
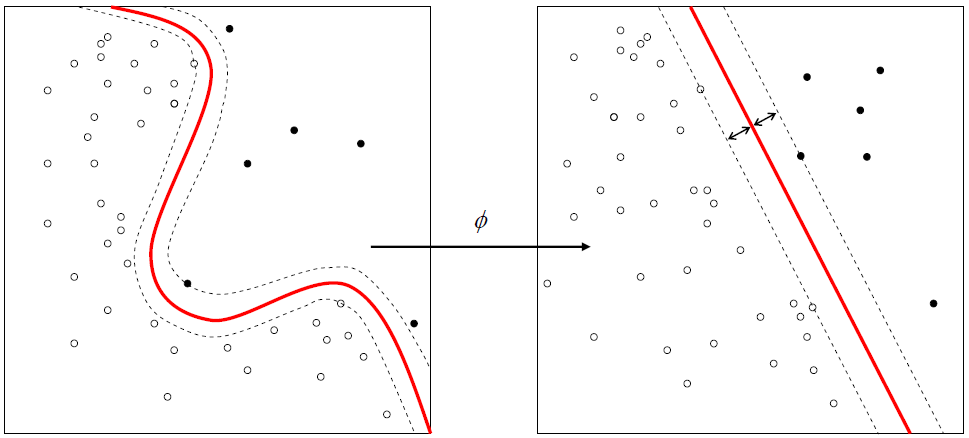
Python ile yaptığımız Kernel SVM örneğini bu yazımızda R ile yapacağız.
Çalışma Dizinini Ayarlama, Veri Setini İndirme
Veri setini buradan indirebilirsiniz.
setwd('Calisma_Dizininiz')
dataset = read.csv('SosyalMedyaReklamKampanyası.csv', encoding = 'UTF-8')
Veri Seti Görünüm

Veriyi Anlamak
Yukarıda gördüğümüz veri seti beş nitelikten oluşuyor. Veri seti bir sosyal medya kayıtlarından derlenmiş durumda. KullaniciID müşteriyi belirleyen eşsiz rakam, Cinsiyet, Yaş, Tahmini Gelir yıllık tahmin edilen gelir, SatinAldiMi ise belirli bir ürünü satın almış olup olmadığı, hadi lüks araba diyelim. Bu veri setinde kolayca anlaşılabileceği gibi hedef değişkenimiz SatinAldiMi’dir. Diğer dört nitelik ise bağımsız niteliklerdir. Bu bağımsız niteliklerle bağımlı nitelik (satın alma davranışının gerçekleşip gerçekleşmeyeceği) tahmin edilecek.
Bağımsız değişkenlerin hepsini analizde kullanmayacağız. Analiz için kullanacağımız nitelikleri seçelim:
dataset = dataset[3:5]
3,4 ve 5’inci nitelikleri alacağımız için parantez içine 3:5 dedik. Yeni veri setimizi de görelim:
Hedef niteliğimiz SatinAldiMi niteliğini factor yapalım.
dataset\$SatinAldiMi = factor(dataset\$SatinAldiMi, levels = c(0, 1))
Veri Setini Eğitim ve Test Olarak Ayırmak
Aynı sonuçları almak için random değeri belirlemek için bir sayı belirliyoruz. 123. split fonksiyonu ile hangi kayıtların eğitim hangi kayıtların test grubunda kalacağını damgalıyoruz. Sonra bu damgalara göre ana veri setinden yeni eğitim ve test setlerini oluşturuyoruz.
library(caTools) set.seed(123) split = sample.split(dataset\$SatinAldiMi, SplitRatio = 0.75) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)
Yaş ile maaş aynı ölçekte olmadığı için bu nitelikleri normalizasyona tabi tutuyoruz.
training_set[-3] = scale(training_set[-3]) test_set[-3] = scale(test_set[-3])
Kernel SVM Modeli Oluşturmak ve Eğitmek
R’ın SVM paketi olan paket e1071’i kullanacağım. Geliştiriciler galiba Türk’ün büyük zaferine ithafen paket adını 1071 vermişler (!). Şaka bir yana e1071 paket ismi geliştiricilerin birlikte çalıştıkları sınıfın adıdır. Paket içindeki svm nesnesini model oluşturmak için kullanacağız.
library(e1071) classifier = svm(formula = SatinAldiMi ~ ., data = training_set, type = 'C-classification', kernel = 'radial')
İlk parametremiz formülümüz, solda bağımsız değişkenimiz SatinAldiMi, sağda ise tüm bağımsız değişkenleri temsil eden noktamız. İkinci parametre kullanılacak veri seti ve doğal olarak eğitim seti olan training_set. Üçüncü parametremiz type, sınıflandırma yaptığımız için C-classification. SVM’in regresyonu da var biliyorsunuz. Son parametremiz kernel, gaussian yöntemi kullanmak için radial. Kernel SVM’in de mantığı zaten doğrusal ayrılamayan sınıfları doğrusal olmayan ayraç ile ayırmaktı.
Test Seti ile Tahmin Yapmak
Eğittiğimiz modeli ve test setini kullanarak tahmin yapalım ve bakalım modelimiz ne kadar isabetli sınıflandırma yapıyor.
y_pred = predict(classifier, newdata = test_set[-3])
Hata Matrisini Oluşturmak
cm = table(test_set[, 3], y_pred) cm 0 1 0 58 6 1 4 32
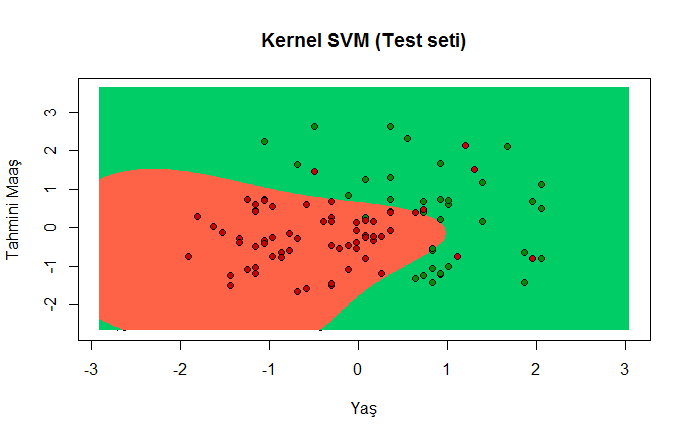
Hata matrisinde gördüğümüz gibi 90 doğru, 10 tane yanlış sınıflandırma yapılmış. Bunlardan 6 tanesine almamışken alır, 4 tanesine de almışken almaz demiş. Eh ne yapalım yani kadı kızında da bu kadar kusur olsun 🙂
Eğitim Seti için Grafik Çizmek
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yas', 'TahminiMaas')
y_grid = predict(classifier, newdata = grid_set)
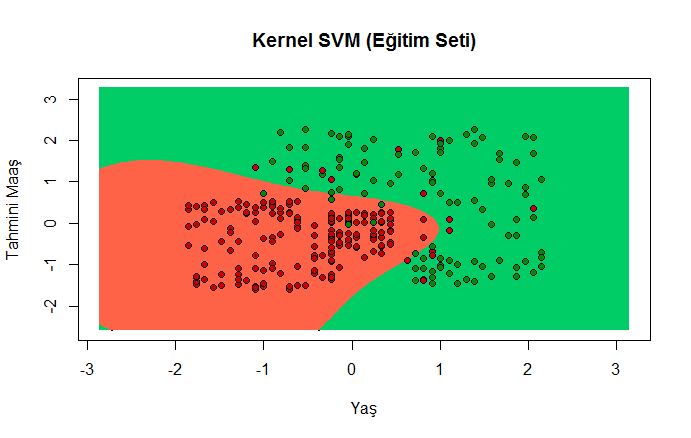
plot(set[, -3],
main = 'Kernel SVM (Eğitim Seti)',
xlab = 'Yaş', ylab = 'Tahmini Maaş',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Test Seti için Grafik Çizmek
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yaş', 'Tahmini Maaş')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, -3], main = 'Kernel SVM (Test seti)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
e1071 paket ismi geliştiricilerin birlikte çalıştıkları sınıfın adıdır.
Dr. Şebnem Özdemir
Çok teşekkürler Şebnem Hanım. Ben de tahmin etmiştim 1071 ile ilgili olmadığını 🙂 Katkınızla gerekli düzeltmeyi yaptık.