

Bu uzun yazı serisi “Tidy Text Mining with R” kitabının derlenmesinden ortaya çıkmıştır.
https://www.tidytextmining.com/
Her istatistiksel yöntem gibi temel amacımız, metin içerisinden anlamlı sonuçlar ortaya çıkarmaktır ve metin üzerinde yapılacak işlemlere de metin madenciliği adı verilir.
- Aşağıdaki kütüpaneler bu kitap içerisinde gerekli olan tüm kütüphanelerdir.
library(dplyr) # Veri Manipülasyonu
library(tidytext) # Düzenli Metin Araçları
library(janeaustenr) # Jane Austen'ın kitaplarını içerir
library(stringr) # Metin Manipülasyonu
library(ggplot2) # Veri Görselleştirme
library(gutenbergr) # Meta Verileri içerir
library(tidyr) # Veri Seti Manipüasyonu
library(scales) # Veri Görselleştirmesi için Standardize Fonksiyonları
library(wordcloud) # Kelime Bulutu
library(wordcloud2) # Kelime Bulutu (Fotoğraf üzerine kelime bulutu ile görselleştirmek istenirse)
library(reshape2) # Kelime Bulutu
library(igraph) # Ağ Analizi
library(ggraph) # Ağ Analizi
library(widyr) # Frekans ve Korelasyon İşlemleri
library(tm) # Matris İşlemleri
library(Matrix) # Matris İşlemleri
library(quanteda) # Metinsel Veriler için Kantitatif Analiz
library(topicmodels) # Konu Modellemesi1. Bölüm – Düzenli Veri Formatı
Düzenli metin madenciliğine (tidy text mining) göre metin içerisinde saklanan bilgi genelde tek bir kelimedir, ancak bu bilgi bir n-gram, cümle veya paragraf da olabilir. Tidytext paketinde metni tokenize yani kelimelere parçalayarak her bir satır başına bir terim (kelime) olacak şekilde bir formata dönüştürülür.
Tidytext paketi analiz yapacağı metnin her zaman düzenli bir biçimde olmasını beklemez. Tidytext, diğer metin madenciliği paketlerindeki bazı fonksiyonlarını da içerir. Bu fonksiyonlar yardımıyla makine öğrenmesi uygulamaları için metni döküman-terim matrisine (document-term matrix) dönüştürür ve oluşturulan modeller daha sonra ggplot2 paketi ile görselleştirmede ve yorumlanmada kullanılır.
1.1. Diğer Veri Yapıları ile Düzenli Metin Karşılaştırılması
Yukarıda belirtildiği gibi, düzenli metin formatı, satır başına bir ayıraç ile bir tablo olarak tanımlanır. Metin verilerinin bu şekilde yapılandırılması, düzenli veri ilkelerine uygun olduğu ve bir takım tutarlı araçlar ile manipüle edilebileceği anlamına gelir. Bu, metnin genellikle metin madenciliği yaklaşımlarında saklanma biçimleriyle çelişmektedir.
- String: Metin, R içinde bir dize olarak yani karakter vektörleri olarak saklanabilir ve çoğunlukla metin verileri ilk olarak bu formatta belleğe okunur.
- Corpus: Bu tür veri nesneleri genellikle ek metadata ve detay ile birlikte, açıklayıcı ham karakter dizilerini de içerir.
- Document-term matrix: Seyrek Matris (Sparse Matrix) dökümanlar topluluğu, her bir belge için bir satırı ve her bir terim için bir sütunu tanımlar, bu da Belge(veya Döküman)-Terim Matrisidir (Document-Term Matrix). Burada matristeki değer ya kelime sayısını ya da tf-idf olacaktır.
Bölüm 5’e kadar Korpus (Corpus) ve Belge-Terim Matrisini (Document-Term Matrix) keşfedeceğiz.
Metni düzenli bir formata dönüştürmenin temeline inelim.
1.2. unnest_tokens() Fonksiyonu
- Emily Dickinson’ın bir yazısı.
text <- c("Because I could not stop for Death -",
"He kindly stopped for me -",
"The Carriage held but just Ourselves -",
"and Immortality")
text## [1] "Because I could not stop for Death -"
## [2] "He kindly stopped for me -"
## [3] "The Carriage held but just Ourselves -"
## [4] "and Immortality"Elimizdeki metin bir karakter vektörüdür. Bunu düzenli bir metin hale getirmek için öncelikle bir veri çerçevesine (data frame) dönüştürmemiz gerekir.
library(dplyr)
text_df <- data_frame(line = 1:4, text = text)
text_df## # A tibble: 4 x 2
## line text
## <int> <chr>
## 1 1 Because I could not stop for Death -
## 2 2 He kindly stopped for me -
## 3 3 The Carriage held but just Ourselves -
## 4 4 and ImmortalityData frame haline getirdiğimiz metin henüz düzenli bir metin formatında değil. Elimizdeki metin birleşik kelimelerden (cümle) oluştuğu için metin içerisindeki en sık ortaya çıkan kelimeleri bulamayız.
Bu yüzden, cümleleri kelimelere parçalamamız gerekiyor. Bunu yaparken de her bir döküman için satır başına bir kelime olacak şekilde dönüştürmeliyiz.
Tokenization işlemi metni kelimelere ayırma işlemidir. Analizlerimizi yapabilmemiz için metni kelimelere bölmemiz gerekiyor.
Metni hem birer kelimelere ayırmak hem de toplu bir şekilde (ikişer, üçer …) ayırmak için tidytext kütüphanesinden unnest_tokens() fonksiyonu kullanılır.
library(tidytext)
text_df %>%
unnest_tokens(word, text)## # A tibble: 20 x 2
## line word
## <int> <chr>
## 1 1 because
## 2 1 i
## 3 1 could
## 4 1 not
## 5 1 stop
## 6 1 for
## 7 1 death
## 8 2 he
## 9 2 kindly
## 10 2 stopped
## 11 2 for
## 12 2 me
## 13 3 the
## 14 3 carriage
## 15 3 held
## 16 3 but
## 17 3 just
## 18 3 ourselves
## 19 4 and
## 20 4 immortalityunnest_tokens() içerisinde kullanılan iki temel argüman sütun isimleridir. Metni kelimelere parçaladıktan sonra oluşmasını istediğimiz değişken “word” olarak, fonksiyonun işlemini yapabilmesi için elimizdeki metnin değişkeni ise “text” olarak girilir.
Burada yaptığımız işlem, metni birer kelimelere parçalamaktı. İstenilen sayıda kelimelere parçalayabilirsiniz. İkişerli parçalamaya “Bigram”, üçerli parçalamaya ise “Trigram” denir.
unnest_tokens() işlemi ile;
- Her bir satırı birer kelimelere böldük. Ayrıca kelimelerin geldikleri satır numaraları gibi diğer sütunlar da korunur.
- Noktalama işaretleri çıkarıldı.
- Metin içerisinde büyük ve küçük harfler olduğundan kaynaklı aynı kelimeler eşleştirilemeyeceği için, büyük harfler küçük harflere dönüştürülür. Bu da diğer veri kümeleriyle karşılaştırmayı ve birleştirmeyi kolaylaştırır. Bu işlemi kapatmak için unnest_tokens’in içine (to_lower = FALSE) argümanını eklemeniz yeterli olacaktır.

Metin verilerinin bu formatta olması, dplyr, tidyr ve ggplot2 gibi standart araçları kullanarak metni işlememize ve görselleştirmemize olanak tanır.
1.3. Jane Austen ve Romanları
Jane Austen’ın 6 romanını janeaustenr paketini kullanarak R’da düzenli bir formata dönüştürelim.
Janeaustenr paketi, bu romanları tek satırlık bir formatta sunar. Bu satırın bir dizesi, fiziksel bir kitaptaki basılı bir satırın benzeridir. Bununla başlayarak aynı zamanda orijinal formattaki satırları takip etmek için mutate() komutunu kullanarak satır numaralarını(linenumber) ve bölümlerini(chapter) ekleyebiliriz.
library(janeaustenr)
library(dplyr)
library(stringr)
original_books <- austen_books() %>%
group_by(book) %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text, regex("^chapter [\\divxlc]",
ignore_case = TRUE)))) %>%
ungroup()
original_books## # A tibble: 73,422 x 4
## text book linenumber chapter
## <chr> <fct> <int> <int>
## 1 SENSE AND SENSIBILITY Sense & Sensibility 1 0
## 2 "" Sense & Sensibility 2 0
## 3 by Jane Austen Sense & Sensibility 3 0
## 4 "" Sense & Sensibility 4 0
## 5 (1811) Sense & Sensibility 5 0
## 6 "" Sense & Sensibility 6 0
## 7 "" Sense & Sensibility 7 0
## 8 "" Sense & Sensibility 8 0
## 9 "" Sense & Sensibility 9 0
## 10 CHAPTER 1 Sense & Sensibility 10 1
## # ... with 73,412 more rowsŞimdi elimizdeki veriyi düzenli bir veri kümesi olarak ele almak için unnest_tokens işlemi her bir satırı birer kelimeye parçalamamız gerekir.
library(tidytext)
tidy_books <- original_books %>%
unnest_tokens(word, text)
tidy_books## # A tibble: 725,055 x 4
## book linenumber chapter word
## <fct> <int> <int> <chr>
## 1 Sense & Sensibility 1 0 sense
## 2 Sense & Sensibility 1 0 and
## 3 Sense & Sensibility 1 0 sensibility
## 4 Sense & Sensibility 3 0 by
## 5 Sense & Sensibility 3 0 jane
## 6 Sense & Sensibility 3 0 austen
## 7 Sense & Sensibility 5 0 1811
## 8 Sense & Sensibility 10 1 chapter
## 9 Sense & Sensibility 10 1 1
## 10 Sense & Sensibility 13 1 the
## # ... with 725,045 more rowsunnest_tokens() fonksiyonu tokenizers paketini kullanarak orjinal veri setindeki metnin her bir satırını kelimelere parçalar. Böylelikle veriler satır başına bir kelime biçiminde olduğu için, dplyr gibi düzenli araçlarla kullanabiliriz.
Metin madenciliğinde genellikle duraklama kelimelerini (stop words) kaldırmamız gerekir. Duraklama kelimeleri metin içerisinde en fazla tekrar eden ama tek başına anlamı olmayan kelimelerdir. İngilizcedeki “the”, “of”, “in”, “to” ve benzeri kelimeleri düşünebiliriniz. Duraklama kelimelerini anti_join() ile veri setimizden çıkarabiliriz.
data(stop_words)
tidy_books <- tidy_books %>%
anti_join(stop_words)## Joining, by = "word"Tidytext paketi ile stop_words veri seti içerisinde üç sözlük (lexicon) bulunmakadır. Bunlar “SMART”, “snowball” ve “onix” olmak üzere üç sözlüktür. Bunları birlikte kullanabiliriz veya filter() ile belirli bir sözlüğü de ele alabiliriz.
dplyr kütüphanesindeki count() ile en fazla geçen kelimeleri bulalım.
tidy_books %>%
count(word, sort = TRUE)## # A tibble: 13,914 x 2
## word n
## <chr> <int>
## 1 miss 1855
## 2 time 1337
## 3 fanny 862
## 4 dear 822
## 5 lady 817
## 6 sir 806
## 7 day 797
## 8 emma 787
## 9 sister 727
## 10 house 699
## # ... with 13,904 more rowsJane Austen’in romanlarındaki en yaygın kelimelerin görselleştrilmesi.
library(ggplot2)
tidy_books %>%
count(word, sort = TRUE) %>%
filter(n > 600) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip()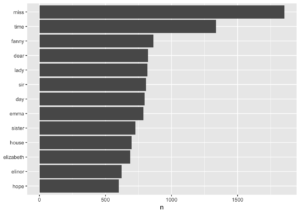
Not: austen_books() fonksiyonu bize analiz etmek istediğimiz metin türünü sağladı ama başka çalışmalarda ve başka verilerde, veriyi düzenlemek gerekebilir.
1.4. Kelime Frekansları
Bu bölümde “gutenbergr” paketi ile meta veri kümelerini göreceğiz.
Metin madenciliğinde yapılması gereken kelme frekanslarına bakmak ve diğer metinler ile karşılaştırma yapmaktır.
Jane Austen’in eserlerine sahibiz; karşılaştırmak için iki tane daha metin ele alalım. İlk olarak, 19. yüzyılın sonlarında ve 20. yüzyılın başlarında yaşayan HG Wells’in bazı bilim kurgu ve fantezi romanlarına bakalım. “The Time Machine”, “The War of the Worlds”, “The Invisible Man” ve “The Island of Doctor Moreau” kitaplarına gutenberg_download() ile Project Gutenberg ID’lerini kullanarak erişebiliriz.
library(gutenbergr)
hgwells <- gutenberg_download(c(35, 36, 5230, 159))## Determining mirror for Project Gutenberg from http://www.gutenberg.org/robot/harvest## Using mirror http://aleph.gutenberg.orgtidy_hgwells <- hgwells %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)## Joining, by = "word"HG Wells’in bu romanlarında en çok kullanılan kelimeler hangileridir?
tidy_hgwells %>%
count(word, sort = TRUE)## # A tibble: 11,769 x 2
## word n
## <chr> <int>
## 1 time 454
## 2 people 302
## 3 door 260
## 4 heard 249
## 5 black 232
## 6 stood 229
## 7 white 222
## 8 hand 218
## 9 kemp 213
## 10 eyes 210
## # ... with 11,759 more rowsŞimdi, hayatları Jane Austen ile biraz örtüşen ama oldukça farklı bir tarzda yazan Brontë kız kardeşlerinin bazı iyi bilinen eserlerini ele alalım. “Jane Eyre”, “Wuthering Heights”, “The Tenant of Wildfell Hall”, “Villette” ve “Agnes Grey” kitaplarına gutenberg_download() ile Project Gutenberg ID’lerini kullanarak erişebiliriz.
bronte <- gutenberg_download(c(1260, 768, 969, 9182, 767))tidy_bronte <- bronte %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)## Joining, by = "word"Brontë kız kardeşlerinin bu romanlarındaki en yaygın kelimeler nelerdir?
tidy_bronte %>%
count(word, sort = TRUE)## # A tibble: 23,050 x 2
## word n
## <chr> <int>
## 1 time 1065
## 2 miss 855
## 3 day 827
## 4 hand 768
## 5 eyes 713
## 6 night 647
## 7 heart 638
## 8 looked 601
## 9 door 592
## 10 half 586
## # ... with 23,040 more rowsŞimdi, Jane Austen, Brontë kız kardeşleri ve HG Wells’in eserleri için veri çerçevelerini birbirine bağlayarak her bir kelime için frekansı hesaplayalım. Veri kümemizi yeniden şekillendirmek için tidyr paketini’i kullanabiliriz. Paket içerisindeki spread() ve gather() komutları üç roman setini birbirine bağlamak ve karşılaştırmak için bize yardımcı olacaktır.
library(tidyr)
frequency <- bind_rows(mutate(tidy_bronte, author = "Brontë Sisters"),
mutate(tidy_hgwells, author = "H.G. Wells"),
mutate(tidy_books, author = "Jane Austen")) %>%
mutate(word = str_extract(word, "[a-z']+")) %>%
count(author, word) %>%
group_by(author) %>%
mutate(proportion = n / sum(n)) %>%
select(-n) %>%
spread(author, proportion) %>%
gather(author, proportion, `Brontë Sisters`:`H.G. Wells`)Jane Austen, Brontë kız kardeşleri ve HG Wells’in kelime frekanslarını karşılaştıralım.
library(scales)
# Satırlarda eksik gözlem varsa, bu gözlemlerin kaldırılmasıyla bir uyarı karşımıza çıkabilir.
ggplot(frequency, aes(x = proportion, y = `Jane Austen`, color = abs(`Jane Austen` - proportion))) +
geom_abline(color = "gray40", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
scale_color_gradient(limits = c(0, 0.001), low = "darkslategray4", high = "gray75") +
facet_wrap(~author, ncol = 2) +
theme(legend.position="none") +
labs(y = "Jane Austen", x = NULL)## Warning: Removed 41357 rows containing missing values (geom_point).## Warning: Removed 41359 rows containing missing values (geom_text).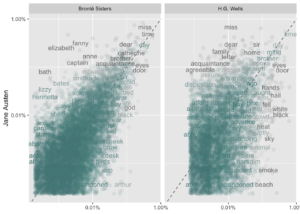
Bu grafiklerdeki çizgiye yakın olan kelimeler her iki metin grubunda da benzer frekanslara sahiptir, örneğin, hem Austen hem de Brontë metinlerinde (“miss”, “time”, “day”) kelimeleri üstte yer almış veya her iki Austen’de ve Wells metinlerinde (“time”, “day”, “broter”) kelimeleri yüksek frekanstadır. Çizgiden uzak olan kelimeler, diğer metin kümesindeki kelimelerden daha fazla bulunan kelimelerdir. Örneğin, Austen-Brontë grafiğide “elizabeth”, “emma” ve “fanny” gibi isimler yani kelimeler Austen’ın metinlerinde bulunur, fakat Brontë metinlerinde çok fazla değildir, “arthur” ve “dog” kelimeleri Brontë metinlerinde bulunur, ancak Austen metinlerinde bu kelimeler yoktur. Jane Austen ile HG Wells’i karşılaştırırken Wells, “beast”, “guns”, “feet” ve “black” kelimelerini kullanırken Austen bu kelimeleri kullanmamış. Austen “family”, “friend”, “letter” ve “dear” kelimelerini kullanırken Wells bu kelimeleri kullanmamış.
Genel olarak baktığımızda Austen-Brontë grafiğindeki kelimelerin, Austen-Wells grafiğine göre eğim çizgisinin sıfır noktasına daha yakın olduğuna dikkat edelim. Ayrıca, kelimelerin, Austen-Brontë grafiğinde daha düşük frekanslara kadar yayıldığına dikkat edelim; düşük frekansta Austen-Wells grafiğinde boş alan var. Bu sonuçlar, Austen ve Brontë kız kardeşlerinin Austen ve HG Wells’den daha benzer kelimeler kullandığını göstermektedir. Ayrıca, tüm kelimelerin üç metin grubunda bulunmadığını ve Austen ve HG Wells için panelde daha az veri noktası olduğunu görüyoruz.
Kelime frekans kümelerinin birbirine benzerliklerine korelasyon ile bakalım. Austen ile Brontë kız kardeşleri arasındaki ve Austen ile Wells arasındaki kelime frekansları arasındaki ilişki nasıldır?
cor.test(data = frequency[frequency$author == "Brontë Sisters",],
~ proportion + `Jane Austen`)##
## Pearson's product-moment correlation
##
## data: proportion and Jane Austen
## t = 119.65, df = 10404, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.7527869 0.7689641
## sample estimates:
## cor
## 0.7609938cor.test(data = frequency[frequency$author == "H.G. Wells",],
~ proportion + `Jane Austen`)##
## Pearson's product-moment correlation
##
## data: proportion and Jane Austen
## t = 36.441, df = 6053, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.4032800 0.4445987
## sample estimates:
## cor
## 0.4241601Kelime frekansları Austen ve Brontë romanları arasında Austen ve HG Wells’ten daha fazla ilişkilidir.
1.5. Özet
Bu bölümde metin yapılarını ve düzenli metin formatını anladık. Temel amacımız metni kelimelere parçalamak ve diğer metinler ile kıyaslamak olacaktır. Aşama aşama gidersek, elimizdeki metni parçalara bölüyoruz ve içerisindeki duraklama kelimelerini çıkardıktan sonra kelime frekanslarına bakmamız gerekiyor. Daha sonrasında diğer uygulamalara geçilerek metni anlamlandırmaya çalışıyoruz.