çok önemlidir. Çünkü dikkatimiz artık saniyeler bazına düşmüş durumda ve biz saniyelerimizi merak ediyoruzdur. Örneğin bir yemek siparişinin durumunu anlık olarak takip etmek istiyoruz. Bu ne kadar güzel görünse de geri planda operasyonel yükü büyütüyor. Çünkü eğer gerçek zamanlı veri işleme yapacaksanız mimari tasarımınızdaki tüm bileşenler kusursuz bir şekilde işlemek zorundadır. Bir yerde bile hata olursa gerçek zamanlı beslenen dashboardlarda bozulmalar meydana gelecektir. Bu da müşteri tarafından bile hissedilen önemli bir problem olur. İşte bu yazımda size hem bu operasyonel yükü azaltan hem de gerçek zamana yakın işlerde çok hızlı çalışan bir yapıyı anlatacağım.
Öncelikle gerçek zamana yakın verilerin açılımını yapalım. Gerçek zamana yakın veriler gerçek zamanlı veriler gibi olmayıp yaklaşık 20-30 saniye gecikmeli olarak işlenen verilerdir. Bu sebeple gerçek zamanlı veriler gibi operasyonel yükü çok fazla değildir. Gerçek zamanlı veriler tabi ki çok önemlidir ancak bazı durumlarda gerçek zamana yakın veriler kullanmak bize avantaj sağlayabilir. Mesela Spark streaming uygulamanız çok işlemci gücü harcıyorsa, gerçek zamanlı veriler yerine gerçek zamana yakın verileri kullanmak size işlem gücünü azaltma bakımından kolaylık sağlayabilir.
Yazımızın asıl konusu olan Apache Hudi’ye gelmek istiyorum. Apache Hudi aslında açık kaynaklı olarak geliştirilen incremental veri işleme ve veri akış hattı (data pipeline) yaratmamızı sağlayan bir framework’tür. Bu framework’ün en büyük artıları iş birimleri tarafından gelen ihtiyaçları veri döngüsü ve veri kalitesi sağlayarak karşılayabilmesidir. Ayrıca Hudi, Hadoop üzerinde upsert operasyonlarına imkan verir. Hudi’nin HDFS üzerinde kullanıma sunduğu iki tip tablo vardır.
- Read Optimized Table
- Near-Real Time Table
Read Optimized Table kullanılmasının sebebi columnar (sütun) bazlı verilerin sorgu performanslarını artırmak içindir. Diğer yandan ise Near-Real Time Table’ın kullanılma amacı ise gerçek zamana yakın olan verilerin (row ve columnar olan veriler karışık olarak kullanılır) sorgu performansını artırmaktır.
Hudi’nin Özellikleri
- Kendine has indeksleme yapısı sayesinde upsert, delete işlemleri hızlı bir şekilde yapabilir.
- Transaction, rollback, concurrency gibi işlemleri kontrol edebilir.
- Otomatik olarak dosya boyutunu ayarlayabilir, veriyi cluster hale getirebilir, sıkıştırabilir ve temizleyebilir. (Small file problemini çözer.)
- Metadata takip sistemi sayesinde ölçeklenebilir yapı kurulmasına imkan verir.
- Spark, Presto, Hive gibi araçlarla çalışabilir.
- Streaming uygulamaları için sink (verinin yazıldığı yer) olarak kullanılabilir.

Hudi’nin geniş bir platform desteği mevcuttur. Hudi kullanacaksanız yukarıdakine benzer bir mimari tasarlayabilirsiniz.
Hudi’nin Performansı
Hudi’nin resmi sitesinde gerçek verilerde yaptığı deneylerin sonucu aşağıdaki gibidir.
- Upsert: Büyüklüğüne göre değişen veritabanı verilerinin copy-on-write olarak yazılan verilerin hızlarını aşağıdaki grafikte görebilirsiniz.
- Upsert: Büyüklüğüne göre değişen veritabanı verilerinin copy-on-write olarak yazılan verilerin hızlarını aşağıdaki grafikte görebilirsiniz.
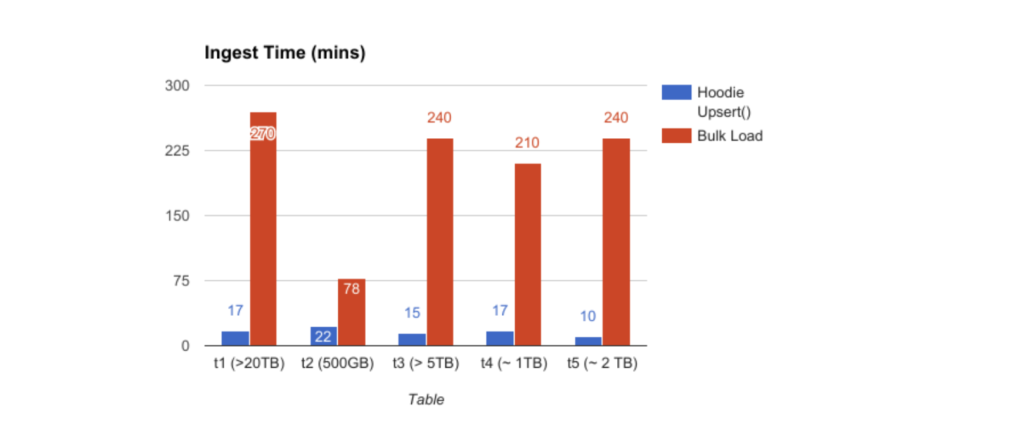
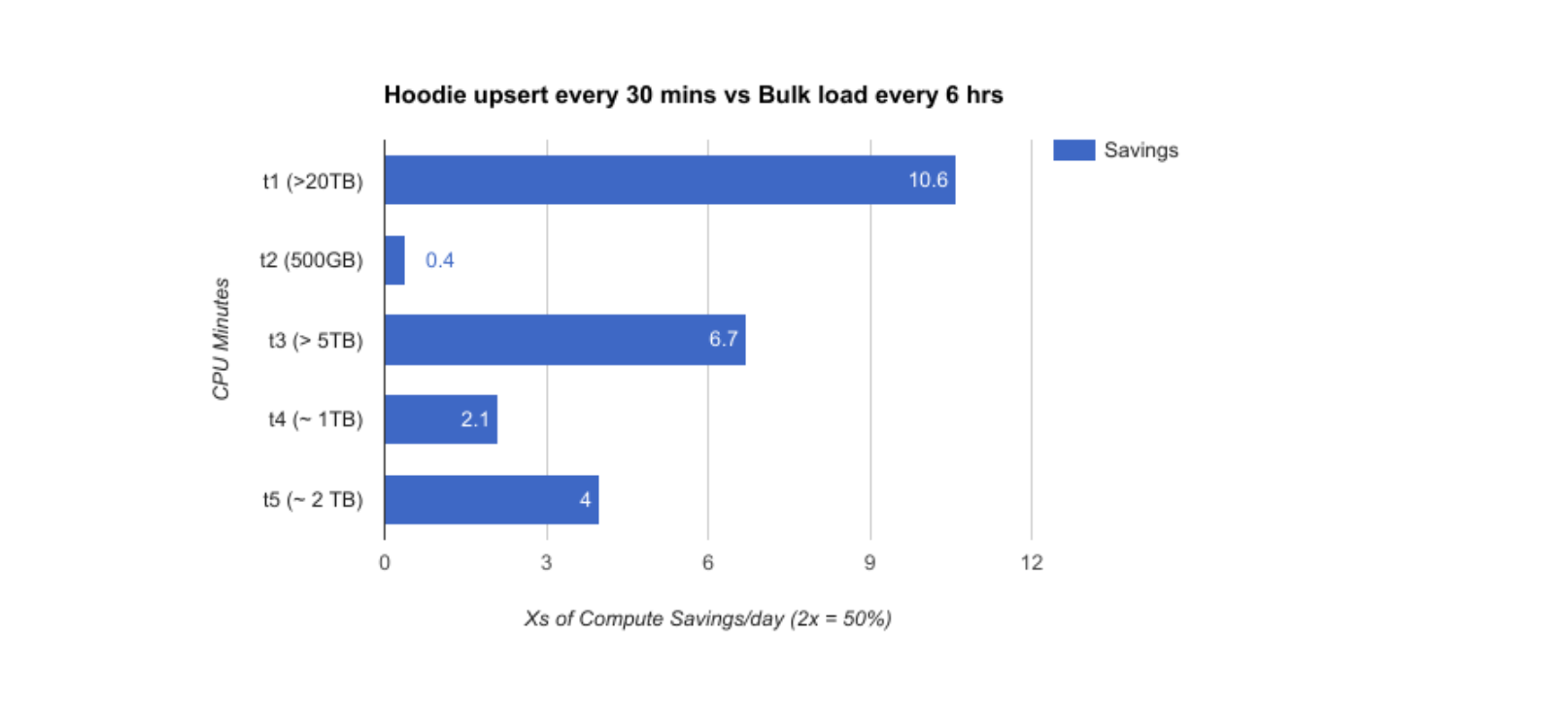
- Indexing: Daha efektif olarak verinin işlenmesi ve düzenlenmesi için indeksleme işlemleri çok önemlidir. Hudi’nin kayıtları getirme ve batch olarak verilerin yazılması için indekslemeye ihtiyaç vardır. Böylece sorgularınızın performansını 10 kat artırır.
Peki Snapshot olarak baktığımızda performanslar nasıl?

Hudi’nin snapshot performansında reduction ve efficiency önemli değildir. Burada önemli olan Hudi tablosunun türüdür. Yukarıda Hive’daki performans farklılıklarını görüyoruz.
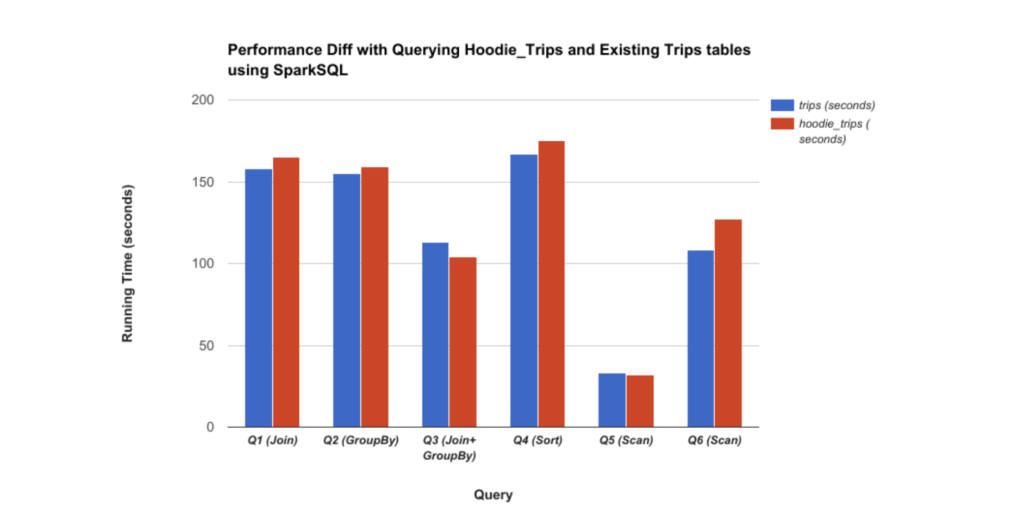
Spark için sorgu performansına baktığımız zaman özellikle işlem yükünün fazla olduğu yapılarda Hudi’nin performansının daha iyi olarak çalıştığını söyleyebiliriz.
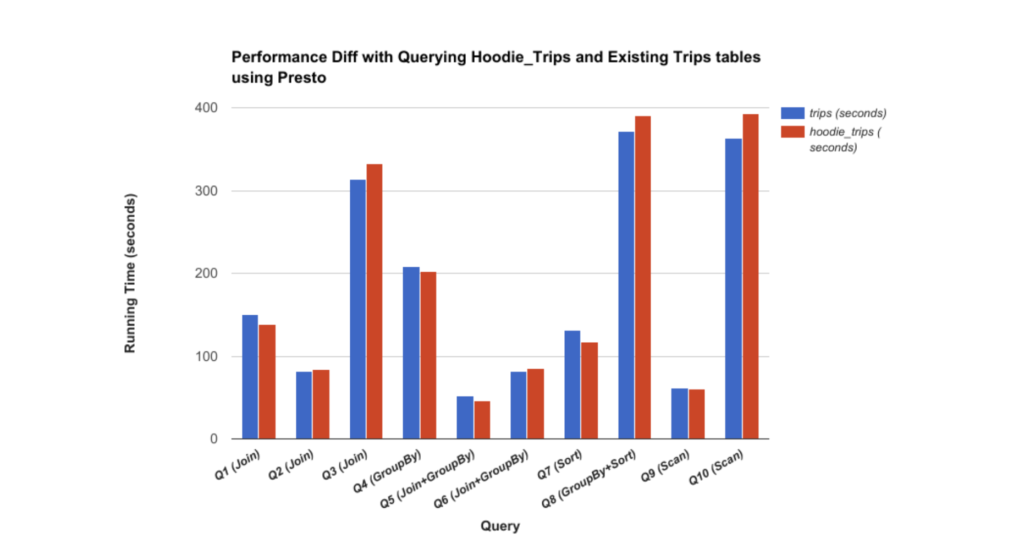
Hudi’nin bir diğer karşılaştırılması da PrestoDB üzerinden yapılmıştır. Burada görüldüğü üzere Hudi sorgunun büyüklüğüne göre değişen performansı olduğunu gözlemliyoruz. Tabi ki yükü fazla olan sorgular Hudi’de daha hızlı bir şekilde elden geçmektedir.
Hudi’yi Hangi Ortamda Kullanmak Sağlıklıdır?
Hudi kullanım olarak sizi serbest bırakan bir yapıya sahiptir. Hudi’yi genel olarak Spark uygulamaları üzerine kurmak performans olarak daha avantajlı olsa da Hive, Presto gibi yapılarla da çok rahat bir şekilde kullanılabilir. Hudi’yi Spark uygulamaları ile Kubernetes üzerinde de kullanabilirsiniz. Storage bakımından ise bütün bulut ortamlarını destekliyor. Hudi ingestionları 2 parçaya ayrılıyor. Bunlar Run Once Mode ve Continuous Mode’dur. Run Once Mode adı üstünde daha çok batch çalışan, yani bir defada yazma işini gerçekleştiren uygulamalar içindir. Continuous Mode ise devamlı bir şekilde çalışan, yani near gerçek zamanlı ya da gerçek zamana yakın uygulamalar içindir.
Bu yazımda genel hatlarıyla Apache Hudi teknolojisini sizlere aktarmaya çalıştım. Eğer ilginizi çektiyse websitesine gidip daha fazla detaylı bilgiye sahip olabilirsiniz. Bir sonraki yazımda tekrar görüşmek üzere…
Kaynakça:
- https://hudi.apache.org/
- https://hudi.apache.org/docs/performance
- Kapak Resmi: Photo by Boston Public Library on Unsplash