

Kümeleme notlarına devam ediyoruz. Serinin bir önceki yazısında kümeleme kavramına giriş yapmış uzaklık ve benzerlikten bahsetmiştik. Bu yazımızda K-Ortalamalar kümeleme tekniğine giriş yapacağız. Adım adım K-ortalamalar kümeleme algoritması nasıl çalışır bakalım:
- Öncelikle kaç tane küme elde etmek istediğimizi belirtelim. Optimal küme sayısı bulma konusunda yazacağım sonra.
- Seçilen küme sayısı kadar rastgele bir küme merkezi (centroid) seçme.
- Seçilen bu küme merkezlerine en yakın noktaları bulmak ve ilgili kümeye atamak.
- Yeni bir küme merkezi hesaplamak.
- Yeni küme merkezine en yakın noktaları tekrar bulmak ve atamak.
- Üç ve beş arası maddeler herhangi bir hareket olmayana kadar devam eder.
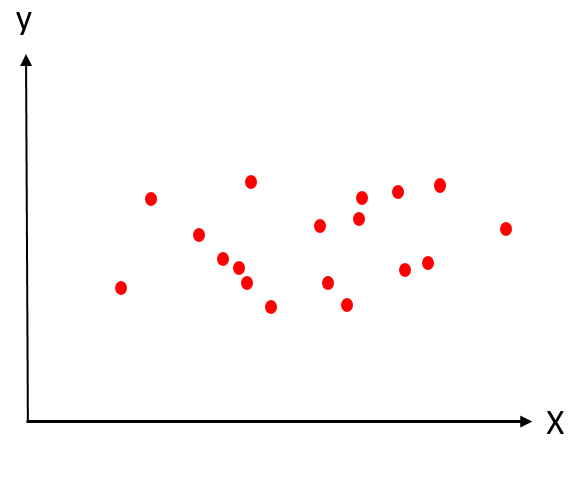
Elimizde yukarıda görülen veri seti olsun. X bağımsız değişken y ise bağımlı değişken olsun. Biz yukarıdaki veri setini kümelere ayıralım ve belirlediğimiz adımları uygulayalım:
1. Küme sayısını belirle:
Ben küme sayısını 2 olarak belirliyorum.
1. Rastgele iki küme merkezi belirle:
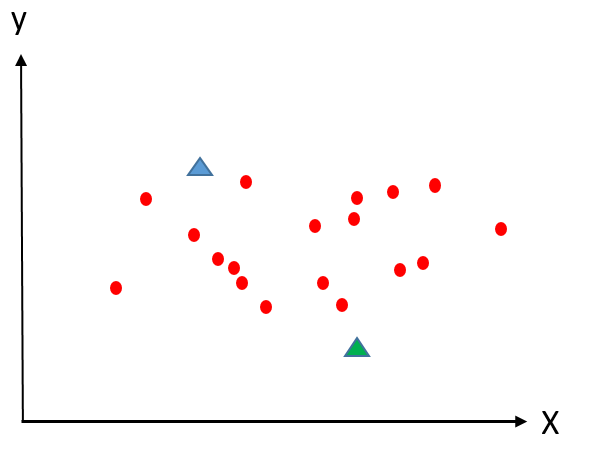
Mavi üçgen bir başlangıç küme merkezini, yeşil üçgen ise diğer başlangıç küme merkezi olsun.
3. Seçilen bu merkezlere en yakın noktaları bulmak:
Kabaca bu merkezlere en yakın noktaları bulalım. Bunun için basit bir geometrik yöntem kullanacağız.
4. Yeni küme merkezlerini hesaplamak
Küme merkezlerini tekrar hesaplayıp kaydırıyoruz.

5. Yeni küme merkezlerine göre noktaları tekrar kümelemek:
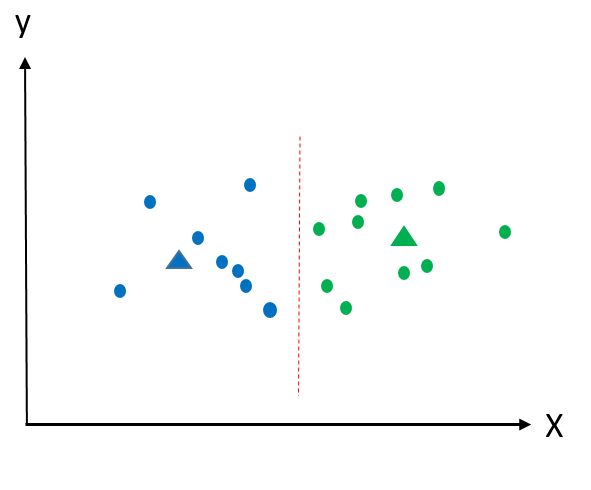
Yukarıda iki nokta yeşil kümede iken mavi kümeye geçti. Bu adımdan sonra yine yeni küme merkezleri hesaplanacak ve yeni küme merkezlerine göre noktalar yeniden kümelere atanacak ta ki herhangi bir hareket mümkün olmayana kadar. İşte bu nedenle başlangıçta küme merkezlerini rastgele seçmek çok mantıksız görünse bile çeşmeden dökülen suyun öyle veya böyle bir şekilde lavabo giderine ulaştığı gibi başlangıç küme merkezleri ne seçilirse seçilsin kümeler de kendilerine benzeyen noktalarla bir araya gelecektir.
Ancak başlangıç noktalarının seçimi algoritmayı belli bir yönde kümeleme modeli kurmaya dikte edebilir. Bu durum rastgele başlangıç tuzağı (random intitalization trap) olarak adlandırılıyor. k-means++ başlatma metodu (initialization method) ile tuzağın önüne geçilmeye çalışılmış.
Kapak: Michael Walter on Unsplash