

Merhaba. Bu yazımızda serinin 8 ve 9’uncu yazısında Python ile yaptığımız Polinom Lineer Regresyon uygulamasını R ile yapacağız. Çalışma diznini ayarlayıp veri setini indirelim. Veriyi buradan indirebilirsiniz:
setwd('Sizin_Calisma_Dizniniz')
dataset = read.csv('PozisyonSeviyeMaas.csv')
Veri setimizi görelim:
View(dataset)
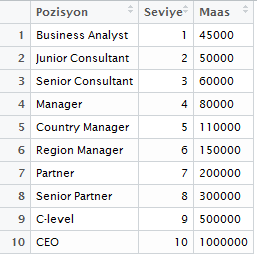
Veriyi Anlamak
Yukarıdaki tabloda niteliklerimizi görüyoruz:
Pozisyon: İş Ünvanı. Nitelik türü kategorik.
Seviye: İş ünvanlarını birbiri arasında maaş, astlık-üstlük vb. sıralayan nitelik. Nitelik türü nümerik.
Maas: Her bir pozisyondaki personelin yıllık maaşı. Nitelik türü nümerik.
Bu veri seti ve kuracağımız polinom model ile çözmeye çalışacağımız problem seviyesine göre bir personelin maaşını tahmin etmek olacak. Böylelikle y hedef değişkenimizin Maas, bağımsız değişken Seviye olduğunu çıkarabiliyoruz. Pozisyon seviye ile yakından ilgili bir nitelik ve seviyenin adlandırması gibi bir fonksiyonu olduğu için bu niteliği veri setinden çıkarıyoruz.
Veri seti çok az bir kayıttan (10 adet) oluştuğu için eğitim ve test olarak ayırmıyoruz. Sütun olarak kategorik değişken Pozisyonu çıkarıyoruz. İlk sütun Poizsyon olduğu için sadece 3 ve 3’üncü indeksli sütunu almak yeterli olur.
dataset = dataset[2:3]
Polinom regresyonu daha iyi anlamak için lineer regresyonu da yapıp karşılaştırma yapacağız. Şimdi lineer regresyon modelini oluşturalım.
lin_reg = lm(formula = Maas ~ ., data = dataset)
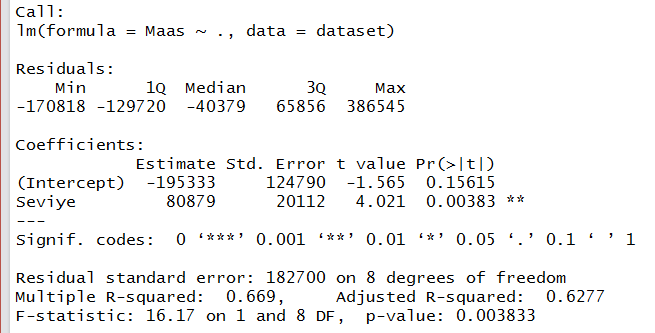
Tildanın(~) sağındaki nokta veri setinde bağımlı değişken haricindeki tüm değişkenler demektir. Elbette bu modelde sadece bir bağımsız değişken var o da seviye. Lineer modelin özeti:
summary(lin_reg)
Şimdi polinom modeli kuralım. Polinom modelin lineerden farkı; lineer modelde bağımsız değişken olarak sadece pozisyonu almıştık. Polinom modelde ise bağımsız değişken olarak pozisyonun ikici, üçüncü derecesini de modele dahil edeceğiz. Daha yüksek dereceler aşırı öğrenmeye sebep olabileceğinden modeli daha genellenebilir bir seviyede tutacak dereceyi almak iyi olur (2-3). Polinom modeli kurmadan önce 2. ve 3. derece bağımsız değişkenlerimizi de veri setine ekleyelim:
dataset\$Seviye2 = dataset\$Seviye^2 dataset\$Seviye3 = dataset\$Seviye^3 View(dataset)
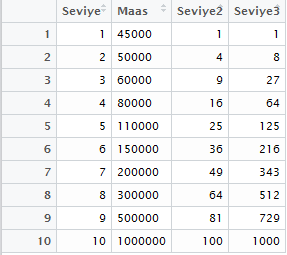
Yukarıdaki tabloda sağdaki iki yeni nitelik bizim ikinci ve üçüncü dereceden polinom bağımsız değişkenlerimizi oluşturdu. Şimdi lineer modeldeki kodların aynısını kullandığımızda polinom regresyon almış olacağız:
poly_reg = lm(formula = Maas ~ ., data = dataset) summary(lin_reg)
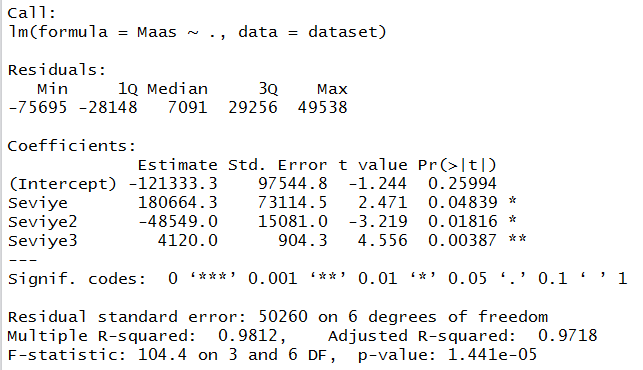
Gördüğümüz gibi yeni ürettiğimiz polinom nitelikler de modele anlamlı bir şekilde dahil oldu. Ayrıca lineer modele kıyasla düzeltilmiş R2 bayağı yükseldi (0.62’den 0.97’ye).
Lineer Regresyon Grafiği
Farkı daha iyi anlamak için önce lineer model grafiğini çizelim:
library(ggplot2)
ggplot()+
geom_point(aes(x = dataset\$Seviye, y = dataset\$Maas),
colour = 'red')+
geom_line(aes(x = dataset\$Seviye, y = predict(lin_reg, newdata = dataset)),
colour = 'blue')+
ggtitle('Lineer Regresyon')+
xlab('Seviye')+
ylab('Maas')
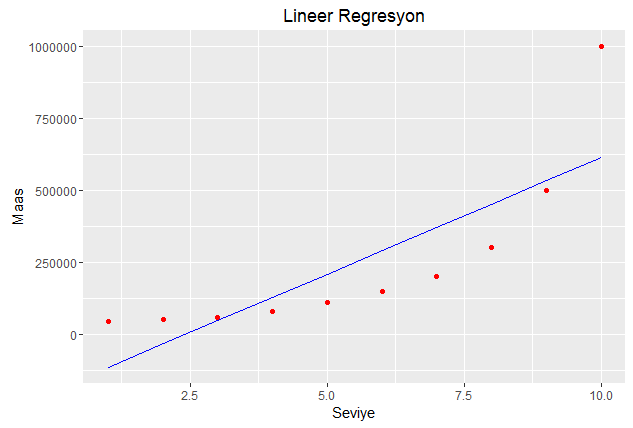
Lineer model grafiği yukarıda görülmektedir. Kodlarda kırmızıya boyadığım yere mutlaka dikkat etmek gerekir. Çünkü burada regresyon çizgisini çizdiğimiz için eğittiğimiz modelde geçek verinin tahmin değerlerini parametre olarak göndermemiz gerekiyor. Grafikten gördüğümüz gibi lineer regresyon doğrusu veri seti ile çok fazla uyumlu değil. Şimdi polinom modelin grafiğini çizelim:
Polinom Regresyon Grafiği
ggplot()+
geom_point(aes(x = dataset\$Seviye, y = dataset\$Maas),
colour = 'red')+
geom_line(aes(x = dataset\$Seviye, y = predict(poly_reg, newdata = dataset)),
colour = 'blue')+
ggtitle('Polinom Regresyon')+
xlab('Seviye')+
ylab('Maas')
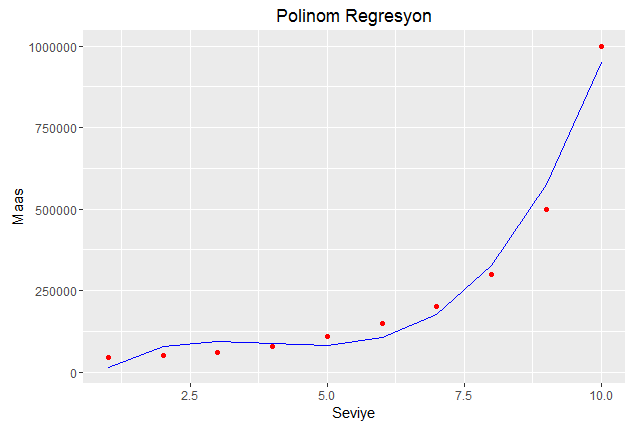
Grafikten gördüğümüz gibi polinom regresyon veriye daha fazla uyum sağladı. Şimdi 6.7 seviyesinde birinin maaşını tahmin edelim bakalım hangi model daha gerçeğe yakın sonuç verecek?
Lineer model ile tahmin:
predict(lin_reg, data.frame(Level = 6.5)) 330378.8
Polinom model ile tahmin:
predict(poly_reg, data.frame(Level = 6.5, + Level2 = 6.5^2, + Level3 = 6.5^3, + Level4 = 6.5^4)) 158862.5
Gerçek veri setinden 6. seviyenin 150.000, 7. seviyenin 200.000 TL’lik maaşa karşılık geldiğini biliyoruz. Seviye 6.5 ikisinin arasında bir yer. Sonuçlara baktığımızda polinom modelimiz lineer modele göre çok daha yüksek bir doğrulukta tahmin gerçekleştirdi.