

![]()
Python ile Hipotez Testleri yazı serimin 2.kısmına hoş geldiniz. Bu bölümde size parametrik olmayan hipotez testlerinden bahsedeceğim. Eğer bu yazı serisinin ilk kısmını okumadıysanız bu linkten erişebilirsiniz:
https://veribilimiokulu.com/python-ile-hipotez-testleri-parametrik-testler-bolum-1-3/
Parametrik olmayan testler, anakütle ile ilgili hiçbir varsayımda bulunmayan testlerdir. Değişkenlerin ölçeklerinin ad (nominal), sıra (ordinal) veya aralık (interval) olması durumunda tercih edilirler. Parametrik testlerin uygulanamadığı durumlarda rahatlıkla kullanılabilirler ve çok sorunlu bir veri kümesinde bile analiz yapılmasına olanak sağlarlar.
Mann – Whitney U Testi
Independent Sample T-Testinin Non-Parametrik alternatifidir. Genelde aynı populasyondan gelen iki örneklemin ortalamasını karşılaştırır ve iki örneklemin ortalamalarının eşit olup olmadığını inceler. Verinin ordinal(sıralı) olduğu durumlarda kullanılır. Mann – Whitney U testi için yokluk hipotezimiz “örneklem dağılımları birbirine eşittir.” iken, alternatif hipotezimiz “örneklem dağılımları birbirine eşit değildir” şeklindedir. Varsayımları şu şekildedir:
- Sürekli yada sıralı olan bir tane bağımlı değişken olmalı
- İki kategorik, bağımsız gruptan oluşan bir bağımsız değişken olmalı
- Gözlemler bağımsız olmalı
- Bağımsız değişkenin her iki grubu için puan dağılımının aynı şekilde sahip olup olmadığının belirlenmesi lazım
Örneğimizde ise mtcars veri setini kullanacağız. Araştırmak istediğimiz şey ise galon başına yaptığı mil ile şanzıman tipinin dağılımlarının aynı olup olmadığıdır.
H0: Galon başına yaptığı mil ile şanzıman tipinin dağılımlarının aynıdır.
Önce verimizi yükleyelim
mtcars = pd.read_csv("mtcars.csv")
Daha sonrada testimizi çalıştıralım.
stat, p = stats.mannwhitneyu(mtcars[mtcars["am"] == 1]["mpg"], mtcars[mtcars["am"] == 0]["mpg"])
Burda görüldüğü gibi “mpg” değişkenini, “am” değişkeninin her iki kategorisine göre ayrılmıştır.
Şimdi ise test sonuçlarımızı bir tabloya aktarıp sonuçları inceleyelim.
data = {'Test Statistic': [stat],
'p-Value': [p]}
result = pd.DataFrame(data)
result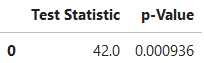
Görüldüğü gibi p < 0.05’tir. H0 hipotezini reddederiz. Yani şanzıman tipi, galon başına yaptığı mil miktarını etkiliyor.
Wilcoxon Signed-Rank Test
Paired Sample T-Testinin Non-Parametrik karşılığıdır. Aynı katılımcıdan gelen iki grup skoru karşılaştırılır. Wilcoxon Sign – Rank Testi için yokluk hipotezimiz “örneklem dağılımları birbirine eşittir.” iken, alternatif hipotezimiz “örneklem dağılımları birbirine eşit değildir” şeklindedir. Varsayımları şu şekildedir:
- Bağımlı değişken sürekli yada sıralı olmalı
- İki kategorik, “ilişkili grup” yada “eşleşmiş çift”ten oluşan bir bağımsız değişken olmalı
- İlgili iki grup arasındaki farklılıkların dağılımı simetrik olmalıdır.
Örneğimizde ise “immer” datası ile çalışacağız. immer datası bize 1931 ile 1932 yılları arasında aynı bölgedeki arpa verimini gösteriyor. Araştırmak istediğimiz şey ise 1931 ile 1932 yılları arasındaki verimin dağılımının aynı olup olmadığıdır.
H0: 2 yıla ait arpa verimlerinin dağılımları aynıdır.
Önce verimizi yükleyelim.
immer = pd.read_csv("immer.csv")
Daha sonra testimizi çalıştıralım.
stat, p = stats.wilcoxon(immer["Y1"], immer["Y2"])
Şimdi ise test sonuçlarımızı bir tabloya aktarıp sonuçları inceleyelim.
data = {'Test Statistic': [stat],
'p-Value': [p]}
result = pd.DataFrame(data)
result![]()
p < 0.05 olduğu için H0 hipotezini red ederiz. Yani iki yıl arasında arpa veriminde fark vardır.
Kruskal Wallis Testi
One-Way ANOVA testinin Non-Parametrik karşılığıdır. İkiden fazla grubun ölçümlerinin karşılaştırılmasında kullanılan bir yöntemdir. Kruskal Wallis testinin yokluk hipotezi “bütün örneklem dağılımları birbirine eşittir.” iken, alternatif hipotezimiz “bir veya daha fazla örneklem dağılımı eşit değildir.” şeklindedir. Varsayımları şu şekildedir:
- Bağımlı değişken; sıralı, oran yada aralık olmalı
- Bağımsız değişekn iki veya daha fazla bağımsız gruptan oluşmalı
- Gözlemler bağımsız olmalı
- Bütün gruplar aynı dağılım şekline sahip olmalı
Örneğimizde ise airquality datası ile çalışacağız. Bu datada New York’ta 1973 yılında 5 aylık süre ile ölçülen hava kalitesine dair veriler mevcuttur. Bizim burda araştırmak istediğimiz şey ise Mayıs ayından Eylül ayına kadarki aylık ozon yoğunluğunun bu 5 aylık süre zarfında aynı dağılımı gösterip göstermediğidir.
H0: Aylık ozon yoğunluğu aynı dağılıma sahiptir.
Öncelikle verimizi yükleyelim. Ayrıca verimizde eksik gözlemleri satır bazında silelim.
airquality = pd.read_csv("airquality.csv")
airquality = airquality.dropna(axis = 0)
Daha sonra testimizi çalıştıralım.
stat, p = stats.kruskal(airquality[airquality["Month"] == 5]["Ozone"],
airquality[airquality["Month"] == 6]["Ozone"],
airquality[airquality["Month"] == 7]["Ozone"],
airquality[airquality["Month"] == 8]["Ozone"],
airquality[airquality["Month"] == 9]["Ozone"])Burada her bir ayın ozon verisini testimize ayrı ayrı ekledik.
Ve test sonuçlarımızı bir tabloya aktarıp sonuçları inceleyelim.
data = {'Test Statistic': [stat],
'p-Value': [p]}
result = pd.DataFrame(data)
result
p < 0.05 olduğu için H0 hipotezini red ederiz. Yani Mayıs ayından Eylül ayına kadarki Ozon yoğunluğu farklılık göstermiştir.
Friedman Testi
Tekrarlı ölçümlerde tek yönlü ANOVA testinin Non-Parametrik karşılığıdır. Eğer n < 30 ise bu test kullanılır. Bağımlı değişkenin sıralı olduğu durumlarda gruplar arasında farkları test eder. Friedman testinin yoklu hipotezi “k tane durum arasında fark yoktur.” iken, alternatif hipotezimiz “k tane durum arasında fark vardır.” şeklindedir. Varsayımları şu şekildedir:
- 3 veya daha fazla durumda ölçülmüş bir grup olmalı.
- Grup, populasyondan rasgle seçilmeli
- Bağımlı değişken, sıralı yada sürekli olmalı
- Örneklemin normal dağılmasına gerek yoktur
Örneğimizde ise anket verisi ile çalışacağız. Bu veride amfibi araştırmaları ile ilgili veriler vardır. Araştırmak istediğimiz şey ise yıldan dolayı amfibi sayılarında önemli bir farklılık olup olmadığıdır.
H0: Yıllar arasında fark yoktur.
Öncelikle verimizi yükleyelim.
survey = pd.read_csv("survey.csv")
Sonra testimizi çalıştıralım.
stat, p = stats.friedmanchisquare(survey["2004"],
survey["2005"],
survey["2006"])Ve test sonuçlarımızı bir tabloya aktarıp sonuçları inceleyelim.
data = {'Test Statistic': [stat],
'p-Value': [p]}
result = pd.DataFrame(data)
result
p < 0.05 olduğu için H0 hipotezini red ederiz. Yani yıllara göre amfibi sayısı farklılık göstermiştir.
Parametrik olmayan testlerin de sonuna geldik. Sonraki yazımızda görüşmek üzere, esen kalın…
Kaynak: https://machinelearningmastery.com/nonparametric-statistical-significance-tests-in-python/
Kaynak: http://www.akinanaliz.com/wilcoxon-isaretli-siralar-testi/