
![]()
Merhabalar, bugünkü yazımda sizlere Özyinelemeli Sinir Ağlarından ve LSTM ile nasıl dolar kuru tahmini yapılacağından bahsedeceğim, yazının içeriği şu şekilde;
Özyinelemeli Yapay Sinir Ağları
- Konuşma Tanıma Örneği
Kaybolan Eğim(Vanishing Gradient)
- Uzun-Kısa Dönem Hafıza(LSTM)
- LSTM ile Dolar Tahmini
- Dolar Verisinin Alınması
- Veri Analizi ve Ön İşlemesi
- LSTM Modelinin Kurulması
- Sonuçlar
1 – Özyinelemeli Sinir Ağları
Bir filmin her noktasında ne tür bir olay olduğunu sınıflandırmak istediğinizi düşünün. Geleneksel bir sinir ağının filmdeki daha önceki olaylar hakkındaki muhakemesini daha sonra bilgilendirmek için nasıl kullanabileceği açık değildir. Özyinelemeli sinir ağları bu sorunu ele almaktadır. Bunlar, bilginin devam etmesine izin veren döngüler içeren ağlardır.

Konuşma Tanıma Örneği
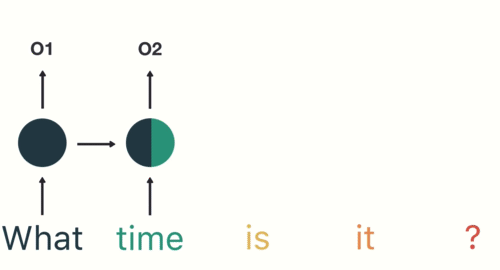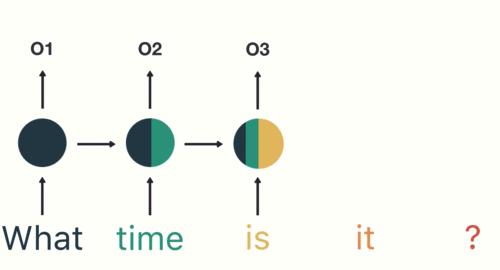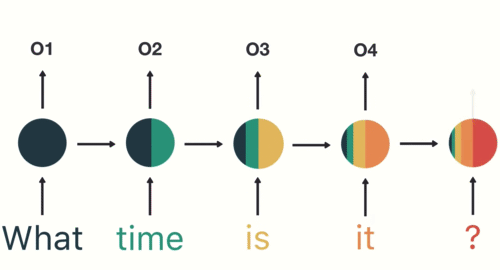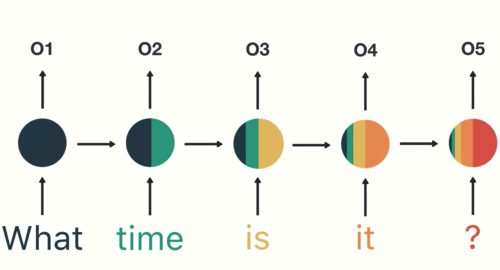
Yukarıdaki resimde de “What time is it?” Sorusunun kelime kaydedilip tek bir komuta döndürülecek.
2- Kaybolan Eğim(Vanishing Gradient)
Kaybolan eğim problemi, büyük zaman serisi verileriyle çalıştığımızda ortaya çıkar.
Bir sinir ağının eğitimi üç ana aşamaya sahiptir:
- İlk olarak, bir ileri geçiş yapar ve bir tahmin yapar.
- İkincisi, bir kayıp fonksiyonu kullanarak tahminleri gerçek değerlerle karşılaştırır.
- Kayıp fonksiyonu, ağın ne kadar kötü performans gösterdiğine dair bir tahmini bir hata değeri çıkarır.
- Son olarak, ağdaki her nöron için eğimleri hesaplayan geri yayılımı yapmak için bu hata değerini kullanır.
Eğim ne kadar büyükse, ayarlamalar o kadar büyür ve tersi de geçerlidir. Sorun da burada yatmaktadır. Geri yayılımı yaparken, bir katmandaki her nöron, eğim etkileriyle ilgili olarak, önceki katmandaki eğim değerini hesaplar. Bu nedenle, önceki katmanlara yapılan ayarlamalar küçükse, geçerli katmana yapılan ayarlar daha da küçük olacaktır.
- Bu, geri yayıldıkça eğimin üssel olarak küçülmesine neden olur.
- Daha önceki katmanlar, iç ağırlıklar son derece küçük eğimleriyle ayarlanmakta olduğu için, herhangi bir öğrenme yapamazlar.
- Bu, kaybolan eğim problemini doğurur.
Bunun çözümü için Uzun-kısa dönem hafıza özyinelemeli sinir ağları önerilmiştir.
3- Uzun-Kısa Dönem Hafıza(LSTM)
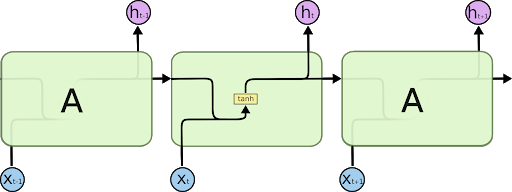
- Tüm özyinelemeli sinir ağları, sinir ağının özyineli modüllerinin bir zinciridir. Standart RNN’lerde, bu özyineli modül, tek bir tanh tabakası gibi çok basit bir yapıya sahip olacaktır.

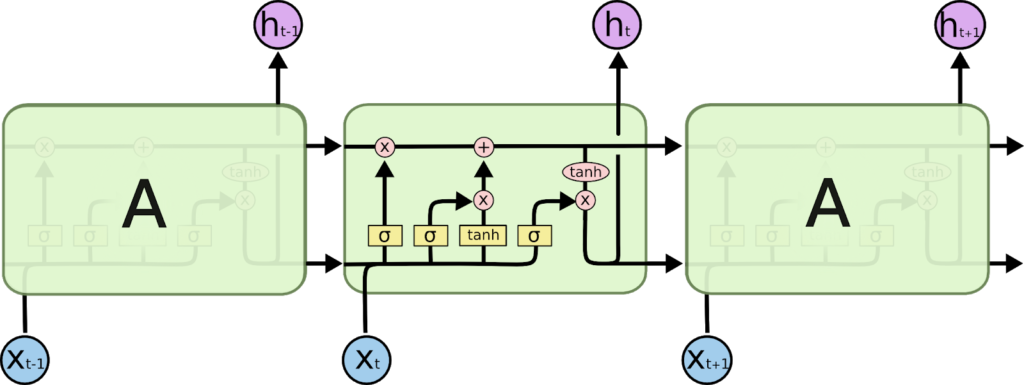
- LSTM’ler de bu zincir benzeri yapıya sahiptir, ancak özyineli modülün farklı bir yapısı vardır. Tek bir nöral ağ katmanına sahip olmak yerine dört tane var, çok özel bir şekilde etkileşime giriyor.
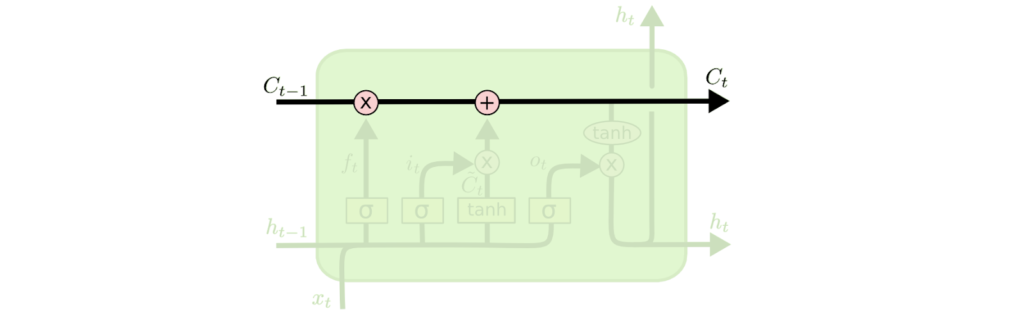
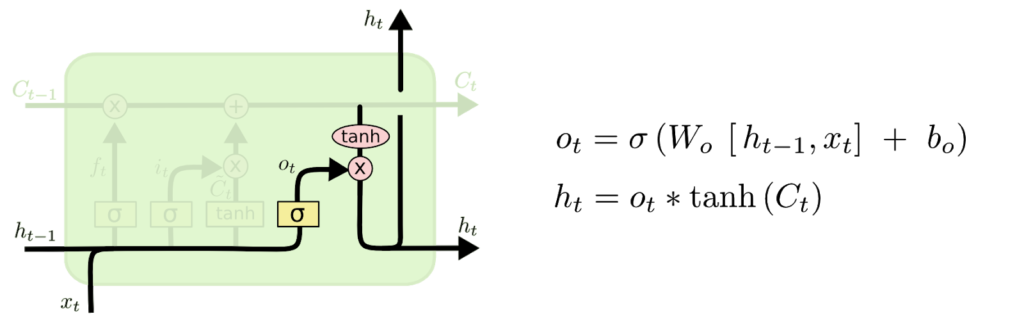
- LSTM’lerin anahtar kavramı, diyagramın üstünden geçen yatay çizgi olan hücre durumudur(cell state).
- LSTM, kapı olarak adlandırılan yapılar tarafından dikkatle düzenlenmiş, hücre durumuna bilgi çıkarma veya ekleme yeteneğine sahiptir.
- Kapılar, isteğe bağlı olarak bilginin iletilmesini sağlayan bir yoldur. Sigmoid nöral ağ katmanından ve nokta tabanlı çarpma işleminden oluşurlar.
- Sigmoid katman, her bileşenin ne kadarının geçmesine izin verileceğini açıklayan 0 ile 1 arasındaki sayıları çıkarır. 0 değeri, “hiçbir şey kalmasın” anlamına gelirken, 1 değeri “herşey içinden geçsin!” anlamına gelir.
- Bir LSTM, hücre durumunu korumak ve kontrol etmek için bu kapılardan üç tanesine sahiptir.
- LSTM’mizdeki ilk adım, hücre durumundan hangi bilgileri atacağımıza karar vermektir. Bu karar “unutturucu geçit katmanı(forget gate layer)” adı verilen sigmoid bir katman tarafından yapılmıştır.
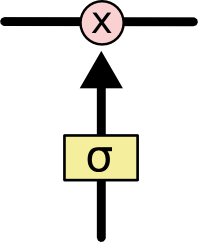
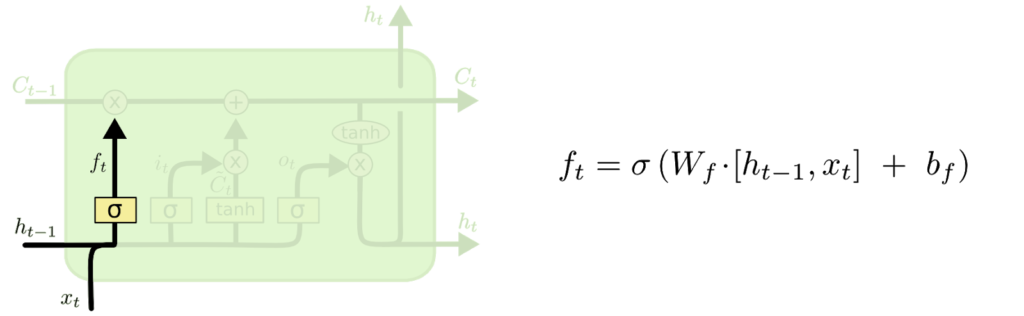
- Bir sonraki adım, hücre durumunda hangi yeni bilgileri saklayacağımıza karar vermektir.
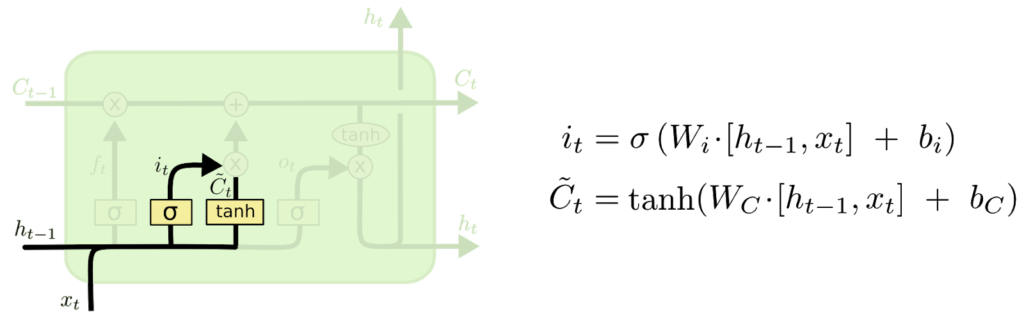
- Bunun iki bölümü var. İlk olarak, “giriş kapısı katmanı” olarak adlandırılan bir sigmoid katman, hangi değerleri güncelleyeceğimize karar verir.
- Ardından, bir tanh tabakası, duruma eklenebilecek yeni aday değerlerin bir vektörünü oluşturur.
- Bir sonraki adımda, bu ikisini bir güncelleme oluşturmak için birleştireceğiz.
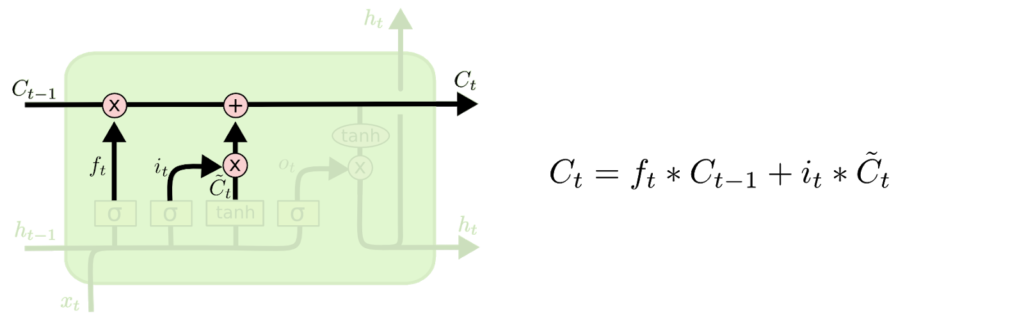
- Artık eski hücre durumunu yeni hücre durumuna güncellemenin zamanı geldi.
- Önceki adımlar zaten ne yapılacağına karar verdi, şimdi bunu gerçekten yapmamız gerekiyor.
- Son olarak, çıktıya karar vermeliyiz.
- Bu çıktı, hücre durumumuza dayalı olacak, ancak filtrelenmiş bir sürüm olacak.
- İlk olarak, çıkış yapacağı hücre durumunun hangi bölümlerine karar vereceğine karar veren bir sigmoid katman çalıştırıyoruz.
- Daha sonra, hücre durumunu tanh yoluyla koyarız (değerleri -1 ve 1 arasında olacak şekilde) ve sigmoid kapının çıktısıyla çoğaltırız, böylece yalnızca karar verdiğimiz parçaları çıkarmış oluruz.
4- LSTM ile Dolar Tahmini
Evet şimdi kodlama kısmına geçelim, Buradan önce bilgisayarınızda bulunması gereken bazı kütüphaneler var. Bunları indirmek için komut satırınıza(cmd) şu komutları yazabilirsiniz.
pip install keras pip install plotly pip install tensorflow
Dolar Verisinin Hazırlanması
Veriyi indirmek için öncelikle buraya TIKLAYIN.

Ardından resimdeki ayarları yaptıktan sonra rapor oluştur’a tıklayın.

Excel’e aktara tıklayın ve veriniz bilgisayarınıza inecek.
Veri Analizi ve Ön İşleme
Öncelikle Çalışmada kullanacağımız kütüphaneleri import edelim.
import warnings
import itertools
from math import sqrt
from datetime import datetime
from numpy import concatenate
import numpy as np
import pandas as pd
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import LSTM, Bidirectional, GRU
from keras.layers.recurrent import LSTM
from sklearn.utils import shuffle
import plotly.offline as py
import plotly.graph_objs as go
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
py.init_notebook_mode(connected=True)
plt.style.use('fivethirtyeight')# Datayı Yükleyelim
data = pd.read_excel('usd_alis.xlsx', date_parser=[0])
# İlk 5 Satır
data.head()
#Çıktımız
tarih usd_alis
0 03-01-2005 1.3363
1 04-01-2005 1.3383
2 05-01-2005 1.3427
3 06-01-2005 1.3775
4 07-01-2005 1.4000Tarihi index haline getireceğiz.
#Datetime Haline Getirilmesi data['tarih'] = pd.to_datetime(data.tarih, format='%d-%m-%Y') #İndex'e Alınması data.index = data.tarih
Bildiğiniz gibi cumartesi pazar piyasalar kapalı ve burada da o yüzden o datalar NaN gözüküyor. Onları dolduralım.
#Burada interpolate fonksiyonunu kullanıyoruz. Haftaya bakarak lineer olarak dolduruyor. data['usd_alis'].interpolate(method='linear', inplace=True)
Evet şimdi doların 2005-2018 Eylül arasındaki değişimine bakalım.
fig = plt.figure(figsize=(15,8))
data.usd_alis.plot(label='usd alış')
plt.legend(loc='best')
plt.title('Daily Exchange Rates, Buy', fontsize=14)
plt.show()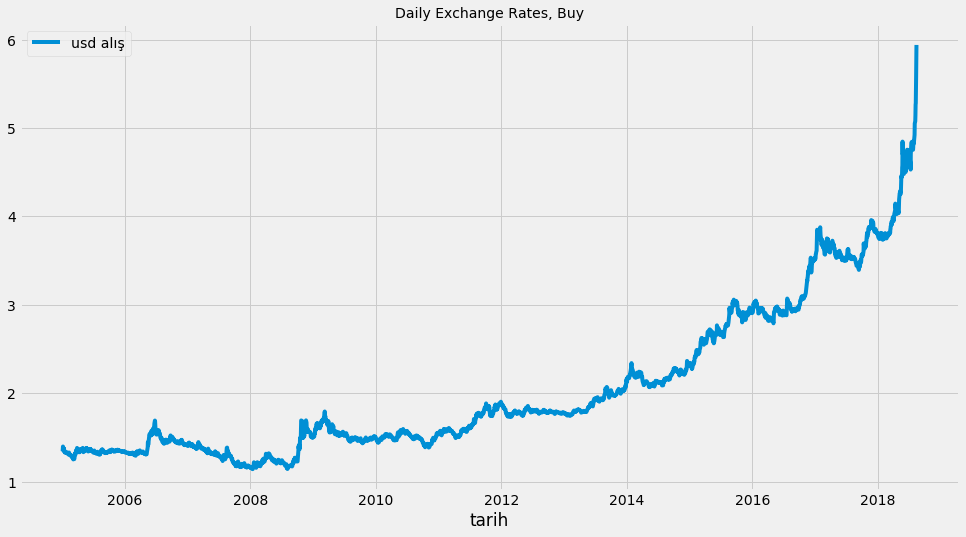
Veriyi Deep Learning Modellerine ve LSTM’e vermeden önce 0-1 arasında scale etmeliyiz. Şimdi onu yapalım.
values = data['usd_alis'].values.reshape(-1,1)
values = values.astype('float32')
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(values)
# Birkaç Değere Bakalım
dataset[0:5]
#Çıktı
array([[0.0399249 ],
[0.04034211],
[0.0412599 ],
[0.048519 ],
[0.05321236]], dtype=float32)Şimdi ise veriyi eğitim ve test diye 2 ye böleceğiz. Burada %60 Train %40 Test şeklinde bir bölme yapacağız.
# %60 Train % 40 Test
TRAIN_SIZE = 0.60
train_size = int(len(dataset) * TRAIN_SIZE)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
print("Gün Sayıları (training set, test set): " + str((len(train), len(test))))Şimdi ise veri setimizi adım adım okuması için okunabilir bir hale getireceğiz. Buradaki mantık son güne bakıp diğer günü tahmin etmesi şeklinde olacak.
def create_dataset(dataset, window_size = 1):
data_X, data_Y = [], []
for i in range(len(dataset) - window_size - 1):
a = dataset[i:(i + window_size), 0]
data_X.append(a)
data_Y.append(dataset[i + window_size, 0])
return(np.array(data_X), np.array(data_Y))# Verisetlerimizi Oluşturalım
window_size = 1
train_X, train_Y = create_dataset(train, window_size)
test_X, test_Y = create_dataset(test, window_size)
print("Original training data shape:")
print(train_X.shape)
# Yeni verisetinin şekline bakalım.
train_X = np.reshape(train_X, (train_X.shape[0], 1, train_X.shape[1]))
test_X = np.reshape(test_X, (test_X.shape[0], 1, test_X.shape[1]))
print("New training data shape:")
print(train_X.shape)Şimdi ise LSTM Modelimizi kuralım.
def fit_model(train_X, train_Y, window_size = 1):
model = Sequential()
# Modelin tek layerlı şekilde kurulacak.
model.add(LSTM(100,
input_shape = (1, window_size)))
model.add(Dense(1))
model.compile(loss = "mean_squared_error",
optimizer = "adam")
#30 epoch yani 30 kere verisetine bakılacak.
model.fit(train_X,
train_Y,
epochs = 30,
batch_size = 1,
verbose = 1)
return(model)
# Fit the first model.
model1 = fit_model(train_X, train_Y, window_size)Şimdi ise sonuçlarımızı ölçüp, nasıl gözüktüğüne bakalım.
def predict_and_score(model, X, Y):
# Şimdi tahminleri 0-1 ile scale edilmiş halinden geri çeviriyoruz.
pred = scaler.inverse_transform(model.predict(X))
orig_data = scaler.inverse_transform([Y])
# Rmse değerlerini ölçüyoruz.
score = math.sqrt(mean_squared_error(orig_data[0], pred[:, 0]))
return(score, pred)
rmse_train, train_predict = predict_and_score(model1, train_X, train_Y)
rmse_test, test_predict = predict_and_score(model1, test_X, test_Y)
print("Training data score: %.2f RMSE" % rmse_train)
print("Test data score: %.2f RMSE" % rmse_test)Çıktıları ise şu şekilde ;
- Training data score: 0.03 RMSE
- Test data score: 0.12 RMSE
Şimdi bunları görselleştirelim.
# Öğrendiklerinini tahminletip ekliyoruz.
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:, :] = np.nan
train_predict_plot[window_size:len(train_predict) + window_size, :] = train_predict
# Şimdi ise testleri tahminletiyoruz.
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict) + (window_size * 2) + 1:len(dataset) - 1, :] = test_predict
# Plot'u oluşturalım.
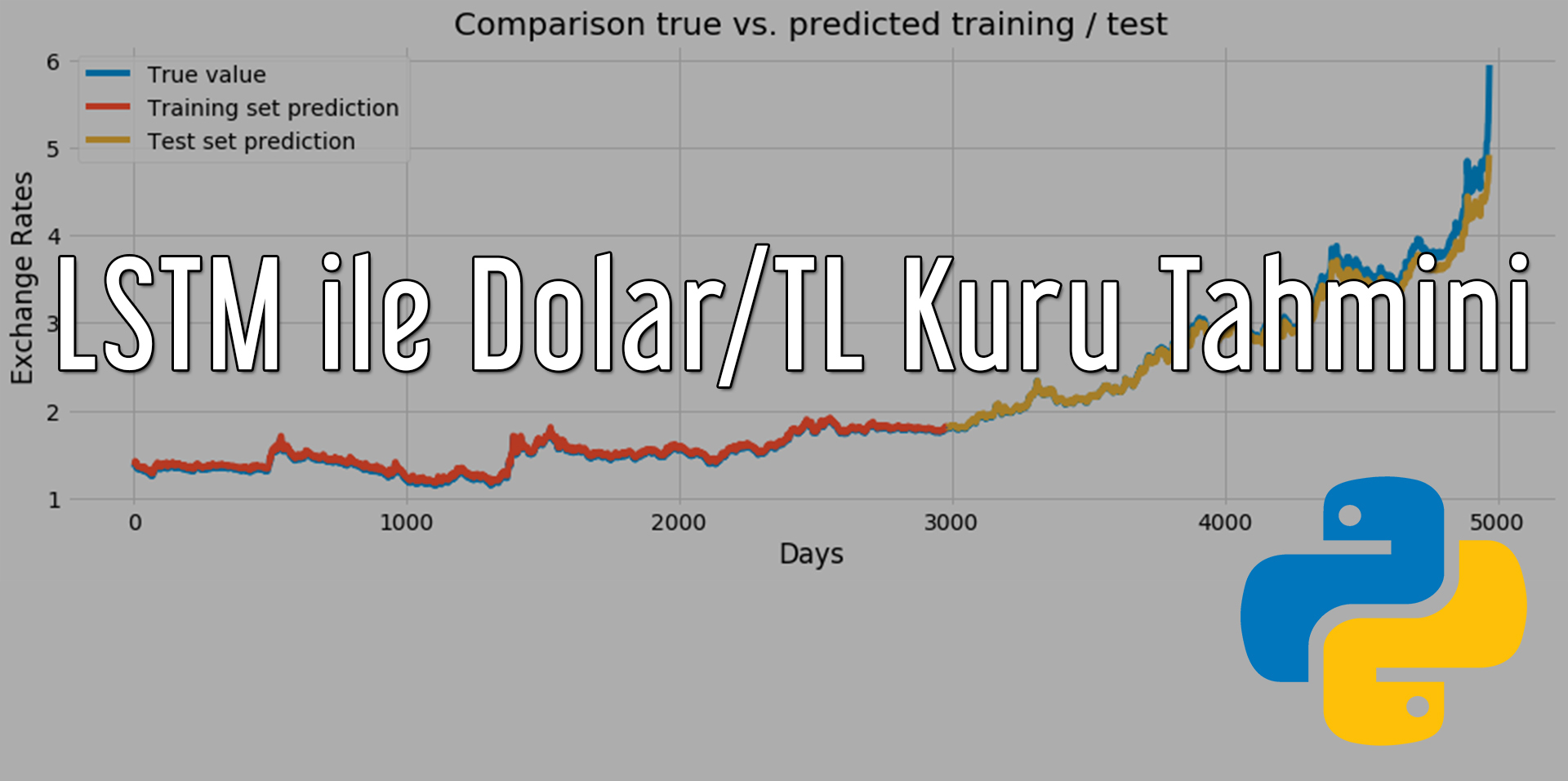
plt.figure(figsize = (15, 5))
plt.plot(scaler.inverse_transform(dataset), label = "True value")
plt.plot(train_predict_plot, label = "Training set prediction")
plt.plot(test_predict_plot, label = "Test set prediction")
plt.xlabel("Days")
plt.ylabel("Exchange Rates")
plt.title("Comparison true vs. predicted training / test")
plt.legend()
plt.show()
Sonuçlar şu şekilde olacak;
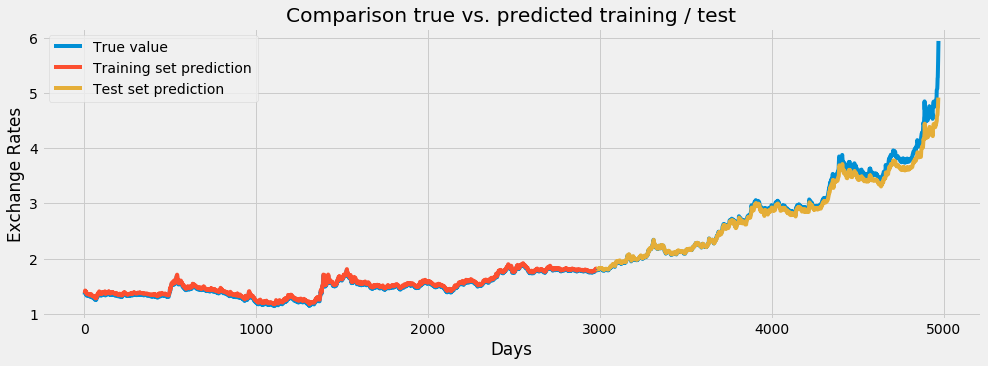
Gördüğünüz gibi gayet iyi şekilde tahminleyebiliyoruz. Hatta Ekonomik krizi bile tam olmasa bile öngörebiliyoruz. Burada 2-3 gün öncesine bakarak sonraki gün tahminlenebilir vb. gibi değişik parametreler ile sizde kendi bilgisayarınızda deneyebilirsiniz.
Buraya kadar gelip okuduğunuz için teşekkür ederim. Merak ettiklerinizi yorumlarda yazmayı unutmayın.
Kaynakça
- Murat ÖZTÜRKMEN ‘in LSTM Notları
- https://towardsdatascience.com/using-lstms-to-forecast-time-series-4ab688386b1f
- Nando de Freitas’ın LSTM Kursu: https://www.youtube.com/watch?v=56TYLaQN4N8
- Tanımlar: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- İshak DÖLEK’in LSTM Notları Çevirisi
YATIRIM TAVSİYESİ DEĞİLDİR.
Merhaba,
değerli bilgiler için teşekkürler öncelikle. Çok fazla programlama bilgisi olmayan birisi olarak senin çalışmanı baz alarak bir çalışma yapmak istedim, karşıma çıkan birkaç sorunu aktarmak istiyorum. Belki yazılarında bu detaylara yer vererek deneme yapacakların zorlanmasını engelleyebilirsin.
“pip install tensorflow” hata aldım, bu eklenti versiyon 3.6.x e kadar destekliyormuş, bende 3.7 yüklü olduğu için yükleyemedim. Bir süre araştırma yaptıktan sonra bu bilgiyi bularak yükleme yapabildim. Buradan yola çıkarak, program için kullanılan eklenti ve desteklediği python süremlerimi yada en azından senin kullandığın versiyonları bilgi olarak eklersen problem çözümü için okuyuculara yardımcı olacaktır.
İlk programdaki, “%matplotlib inline” satırı hata veriyor.. Sebebini bulamadım.
Bu çalışmanın bir video’su va ryoutube’da. Orada bir local bir web server üzerinde bazı işlemler yapılıyor, onun kurulumu da link oalrak verilebilir.
Merhabalar,
Teşekkürler, Bundan sonraki yazılarda buna dikkat edeceğim 🙂
Merhbab abi bu kodları birleştirip bir uygulama oluşturup kullanımımıza sokamaz mısın?
Hazırlanan model gerçek sonuçlara oldukça iyi oturmuş gibi görünse de maalesef döviz kuru tahmininde kullanılamaz. Çünkü test_eğitim verisinde zaten gerçekleşmiş veriler kullanılıyor bu sayede tahmin çok iyiymiş gibi görünüyor. Aynı model veri setinin dışında kullanılmaya çalışılsa sadece bir günü tahmin edebilirdi. Bu tahmin edilen bir gün de test kümesinde kullanılıp yeni tahminler yapılmaya çalışılsa bu seferde basit lineer regresyon gibi devamlı artan veya azan tahminler yapardı.
Nasıl bir yol izlenmeli. Bu konu çok ilgimi çekiyor. Nasıl bir yol izlenmeli? Öneriniz var mıdır?
Buarada test datası fit edilmeden önce zaten kur değerlerini görüyor. Ve model aşırı derecede overfitting olmuş. Malesef buradaki modelin tahmin yaptığından bahsedemeyiz. Zaman serisi analizleri şu an dünyanın her yerinde en zor görülen tahminleme problerinden zaten.
kesinlikle katılıyorum yvz arkadaşımıza, sadece gösteri amaçlı lstm tanıtma çalışması olmuş yine de eline sağlık.
Merhaba. Emeğinize teşekkürler öncelikle. Çok iyi bir anlatım olmuş. Benim sorum şu şekilde: Oluşturduğumuz modeli kaydedip her seferinde tekrar oluşturmadan yükleyip, yeni günleri de bu modele ekleyebilir miyiz? Teşekkürler. İyi çalışmalar.
Anlatım için teşekkürler. Yol gösterici bir çalışma.
Ben şunu merak ediyorum mesala en son data gününden sonra (futuredaki) 10 günü bu algoritma kaç olarak hesaplıyor mesala
İyi günler çok güzel bir çalışma yanlız bu dolar/tl kuru datasetine nasıl ve nerden ulaşabilirim mevcut fotoğraf silinmiş veya bir problemden ötürü görünmüyor.Teşekkür ederim 🙂
Merahbalar, Gelecek zamandaki tahminleri nasıl bulabiliriz??