
![]()
4. Bölüm – Kelimeler Arasındaki İlişkiler: n-gram ve Korelasyon
Şuana kadar kelimeleri birer birim olarak ele aldık ve kelimelerin duygularını veya belgelerle olan ilişkilerine baktık. Bununla birlikte metin analizi aynı zamanda kelimeler arasındaki ilişkilere dayanır, hangi kelimelerin diğerlerini takip etme eğiliminde olduğunu veya aynı belgelerde birlikte olma eğilimini gösterir.
Bu bölümde kelimeler arasındaki ilişkileri hesaplama ve görselleştirme işlemleri yapacağız.
4.1. n-gram ile Kelimelere Parçalama
unnest_tokens() fonksiyonu ile elimizdeki metni birer kelimelere parçalamıştık ardından duygu ve frekans analizlerini gerçekleştirmiştik. Şimdi n-gram olarak adlandırılan ardışık kelime dizileri ile çalışacağız. “X” kelimesinin “Y” kelimesi tarafından takip edildiğini görerek, aralarındaki ilişkilerin modelini oluşturabiliriz.
unnest_tokens() fonksiyonu içerisine token = “ngrams” ifadesini ve ardışık kelime sayısı n = sayı ifadesi yazılmalıdır. n = 2 ayarlanır ise “bigram” olarak adlandırılan iki ardışık kelimeden oluşan kelime çiftleri, n = 3 ayarlanır ise “trigram” olarak adlandırılan üçlü ardışık kelimeden oluşan kelime grupları incelenir.
library(dplyr)
library(tidytext)
library(janeaustenr)
austen_bigrams <- austen_books() %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)
austen_bigrams## # A tibble: 725,049 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility sense and
## 2 Sense & Sensibility and sensibility
## 3 Sense & Sensibility sensibility by
## 4 Sense & Sensibility by jane
## 5 Sense & Sensibility jane austen
## 6 Sense & Sensibility austen 1811
## 7 Sense & Sensibility 1811 chapter
## 8 Sense & Sensibility chapter 1
## 9 Sense & Sensibility 1 the
## 10 Sense & Sensibility the family
## # ... with 725,039 more rowsBu veri yapısı da düzenli metin formatının bir varyasyondur.
Bigramların bir önceki ve bir sonraki kelime ile birlikte görünmesine dikkat ediniz.
4.1.1. N-gramları Sayma ve Filtreleme
dplyr kütüphanesini kullanarak en yaygın bigramları inceleyebiliriz.
austen_bigrams %>%
count(bigram, sort = TRUE)## # A tibble: 211,236 x 2
## bigram n
## <chr> <int>
## 1 of the 3017
## 2 to be 2787
## 3 in the 2368
## 4 it was 1781
## 5 i am 1545
## 6 she had 1472
## 7 of her 1445
## 8 to the 1387
## 9 she was 1377
## 10 had been 1299
## # ... with 211,226 more rowsTahmin edilebileceği gibi, en yaygın bigramlar, duraklama kelimleri olacaktır. “of the”, “to be”, “in the” gibi birbirini izleyen kelimeler tüm metinlerde çok fazla karşımıza çıkacaktır. Duraklama kelimelerini ardışık kelime gruplarından da çıkartabiliyoruz. Bunun için öncelikle tidyr kütüphanesinden separate() fonksiyonu ile tek bir değer gibi gözlenen ardışık kelime gruplarını birbirinden ayırıyoruz. Bigram’ı “word1” ve “word2” adlı iki sütuna ayırmamız gerekiyor. Sonrasında ise “word1” ve “word2” sütunlarına anti_join() işlemi ile duraklama kelimelerini çıkartıyoruz.
library(tidyr)
bigrams_separated <- austen_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word)
# yeni bigram frekansları:
bigram_counts <- bigrams_filtered %>%
count(word1, word2, sort = TRUE)
bigram_counts## # A tibble: 33,421 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 sir thomas 287
## 2 miss crawford 215
## 3 captain wentworth 170
## 4 miss woodhouse 162
## 5 frank churchill 132
## 6 lady russell 118
## 7 lady bertram 114
## 8 sir walter 113
## 9 miss fairfax 109
## 10 colonel brandon 108
## # ... with 33,411 more rowsYapacağımız gelecek analizlerde yeniden birleştirilen kelimelerle çalışmak isteyebiliriz. Bunun için tidyr kütüphanesinin unite() fonksiyonu “word1” ve “word2” sütunlarını birleştirecektir. unite() fonksiyonu separate() fonksiyonun tersidir.
bigrams_united <- bigrams_filtered %>%
unite(bigram, word1, word2, sep = " ")
bigrams_united## # A tibble: 44,784 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility jane austen
## 2 Sense & Sensibility austen 1811
## 3 Sense & Sensibility 1811 chapter
## 4 Sense & Sensibility chapter 1
## 5 Sense & Sensibility norland park
## 6 Sense & Sensibility surrounding acquaintance
## 7 Sense & Sensibility late owner
## 8 Sense & Sensibility advanced age
## 9 Sense & Sensibility constant companion
## 10 Sense & Sensibility happened ten
## # ... with 44,774 more rowsDiğer analizlerde, üçlü ardışık kelimeler olan en yaygın trigramlarla ilgilenmek istenebilir. Bunun için unnest_tokens() içerisinde n = 3 yazılmalıdır.
austen_books() %>%
unnest_tokens(trigram, text, token = "ngrams", n = 3) %>%
separate(trigram, c("word1", "word2", "word3"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word,
!word3 %in% stop_words$word) %>%
count(word1, word2, word3, sort = TRUE)## # A tibble: 8,757 x 4
## word1 word2 word3 n
## <chr> <chr> <chr> <int>
## 1 dear miss woodhouse 23
## 2 miss de bourgh 18
## 3 lady catherine de 14
## 4 catherine de bourgh 13
## 5 poor miss taylor 11
## 6 sir walter elliot 11
## 7 ten thousand pounds 11
## 8 dear sir thomas 10
## 9 twenty thousand pounds 8
## 10 replied miss crawford 7
## # ... with 8,747 more rows4.1.2. Bigram’ın Analizi
Satır başına bir bigram formatı, metnin keşifsel analizleri için faydalıdır. Basit bir örnek olarak, her kitapta geçen en yaygın sokaklara bakabiliriz.
bigrams_filtered %>%
filter(word2 == "street") %>%
count(book, word1, sort = TRUE)## # A tibble: 34 x 3
## book word1 n
## <fct> <chr> <int>
## 1 Sense & Sensibility berkeley 16
## 2 Sense & Sensibility harley 16
## 3 Northanger Abbey pulteney 14
## 4 Northanger Abbey milsom 11
## 5 Mansfield Park wimpole 10
## 6 Pride & Prejudice gracechurch 9
## 7 Sense & Sensibility conduit 6
## 8 Sense & Sensibility bond 5
## 9 Persuasion milsom 5
## 10 Persuasion rivers 4
## # ... with 24 more rowsBigram için tf-idf’ye bakalım.
bigram_tf_idf <- bigrams_united %>%
count(book, bigram) %>%
bind_tf_idf(bigram, book, n) %>%
arrange(desc(tf_idf))
bigram_tf_idf## # A tibble: 36,217 x 6
## book bigram n tf idf tf_idf
## <fct> <chr> <int> <dbl> <dbl> <dbl>
## 1 Persuasion captain wentworth 170 0.0299 1.79 0.0535
## 2 Mansfield Park sir thomas 287 0.0287 1.79 0.0515
## 3 Mansfield Park miss crawford 215 0.0215 1.79 0.0386
## 4 Persuasion lady russell 118 0.0207 1.79 0.0371
## 5 Persuasion sir walter 113 0.0198 1.79 0.0356
## 6 Emma miss woodhouse 162 0.0170 1.79 0.0305
## 7 Northanger Abbey miss tilney 82 0.0159 1.79 0.0286
## 8 Sense & Sensibility colonel brandon 108 0.0150 1.79 0.0269
## 9 Emma frank churchill 132 0.0139 1.79 0.0248
## 10 Pride & Prejudice lady catherine 100 0.0138 1.79 0.0247
## # ... with 36,207 more rowsJane Austen romanlarıdakş en yüksek tf-idf olan bigramlar
bigram_tf_idf %>%
arrange(desc(tf_idf)) %>%
mutate(bigram = factor(bigram, levels = rev(unique(bigram)))) %>%
group_by(book) %>%
top_n(15) %>%
ungroup %>%
ggplot(aes(bigram, tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~book, ncol = 2, scales = "free") +
coord_flip()## Selecting by tf_idf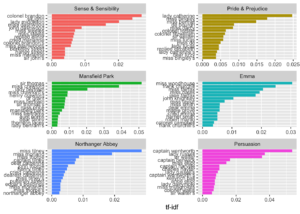
Bölüm 3’te keşfettiğimiz kadarıyla, Austen kitaplarını ayırt eden kelimeler neredeyse sadece isimlerdi. Ayrıca, burada yaygın isimlerin yanlarına fiil aldıklarını görüyoruz. “Pride and Prejudice” kitabında “replied elizabeth”, “Emma” kitabında ise “cried emma” kelime eşlerini görmekteyiz.
Bigramların tf-idf’sini incelemede bazı avantaj ve dezavantajlar vardır.
Bigramları saydırdığımızda, iki kelimeli bir çift tek bir kelimenin sıklığından daha azdır. Bu nedenle bigramlar çok büyük bir metin veri kümesinde yararlı olacaktır. Bigramlar yani ardışık kelime çiftleri, tek kelimelere nazaran metin yapısını daha iyi açıklar.
4.1.3 Bigramlarda Duygu Analizi
Olumsuzluk kelimelerine bakalım ve Afinn sözlüğü ile analizi yapalım.
bigrams_separated %>%
filter(word1 == "not") %>%
count(word1, word2, sort = TRUE)## # A tibble: 1,246 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 not be 610
## 2 not to 355
## 3 not have 327
## 4 not know 252
## 5 not a 189
## 6 not think 176
## 7 not been 160
## 8 not the 147
## 9 not at 129
## 10 not in 118
## # ... with 1,236 more rowsAFINN <- get_sentiments("afinn")
AFINN## # A tibble: 2,476 x 2
## word score
## <chr> <int>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## 7 abhor -3
## 8 abhorred -3
## 9 abhorrent -3
## 10 abhors -3
## # ... with 2,466 more rowsOlumsuzluk “not” kelimesi ile ilişkili kelimeler
not_words <- bigrams_separated %>%
filter(word1 == "not") %>%
inner_join(AFINN, by = c(word2 = "word")) %>%
count(word2, score, sort = TRUE) %>%
ungroup()
not_words## # A tibble: 245 x 3
## word2 score n
## <chr> <int> <int>
## 1 like 2 99
## 2 help 2 82
## 3 want 1 45
## 4 wish 1 39
## 5 allow 1 36
## 6 care 2 23
## 7 sorry -1 21
## 8 leave -1 18
## 9 pretend -1 18
## 10 worth 2 17
## # ... with 235 more rows“not” keimesini takip eden en yaygın duygu-ilişkili kelime normalde +2’lik bir skor ile pozitif olan “like” kelimesi çıkmıştır.
Hangi kelimelerin yanlış yönde en çok katkıyı sağladığını görmek istersek, kelimelerin skorları ile kaç defa görüntülendiklerini çarpabiliriz. Yani +3 skora sahip olan bir kelime 10 kere tekrar ediyor ise bun katkısı 30 puan olacaktır, ayrıca +1 skora sahip kelimeden de daha fazla katkı sağlayacaktır. Bunu da bir çubuk grafik ile görselleştirelim.
Olumsuz ya da olumsuz yönde, duygu puanlarına en büyük katkıyı sağlayan ‘not’ ile sıralanan 20 kelime.
not_words %>%
mutate(contribution = n * score) %>%
arrange(desc(abs(contribution))) %>%
head(20) %>%
mutate(word2 = reorder(word2, contribution)) %>%
ggplot(aes(word2, n * score, fill = n * score > 0)) +
geom_col(show.legend = FALSE) +
xlab("Words preceded by \"not\"") +
ylab("Sentiment score * number of occurrences") +
coord_flip()
“not like” ve “not help” gibi bigramlar yanlış tanımlamanın en büyük nedenleriydi ve metnin çok daha pozitif görünmesini sağladı. Ancak “not afraid” ve “not fail” gibi kelimelerin de bazen metin daha olumsuz olduğunu öne sürülmekte.
“not” burada tek başına bağlam sağlayan tek terim değildir. Diğer olumsuzluk bağlamlarını da ele alınabilir.
4.1.4. ggraph ile Bir Bigram Ağının Görselleştirilmesi
Kelimeler arasındaki tüm ilişkileri aynı anda görselleştirmekle ilgilenebiliriz. Yaygın bir görselleştirme olarak, kelimeleri bir ağa veya grafiğe yerleştirebiliriz.
Burada her bir düğüm bir kelimeyi temsil etmekte. Ağ görselinin üç argümanı vardır. Bu üç argümandan düzenli bir grafik oluşturulabilir.
- from: Düğüm bir kenardan geliyor (Düğümün nereden geldiği).
- to: Düğüm bir kenara doğru gidiyor (Düğümün nereye gittiği).
- weight: Her kenarla ilişkili sayısal değer
igraph paketi ağ analizinde güçlü fonksiyonlara sahiptir. Düzenli verilerden bir igraph nesnesi oluşturmanın bir yolu, graph_from_data_frame() ile düğümün nereden geldiğini yani “from” argümanını, nereye gittiğini “to” argümanını ve “weight” argümanını kullanmaktır, örnekte weight argümanı “n” dir.
library(igraph)
# orjinal frekanslar
bigram_counts## # A tibble: 33,421 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 sir thomas 287
## 2 miss crawford 215
## 3 captain wentworth 170
## 4 miss woodhouse 162
## 5 frank churchill 132
## 6 lady russell 118
## 7 lady bertram 114
## 8 sir walter 113
## 9 miss fairfax 109
## 10 colonel brandon 108
## # ... with 33,411 more rowsPride & Prejudice kitabındaki yaygın bigramların ağ analizi. 20’den fazla kez tekrar eden kelimeler.
# ortak kombinasyonlar için filter işlemi
bigram_graph <- bigram_counts %>%
filter(n > 20) %>%
graph_from_data_frame()
bigram_graph## IGRAPH 14921f6 DN-- 91 77 --
## + attr: name (v/c), n (e/n)
## + edges from 14921f6 (vertex names):
## [1] sir ->thomas miss ->crawford captain ->wentworth
## [4] miss ->woodhouse frank ->churchill lady ->russell
## [7] lady ->bertram sir ->walter miss ->fairfax
## [10] colonel ->brandon miss ->bates lady ->catherine
## [13] sir ->john jane ->fairfax miss ->tilney
## [16] lady ->middleton miss ->bingley thousand->pounds
## [19] miss ->dashwood miss ->bennet john ->knightley
## [22] miss ->morland captain ->benwick dear ->miss
## + ... omitted several edgesDaha iyi görünümlü bir grafik oluşturmak için,
- edge_alpha argümanı ile bağlantıların frekanslara göre transparanlığını ayarlar. Kelimenin ne kadar yaygın veya nadir olduğunu anlamamızı sağlar.
- grid::arrow() okun yönünü belirtir ve end_cap seçeneği ile kelime düğümüne dokunmadan okun bitmesini söyler.
- Düğümleri daha çekici hale getirmek için (bu örnekte daha büyük, mavi noktalar) renk ve boyut ayarlamaları yapılabilir.
- theme_void() ile ağ için yararlı bir tema ekleyebiliriz.
“Pride and Prejudice” kitabında daha iyi bir gösterim ile ağ analizi
set.seed(2016)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE,
arrow = a, end_cap = circle(.07, 'inches')) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()
Ağ yapısı ilişkisel düzenli verileri görselleştirmek için kullanışlı bir yoldur.
Bu işlemin metin işlemede ortak bir model olan Markov Zincirinin görselleştirilmesi olduğunu aklımızdan çıkarmayalım. Markov Zincirinde her bir kelime seçimi sadece kendinden önceki kelimeye bağlıdır.
4.2. Widyr Kütüphanesi ile Kelime Çiftlerinin Sayılması ve İlişkilendirilmesi
N-gram ile metni kelimelere parçalamak kelime çiftlerini keşfetmek için ideal bir araçtır. Ayrıca kelimeler birbirlerinin yanında bulunmasalar bile, belirli belgeler veya belirli bölümlerde birlikte olma eğilimde olan kelimeler ile de ilgilenme fırsatı bulabiliriz.
Düzenli veri değişkenler arasında karşılaştırma yapmak veya satırlara göre gruplandırmak için faydalı bir yapıdır. Ancak satırlar arasında karşılaştırma yapmak zor olabilir. Örnek vermek gerekirse, aynı belgede iki kelimenin kaç kez tekrar ettiğini ve bunların nasıl ilişkili olduğunu görmek. Kelime eşlerinin sayımı veya korelasyonu bulmak için öncelikle verileri geniş bir matris dönüştürmemiz gerekir.
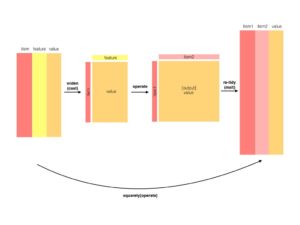
widyr paketinin arkasındaki felsefe şudur, paket önce veri setini geniş bir matrise dönüştürür, daha sonra matris, bir korelasyon matrisi gibi görünür.
- Bölümde de tidy text yani düzenli metnin geniş bir matrise dönüştürülmesinin bazı yollarını göreceğiz, şuanki durum için gerekli değildir. widyr paketi frekans ve korelasyon işlemlerini kolaylıkla yapabilir. Belgeler veya metin bölümleri arasında (gözlem grupları arasında) çift yönlü karşılaştırma yapablen işlevlere yoğunlaşacağız.
4.2.1. Bölümler Arasında Sayım İşlemi (frekans) ve Korelasyon
Bölüm 2’de duygu analizi için yaptığımız gibi, “Pride and Prejudice” kitabını 10 satırlık bölümlere ayırdık . Aynı bölüm içinde hangi kelimelerin görünmeye eğilimli olabileceği ile ilgilenebiliriz.
austen_section_words <- austen_books() %>%
filter(book == "Pride & Prejudice") %>%
mutate(section = row_number() %/% 10) %>%
filter(section > 0) %>%
unnest_tokens(word, text) %>%
filter(!word %in% stop_words$word)
austen_section_words## # A tibble: 37,240 x 3
## book section word
## <fct> <dbl> <chr>
## 1 Pride & Prejudice 1 truth
## 2 Pride & Prejudice 1 universally
## 3 Pride & Prejudice 1 acknowledged
## 4 Pride & Prejudice 1 single
## 5 Pride & Prejudice 1 possession
## 6 Pride & Prejudice 1 fortune
## 7 Pride & Prejudice 1 wife
## 8 Pride & Prejudice 1 feelings
## 9 Pride & Prejudice 1 views
## 10 Pride & Prejudice 1 entering
## # ... with 37,230 more rowswidyr paketinin kullanışlı bir işlevi pairwise_count() fonksiyonudur. Aynı bölümde birlikte görünen ortak kelime çiftlerini saymamızı sağlar.
library(widyr)
# Bölümler içinde birlikte görünen kelimelern frekansı
word_pairs <- austen_section_words %>%
pairwise_count(word, section, sort = TRUE)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.word_pairs## # A tibble: 796,008 x 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 darcy elizabeth 144
## 2 elizabeth darcy 144
## 3 miss elizabeth 110
## 4 elizabeth miss 110
## 5 elizabeth jane 106
## 6 jane elizabeth 106
## 7 miss darcy 92
## 8 darcy miss 92
## 9 elizabeth bingley 91
## 10 bingley elizabeth 91
## # ... with 795,998 more rowsBir bölümdeki en yaygın kelime çiftinin “Elizabeth” ve “Darcy” (iki ana karakter) olduğunu görüyoruz. Ayrıca sıklıkla Darcy ile ortaya çıkan kelimeleri kolayca bulabiliriz:
word_pairs %>%
filter(item1 == "darcy")## # A tibble: 2,930 x 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 darcy elizabeth 144
## 2 darcy miss 92
## 3 darcy bingley 86
## 4 darcy jane 46
## 5 darcy bennet 45
## 6 darcy sister 45
## 7 darcy time 41
## 8 darcy lady 38
## 9 darcy friend 37
## 10 darcy wickham 37
## # ... with 2,920 more rows4.2.2. Çift Yönlü Korelasyon
“Elizabeth” ve “Darcy” gibi çiftler en çok rastlanılan kelimelerdir. Ancak bu kelimeler aynı zamanda en yaygın bireysel kelimeler oldukları için özellikle anlamlı değildir. Bunun yerine , birbirleriyle ne sıklıkla göründüklerine bağlı olarak, birlikte ne sıklıkla göründüklerini gösteren kelimeler arasındaki ilişkiyi incelemek isteyebiliriz .
Özellikle burada ikili korelasyon için phi katsayısına odaklanacağız . Phi katsayısının odak noktası, X ve Y kelimelerinin her ikisinin de diğeri olmadan göründüğünden ne daha fazla ortaya çıktığıdır.

Örneğin, n11 X ve Y kelimesinin bulunduğu yerin frekansını, n00 is X ve Y kelimesinin bulunmadığı yeri, n10 veya n01 ise X ve Y kelimelerinden birinin bulunduğu yerin frekansını verir. phi kat sayısı da aşağıdaki gibidir.
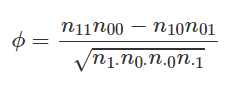
NOT: Phi katsayısı, ikili veriye uygulandığında Pearson katsayısına eşdeğerdir.
widyr paketinin pairwise_cor() fonksiyonu bize aynı bölümde görünen kelime sıklıklarına göre kelimeler arasında phi katsayısı bulunmasını sağlar. pairwise_count() fonksiyonu ile benzer görevdedir.
# Nispeten yaygın olan kelimeleri ilk önce filtrelemeliyiz
word_cors <- austen_section_words %>%
group_by(word) %>%
filter(n() >= 20) %>%
pairwise_cor(word, section, sort = TRUE)
word_cors## # A tibble: 154,842 x 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 bourgh de 0.962
## 2 de bourgh 0.962
## 3 pounds thousand 0.769
## 4 thousand pounds 0.769
## 5 catherine lady 0.750
## 6 lady catherine 0.750
## 7 william sir 0.706
## 8 sir william 0.706
## 9 forster colonel 0.603
## 10 colonel forster 0.603
## # ... with 154,832 more rowsBu tarz bir çıktı, keşif yapmak için yararlıdır. Örneğin, bir filter işlemi kullanarak “pound” gibi bir kelime ile en ilişkili kelimeleri bulabiliriz .
word_cors %>%
filter(item1 == "pounds")## # A tibble: 393 x 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 pounds thousand 0.769
## 2 pounds ten 0.328
## 3 pounds wickham's 0.204
## 4 pounds settled 0.169
## 5 pounds children 0.146
## 6 pounds fortune 0.121
## 7 pounds ready 0.106
## 8 pounds particulars 0.106
## 9 pounds town 0.101
## 10 pounds believed 0.0959
## # ... with 383 more rowsfilter ilginç bulduğumuz veya karşılaştırmaya değer olabilecek kelimeleri seçmemize ve onlarla en fazla ilişkili olan diğer kelimeleri bulmamıza yardımcı olur.
word_cors %>%
filter(item1 %in% c("elizabeth", "pounds", "married", "pride")) %>%
group_by(item1) %>%
top_n(6) %>%
ungroup() %>%
mutate(item2 = reorder(item2, correlation)) %>%
ggplot(aes(item2, correlation)) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free") +
coord_flip()## Selecting by correlation
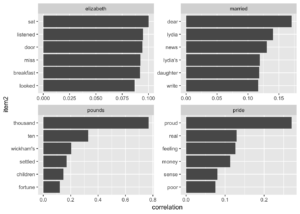
“elizabeth”, “pound”, “married” ve “pride” ile en çok ilişkili olan Pride and Prejudice kitabındaki kelimeler.
Bigramları görselleştirmek için ggraph paketini kullandığımız gibi, widyr paketi ile bulduğumuz kelimelerin korelasyonlarını ve kümelerini görselleştirmek için kullanabiliriz.
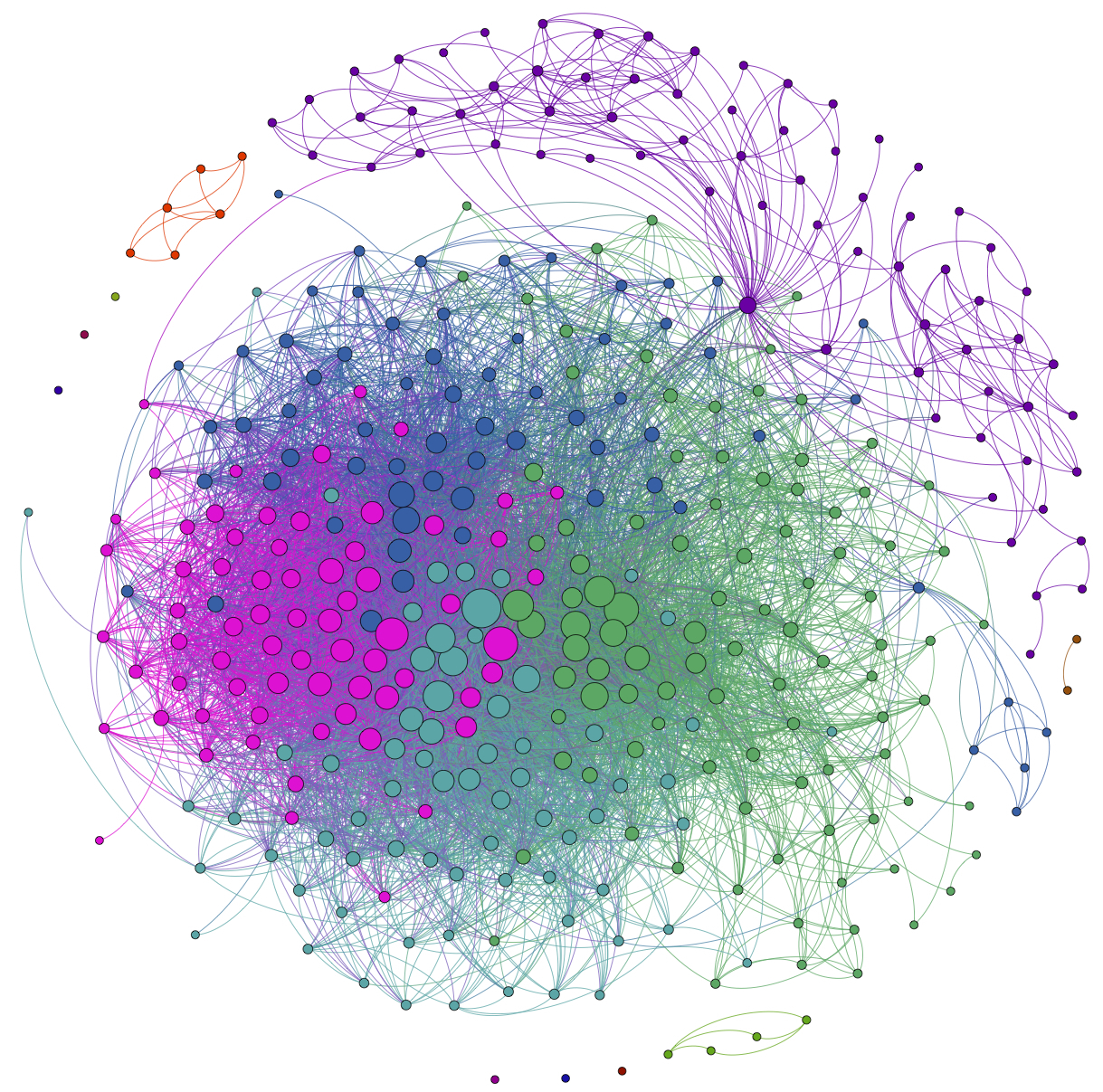
“Pride and Prejudice” kitabındaki kelime çiftleri, aynı 10 satırlık kısımda 0.15 korelasyon ile görünmesi,
set.seed(2016)
word_cors %>%
filter(correlation > .15) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void()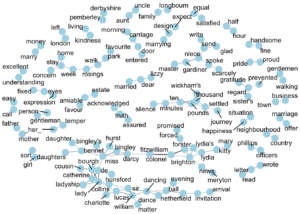
Bigram analizinden farklı olarak burada ilişkiler arasında bir yönelme yoktur. Dikkat ederseniz kelimeler arasında bir ok yok. Buradaki ilişkiler yönelimden ziyade simetriktir.
4.3. Özet
Bu bölümde düzenli metin yaklaşımının yalnızca bireysel kelimeler için değil aynı zamanda kelimeler arasındaki ilişkileri ve bağlantıları göstermek için neler yapılabileceğini göstermiştir. İlişkiler n-gramlar yardımıyla hangi kelimenin diğerinden sonra ortaya çıkmaya eğilimli olduğunu görmemizi sağlar veya birbirine yakın olarak gözüken kelimeler için korelasyona bakabiliriz. Bu bölümde ayrıca, bu tür ilişkilerin her ikisini de ağ grafiği olarak görselleştirmek için ggraph paketini de bize sundu. Ağ grafiği görselleştirmeleri ilişkileri araştırmak için esnek ve önemli bir araçtır.