

![]()
Sınıflandırma notları serimize devam ediyoruz. Sınıflandırma ve k en yakın komşu teorisinden daha önce bahsetmiştik. Özet olarak tekrar bir üzerinden geçelim. Sınıflandırmada bildiğimiz gibi eğittiğimiz bir model kullanarak hedef niteliğini bilmediğimiz ancak elimizde özellikleri olan bir nesnenin hangi sınıfa dahil olacağını tahmin ediyoruz. Sınıflandırma algoritmalarından k en yakın komşu en yaygın olarak kullanılan algoritmadır. Mantık kabaca şöyle; k sayısı belirlenir, nesnenin hangi sınıfa dahil olacağını belirlemek için kendisine en yakın olan kaç komşu kullanılacağına dair bir sayı. Bu komşulara olan mesafe bir yöntemle hesaplanır (örn. öklid) Daha sonra bu k sayısı içinde en fazla hangi sınıfa yakınlık var ise bilinmeyen nesnenin de o sınıfa dahil olduğuna hükmedilir. Bu yazımızda Python ile uygulama yapacağız.
Kütüphaneleri İndirme, Çalışma Dizinini Ayarlama, Veri Setini İndirme
Veri setini buradan indirebilirsiniz.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir('Calisma_Dizniniz')
dataset = pd.read_csv('SosyalMedyaReklamKampanyası.csv')Spyder’ın variable explorer penceresinden veri setimizi görelim:

Veriyi Anlamak
Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, Tahmini Gelir yıllık tahmin edilen gelir, SatinAldiMi ise belirli bir ürünü satın almış olup olmadığı, hadi lüks araba diyelim. Bu veri setinde kolayca anlaşılabileceği gibi hedef değişkenimiz SatinAldiMi’dir. Diğer dört nitelik ise bağımsız niteliklerdir. Bu bağımsız niteliklerle bağımlı nitelik (satın alma davranışının gerçekleşip gerçekleşmeyeceği) tahmin edilecek.
Veri Setini Bağımlı ve Bağımsız Niteliklere Ayırmak
Yukarıda gördüğümüz niteliklerden bağımsız değişken olarak sadece yaş ve tahmini maaşı kullanacağız.
X = dataset.iloc[:, [2,3]].values y = dataset.iloc[:, 4].values

Veriyi Eğitim ve Test Olarak Ayırmak
Veri setinde 400 kayıt var bunun 300’ünü eğitim, 100’ünü test için ayıralım.
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Feature Scaling
Bağımsız değişkenlerden yaş ile tahmini gelir aynı birimde olmadığı için feature scaling uygulayacağız.
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)
K En Yakın Komşu Modeli Oluşturmak ve Eğitmek
Şimdi scikit-learn kütüphanesi neighbors modülü KNeighborClassifier sınıfından oluşturacağımız classifier nesnesi modelimiz oluşturalım.
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p = 2) classifier.fit(X_train, y_train)
Sınıf parametrelerinden biraz bahsedelim. n_neighbors kullanılacak komşu sayısı. metric ise komşuların yakınlığını belirlemede hangi yöntemi kullanacağımız. mesafeye dayalı yöntem kullanacak isek minkowski seçiyoruz. p ise hangi mesafe yöntemini k kullanacağımız, 2 öklid mesafesini kullan demektir.
Test Seti ile Tahmin Yapmak
Ayırdığımız test setimizi (X_test) kullanarak oluşturduğumuz model ile tahmin yapalım ve elde ettiğimiz set (y_pred) ile hedef değişken (y_test) test setimizi karşılaştıralım.
y_pred = classifier.predict(X_test)

Yukarıda y_test (gerçek veri) ile modelin tahmin ettiği y_pred bir görüntü bulunuyor. Örneğin 9. indekste bulunan müşteriye baktığımızda gerçekte satın alma gerçekleşmemiş iken model satın alır demiş, yani yanlış sınıflandırma yapmış. Şimdi kaç tane doğru kaç tane yanlış sınıflandırma olmuş bir bakalım.
Hata Matrisini Oluşturma
Yaptığımız sınıflandırmanın doğruluğunu kontrol etme yöntemlerinden birisi de hata matrisi oluşturmaktır. Hata matrisi için scikit-learn kütüphanesi metrics modülü confusion_matrix fonksiyonunu kullanıyoruz.
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print(cm) [[64 4] [ 3 29]]
Bildiğiniz gibi 100 kayıtlık test verisi ayırmıştık. Yukarıda gördüğümüz hata matrisine göre 7 kayıt yanlış sınıflandırılmış, 93 kayıt doğru sınıflandırılmış. Lojistik regresyonda yanlış sınıflandırma sayısı 11 idi. K en yakın komşu daha iyi iş çıkarmış görünüyor. Grafiğimizi görelim:
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('blue', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('yellow', 'green'))(i), label = j)
plt.title('K En Yakın Komşu (Eğitim Seti)')
plt.xlabel('Yaş')
plt.ylabel('Maaş')
plt.legend()
plt.show()
Şimdi grafiğimizi test setleri için çizelim. Bunun için yukarıdaki kodda veri setlerini ve etiket bilgilerini değiştirmek yeterli olur.
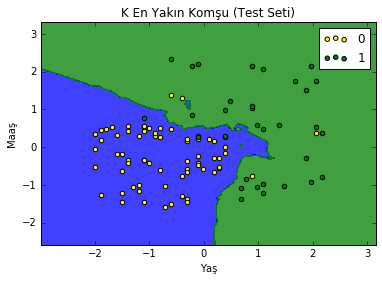
Yanlış sınıflandırılan 7 noktayı buradan sayabiliriz.
from sklearn.neighbors import KNeighborsClassifier satırını yazınca şu şekilde bir hata alıyorum. No module named ‘sklearn.neighbors’ scikit learn 0.18 versionu sklearn 0.0 versiyonu var. Teşekkürler
Merhaba, gönderdiğiniz hata kodu sklearn paketinin işletim sistemine sağlıklı bir şekilde eklenemediğine işarettir. Bu tür hatalar; python versiyonu, paket versiyonu, işletim sistemleri ve bunların versiyonları, paketlerin birbirine olan bağımlılıkları (dependency) gibi bir çok sebepten kaynaklanabiliyor. Örneğin Ubuntu için benzer bir hatanın çözümü: https://askubuntu.com/questions/599468/importerror-no-module-named-sklearn adresinde yer alıyor. Siz de karşılaştığınız hata kodunu arama motorlarından sorgulayarak benzer hataların çözümlerine ulaşabilirsiniz. İyi çalışmalar…
hocam ben şurda hata aldım bunu nasıl aşarım?
X = dataset.iloc[:, [2,3]].values
y = dataset.iloc[:, 4].values
IndexError Traceback (most recent call last)
Input In [4], in ()
—-> 1 X = data.iloc[:, [2,3]].values
Merhaba,
şu komutta şu hatayı aldım neden olabilir?
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
[[64 4]
[ 3 29]]
^
SyntaxError: invalid syntax. Perhaps you forgot a comma?