

![]()
R’da Basit Doğrusal Regresyon(Bağlanım) Çözümlemesi
Basit Regresyon(Bağlanım) Çözümlemesi iki değişken arasında bir ilişki modeli kurmak için kullanılan bir istatistiksel yöntemdir. Değişkenlerden biri bağımlı, diğeri ise bağımsız değişken olarak adlandırılır. Regresyon(Bağlanım) Çözümlemesi ile değişkenler arasındaki ilişkinin varlığı, eğer ilişki var ise bunun gücü hakkında bilgi edilinebilinir. Örnek vermek gerekirsek; Sınav sonucunun, çalışma süresiyle ilişkisi nedir? Boy uzunluğunun, kiloya etkisi nedir? Ya da sigara içme sıklığının, ilk kalp krizi geçirme yaşı nedir? Gibi soruların cevaplarını araştırmak istiyorsak eğer Basit doğrusal regresyon(bağlanım) çözümlemesi yapmalıyız.
Basit Doğrusal Regresyon(Bağlanım) Fonksiyonu :
E(Yi) = β0 + β1 Xi + €i
β0 = Kesişim terimidir. X = 0 iken E(Yi) ‘nin değeridir.
Β1 = Doğrunun eğimidir. X’deki birim değişimin E(Yi) ‘deki değişim oranını tanımlar.
€ = Hata terimidir. Modelde ki sapmaların ± ne kadar olacağını gösterir.
Genel bilgileri verdikten sonra hemen uygulamaya geçelim.
R’daki veri setlerinden çalışalım:
cars veri seti bizim uygulamamıza uygun gibi gözüküyor.
Hemen cars veri setini daha rahat incelemek adına şu komutu uygulayalım:
[toggle title=””]
> head(cars)
>attach(cars)
[/toggle]
head() fonksiyonu bize veri setinin ilk 6 satırını gösterir. attach() komutuda veriyi R’a işler.
Çıktı:
[toggle title=””]
> head(cars)
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
6 9 10
[/toggle]
Ve değişken tiplerine bakalım :
[toggle title=””]
>str(cars)
[/toggle]
str() komutu bize değişken tiplerini gösterir.
Çıktı:
[toggle title=””]
str(cars)
‘data.frame’: 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 …
$ dist : num 2 10 4 22 16 10 18 26 34 17 … [/toggle]
Yorumlayacak olursak 2 değişkenimiz ve her birinde 50 tane veri olduğunu söyleyebiliriz. Ayrıca speed ve dist değişkenlerimizin numeric değişken olduğunu da söyleyebiliriz.
Speed (x) bağımsız değişkeni arabanın hızını, dist(y) bağımlı değişkeni ise arabanın durma mesafesini gösterir.
Verinin dağılım grafiğini aşağıda ki fonksiyon yardımıyla çizelim:
[toggle title=””]
> plot(dist ~ speed, data = cars)
[/toggle]
Çıktı :
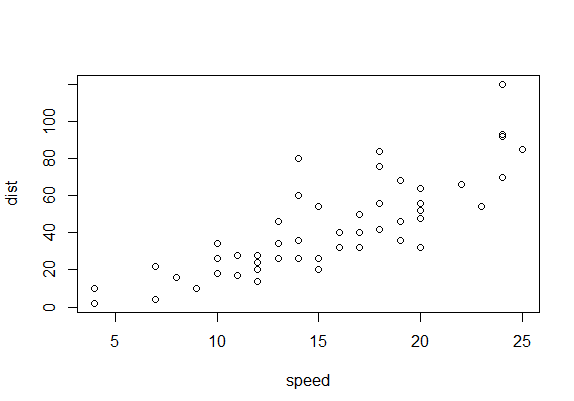
Yorum :
Grafikte doğrusal bir artış olduğunu gözlemleyebiliyoruz. Değerlerde kayma yok gibi gözüküyor.
Normallik grafiği çizdirmek için aşağıdaki fonksiyonu kullanalım:
[toggle title=””]
>qqnorm(dist,main = “Normallik Grafiği”)
[/toggle]
Ve bu grafiğe normallik çizgisi ekleyelim daha rahat yorumlayabilmek için
[toggle title=””]
>qqline(dist)
[/toggle]
Çıktı:
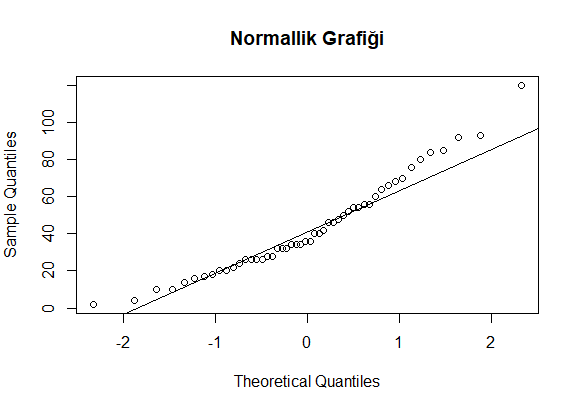
Yorum :
Verilerimizin genel olarak normallik çizgisi yüzeyinde dağıldığını yani normal dağıldığını söyleyebiliriz.
Şimdi regresyon(bağlanım) modelini kuralım:
dist = a + b*speed ± σ
bunu R’da kurmak için lm() fonksiyonunu kullanalım:
[toggle title=””]
> sonuc <- lm(dist ~ speed)
>summary(sonuc)
[/toggle]
Doğrusal modeli sonuç değişkenine atadık ve daha sonra modelin özet istatistiklerini görebilmek için summary() fonksiyonunu kullandık.
Çıktı:

Yorum :
İlk önce modelin anlamlı olup olmadığını test edelim bunun için anlamlılık hipotezini kuralım.
H0 : β = 0 (Model anlamlı değildir.)
H1 : β ≠ 0 (Model anlamlıdır.)
p – değeri = 1.49e-12 yani 0.05’ten çok küçük bir sayı olduğu H0 hipotezimiz reddedilir. Yani modelimiz anlamlı olduğunu söyleyebiliriz.
Ya da bunu F istatistiğiyle de söyleyebiliriz; F(0.05;1;48) ≈ 4.03’tür.
FHesap = 89.57 yani FHesap > F(0.05;1;48) olduğundan dolayı H0 hipotezimizi reddedilir. Buradan da modelimizin anlamlı olduğunu söyleyebiliriz.
Katsayıları yorumlayalım:
a = -17.5791
speed yani hız bağımlı değişkenimiz 0 olduğunda durma arabanın durma mesafesinin -17.5791 olduğunu söylüyor.
b = 3.9324
speed yani hız bağımlı değişkenimiz 1 birim arttığındaki değişimin 3.9324 olacağını söylüyor.
Katsayıların anlamlılıklarını test etmezsek doğru bir analiz yapmış olmayız bu yüzden anlamlılıklarını test edelim:
H0 : α = 0 (Sabit terim anlamlı değildir.)
H1 : α≠ 0 (Sabit terim anlamlıdır.)
Bu hipotezi de 2 yolla test edebiliriz.
- Student t testi yoluyla:
tHesap = -2.601.
t(0.025;48) ≈ 2.009
| tHesap| > t(0.025;48) olduğundan H0 hipotezimiz reddedilir yani Sabit terimin anlamlı olduğunu söyleyebiliriz.
- p- değeri yoluyla:
p =0.0123 < 0.05 H0 hipotezimiz reddedilir yani sabit terimin anlamlı olduğunu söyleyebiliriz.
H0 : β = 0 (Hızın, arabanın durma mesafesinde bir etkisi yoktur.)
H1 : β ≠ 0 (Hızın, arabanın durma mesafesinde bir etkisi vardır.)
Bu hipotezi de iki yolla test edebiliriz yukarıda test ettiğimiz gibi ama yukarıda test ettiğimizden bunu direkt p-değeri ile test edip yorumlayacağım.
p- değeri = 1.49 e-12 < 0.05 olduğundan H0 hipotezimiz reddedilir yani hızın, arabanın durma mesafesinde bir etkisi olduğunu söyleyebiliriz.
R2 = 0.6511
R2 yani çoklu belirtme katsayısı , bağımlı değişkendeki değişimin yüzde kaçının bağımsız değişkence açıklanabileceğini gösterir. Bu değer 0 ile 1 arasında değer alır ve bu değerin 1’e yakın olması bağımsız değişkenin bağımlı değişkeni iyi bir şekilde açıkladığı anlamına gelir ve bu da bizim istediğimiz bir durumdur. Bu bilgileri verdikten sonra çözümlememize dönecek olursak bizim çoklu belirtme katsayımız 0.6511 yani açıklamak gerekirse, arabanın durma mesafesindeki değişimin 0.6511’ini hız ile açıklanabildiğini söyleyebiliriz.