
Karar ağaçlarını sınıflandırma ve regresyon olarak ikiye ayırabiliriz. Karar ağacı regresyonu özetle şu işi yapıyor: Bağımsız değişkenleri bilgi kazancına göre aralıklara ayırıyor. Tahmin esnasında bu aralıktan bir değer sorulduğunda cevap olarak bu aralıktaki (eğitim esnasında öğrendiği) ortalamayı söyleyiveriyor. Bu sebeple karar ağacı regresyonu diğer regresyon modelleri gibi sürekli değil, kesiklidir. Yani belli bir aralıkta istenen tahminler için aynı sonuçları üretir. Bu yazımızda Python ile basit bir karar ağacı regresyonu uygulaması yapacağız.
Kütüphaneleri İndirme, Çalışma Diznini Ayarlama ve Veri Setini İndirme
Veriyi buradan indirebilirsiniz.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir('Sizin_Calisma_Dizniniz')
dataset = pd.read_csv('PozisyonSeviyeMaas.csv')

Veriyi Anlamak
Yukarıdaki tabloda niteliklerimizi görüyoruz:
Pozisyon: İş Ünvanı. Nitelik türü kategorik.
Seviye: İş ünvanlarını birbiri arasında maaş, astlık-üstlük vb. sıralayan nitelik. Nitelik türü nümerik.
Maas: Her bir pozisyondaki personelin yıllık maaşı. Nitelik türü nümerik.
Bu veri seti ve kuracağımız polinom model ile çözmeye çalışacağımız problem seviyesine göre bir personelin maaşını tahmin etmek olacak. Böylelikle y hedef değişkenimizin Maas, bağımsız değişken Seviye olduğunu çıkarabiliyoruz. Pozisyon seviye ile yakından ilgili bir nitelik ve seviyenin adlandırması gibi bir fonksiyonu olduğu için bu niteliği veri setinden çıkarıyoruz.
Veri seti çok az bir kayıttan (10 adet) oluştuğu için eğitim ve test olarak ayırmıyoruz.
Bağımlı ve Bağımsız Değişkenleri Oluşturmak
X = dataset.iloc[:, 1:2].values y = dataset.iloc[:, 2].values

Karar Ağacı Regresyon ile Modeli Eğitmek
Karar Ağacı Regresyon scikit-learn kütüphanesi tree modülünün bir sınıfı olarak tanımlanmış. Sınıfımız ise DecisionTreeRegression. Bu sınıftan yaratacağımız nesne, yani regressor, makine işimizi yapacak. Modelimizi eğitmek için öncelikle bu sınıftan regressor adında bir nesne yaratıyoruz. Daha sonra bu nesnenin fit() metoduna X, y değişkenlerimizi parametre olarak veriyoruz. Böylelikle makinemizi kurmuş oluyoruz.
from sklearn.tree import DecisionTreeRegressor regressor = DecisionTreeRegressor(random_state=0)
burada kullandığımız random_state parametresi sınıfın aldığı birçok parametreden yalnızca birisi. Diğer parametreler varsayılan değer olarak dahil oluyor. Makinemizi eğitelim.
regressor.fit(X, y)
Modelimizi de eğittik şimdi bir tahmin yapalım. Seviye 6.5 için bir tahmin yapalım bakalım sonuç ne olacak?
y_pred = regressor.predict(np.array([6.5]).reshape(-1,1))
Sonuç: 150000. Çok düzgün bir rakam çıktı. Acaba niye böyle bir de grafikten bakalım:
plt.scatter(X, y, color = 'red')
plt.plot(X, regressor.predict(X), color = 'blue')
plt.title('Karar Ağacı regresyon')
plt.xlabel('Pozisyon Seviye')
plt.ylabel('Maaş')
plt.show()
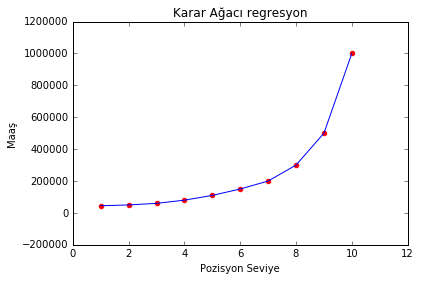
Evet. Regresyon eğrisi gitmiş noktalara yapışmış. İlk paragrafta demiştik ki karar ağacı regresyonu kesiklidir. Yani biz burada 6.5 yerine 6.1 tahmin etmeye kalksaydık yine aynı sonucu verebilirdi. Deneyelim:
regressor.predict(6.1)
Evet aynen söylediğim gibi 6.1 için de 150000 tahmin etti. Burada aslında bir sıkıntı yok. Sıkıntı sadece grafiği çizerken ıskalamızı biraz daha inceltmeliyiz. Yani sadece cm değil mm’lere de duyarlı ol demeliyiz. Bunu grafik çizimiyle ilgili kodlarımızda düzenleme yaparak giderelim:
X_grid = np.arange(min(X), max(X), 0.01)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
plt.title('Karar Ağacı regresyon')
plt.xlabel('Pozisyon Seviye')
plt.ylabel('Maaş')
plt.show()
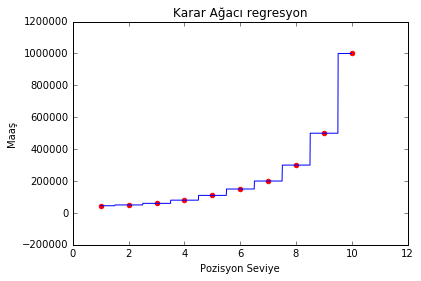
Başlangıçta da bahsettiğimiz gibi model bilgi kazancına göre bağımsız değişkeni belli aralıklara böldü ve aralıktaki tüm değerleri ortalamaya eşitledi. Bu aralıkta bağımsız değişkenin alacağı tüm değerlerin bağımlı değişken karşılığı ortalaması sonuç olarak döndürülür. Böyle basit bir veri üzerinde bu model biraz tuhaf olabilir ancak çok daha fazla niteliğin olduğu verilerde iş görebilir.