

![]()
Utku Kubilay ÇINAR
Veri sadece sayısal değil aynı zamanda görsel, işitsel ve dokunsaldır. Yazarların yazdıkları yazılar da bir veridir. Metin madenciliği olarak isimlendirilen çalışmalar ise yazının-metnin analizidir. Yazılar, o yazar hakkında kıymetli bilgiler barındırır. Yazarın karakterini özetler. Ele alınan konu ile bağlantılı diğer konuları araştırmacıya söyler. Yazarın hangi kelimeleri seçtiği, hangi kelimelerden sonra hangi kelimeleri kullandığı gibi bilgilerle karakteristik özellikleri yansıtır (böylece yazarları karşılaştırabiliriz. Yazarlar arasında kullandığı kelimelerin regresyon modelini kurabiliriz, hatta kümeleme analizlerini yapabiliriz, duygularını analiz edebiliriz (bknz. sentiment analysis), araştırılan konu ile ilişkili diğer alt başlıkları öğrenebiliriz ).
Sosyal ağ platformlarından olan Twitter’da her kullanıcı aslında bir yazardır. Büyük çapta metin içeren Twitter üzerinden metin madenciliği çalışmaları sıklıkla yapılmaktadır. Pazarlama faaliyetlerinde, dizilerin-filmlerin reyting skorlamalarında, satış tahminlerinde Twitter metin verileri üzerine yapılan analizler büyük önem taşır ve reklam şirketlerince kullanılır.
Bu yazımda Twitter’dan belirlediğimiz bir konu üzerine çektiğimiz metinleri analiz edeceğiz ve belirlediğimiz konu ile alakalı başka konular var mı ? Varsa nelerdir ? gibi sorulara cevap arayacağız.
İlk olarak araştıracağımız konuyu belirlememiz gerekmektedir. Veri bilimi meraklıları ve inananları olarak “datascience” kelimesini araştıralım. Böylece Twitter’da insanlar veri bilimi ile beraber hangi kavramları konuşuyor ve konuştuğu kavramlar ile veri bilimi arasındaki etkileşimin ne düzeyde olduğunu incelemiş olacağız. Bu çalışmayı R Studio 3.5.0 üzerinden yapacağız.
Twitter Metin Madenciliği “#datascience” Twitleri Uygulaması
Günün Sorusu: Tweet mi Twit mi ? Düşündüm, karar veremedim. Ben okuduğum gibi yazacağım 🙂
Kullanılan Kütüphaneler(Pokemonlar)

Ardından veri setimizi oluşturalım. Bu işlemler için Twitter hesabınıza giriş yapmanız gerekmektedir. Detaylı bir çalışma yapmak istiyorsanız Twitter Apps’e üye olup geliştirici hesabı açmanız gerekmektedir. Buradan açıklamalı kaynağa ulaşabilirsiniz.
Aşağıdaki kod dizini ile “datascience” hashtagi ile kullanılan, ingilizce yazılan, retweet olmayan 10.000 tane twiti al demiş oluyoruz ve böylece veri setimizi oluşturuyoruz.

datatable fonksiyonu ile atılmış twiti incelendiğinde atılan twit “text” parametresinde mevcut. Veri setimiz 9.152 satır ve 89 parametredir.
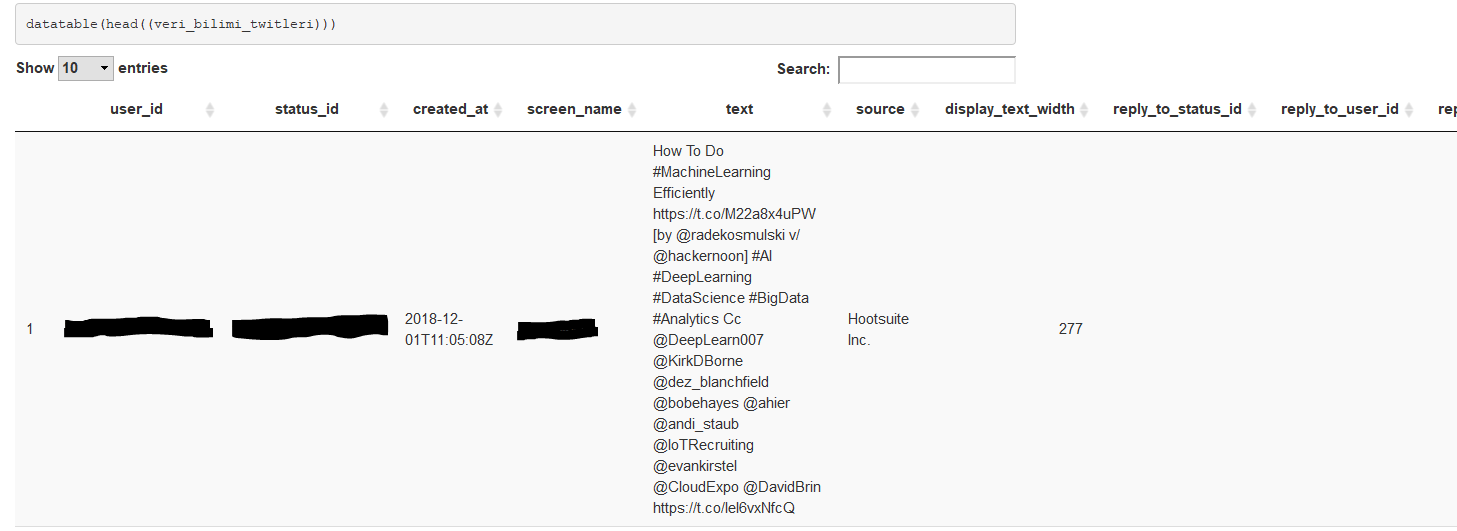
Görüldüğü üzere veriyi analize uygun hale getirmemiz gerekmektedir.
Veri Manipülasyonu
Text parametresindeki yazıların temizlenmesi gerekmektedir.
![]()
Bazı dönüşümler-değişimler yapıldıktan sonra temiz yazıları elde etmemiz gerekmektedir. Öncelikle yazıların(twitlerin) kelimelerini çıkartalım yani kelime bazlı bölelim ardından da veri setimizden “stop words” ‘ leri çıkartmaya uygun hale getirelim.

Harfleri analize uygun hale getirelim ki türkçe karakterler gibi harfler, ilerleyen kısımlarda bize zorluk çıkarmasın.

Kelime sıklıklarını çıkartalım ve en çok kullanılan(frekansı en yüksek) 15 kelimeyi bulalım. Bunu yapmamızın sebebi text mining’te “stop words” olarak adlandırılan “the-to-a-for-with” gibi kelimeleri (tek başlarına bir anlam ifade etmeyen kelimeler) çıkartmaktır.
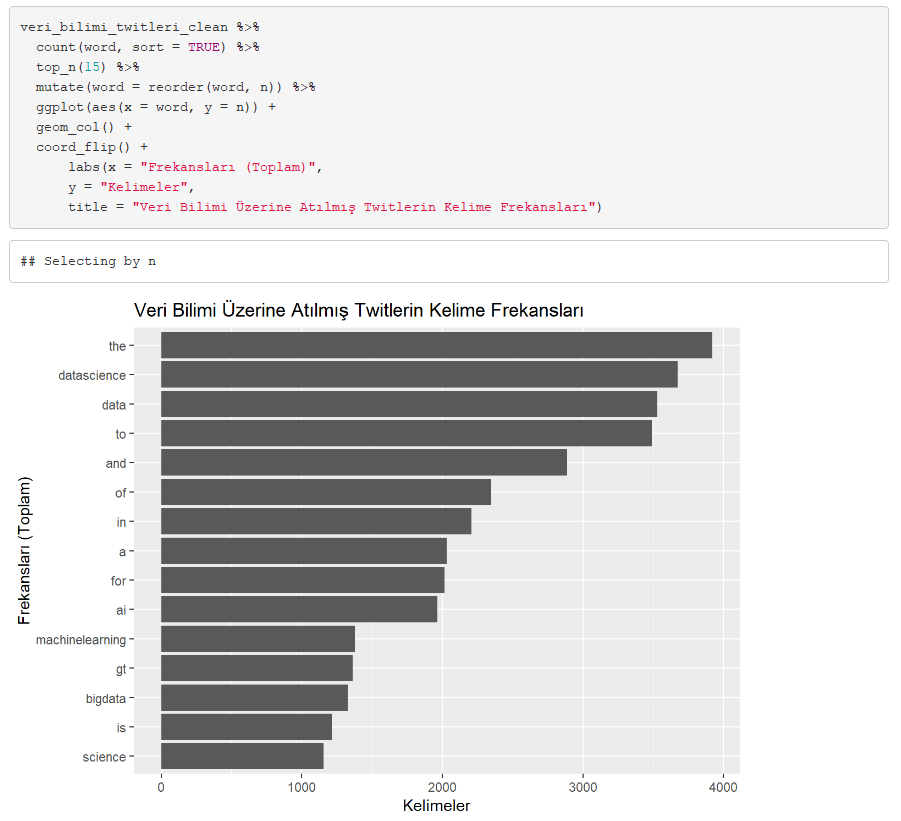
Toplam kelime sayımız 146.843 tanedir. Stop Words’ler çıkartıldıktan sonra elimizde kalan kelime sayısı 94.447 tanedir.
Stop Words’ler çıkartıldıktan sonra grafiğimizi tekrar oluşturalım. Grafikte de görüldüğü üzere kelimelerin sıklıkları istediğimiz konu üzerine yoğunlaşmıştır.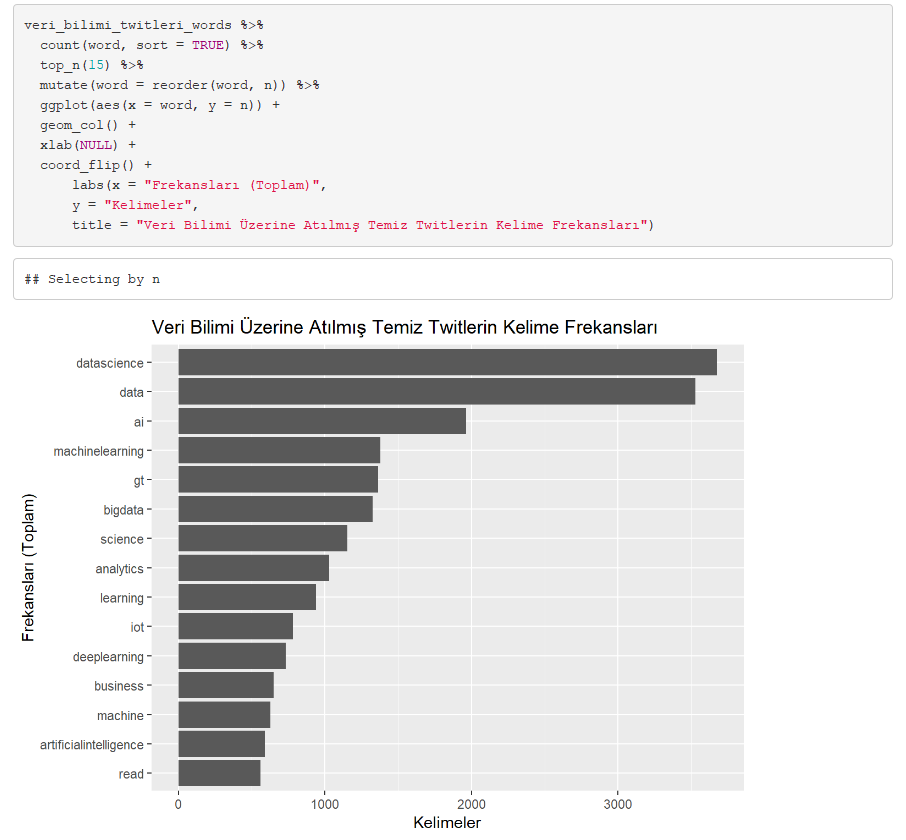
En sık kullanılan 15 kelimeye bakıldığında görüyoruz ki veri bilimi ile beraber, yapay zeka, büyük veri, analitik ve makine öğrenmesi gibi kavramlar sıklıkla kullanılmış. Demek oluyor ki, bu kelimeler veri bilimine yakın ve ilişkilidir.
Text mining konusunda “ngrams” olarak adlandırılan bir bölme işlemi vardır. “ngrams” değerini 2 olarak girersek kelimeleri ikili olarak bölecektir.
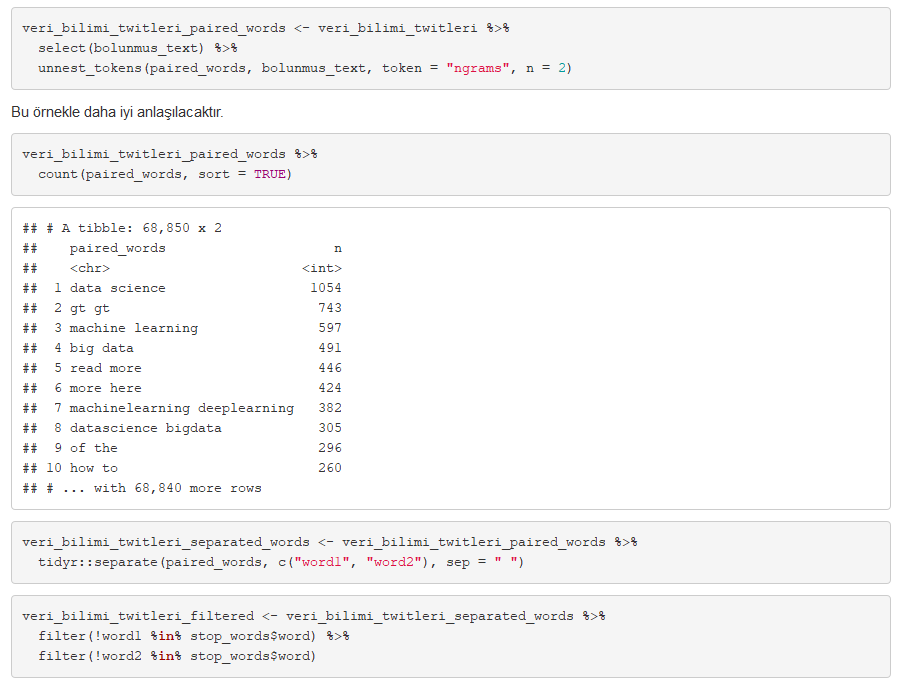
Son kod dizini ile ikili olarak ayırdığımız veri setinden stop words’ler çıkartılmıştır.

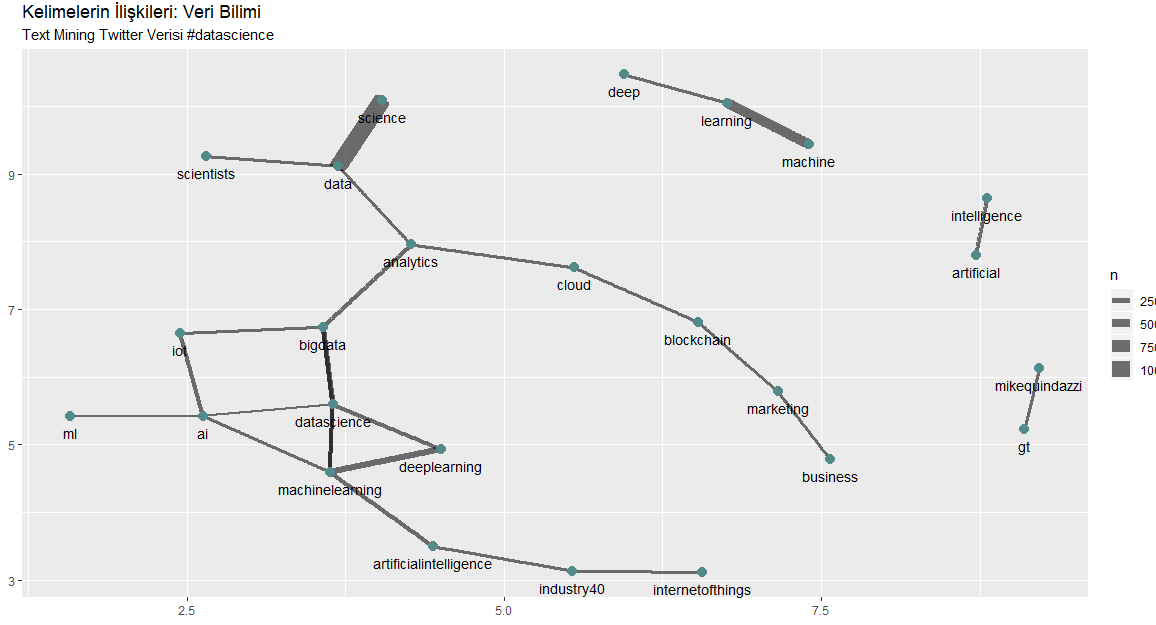
Yukarıda görmüş olduğumuz grafik, hangi kelimelerin birlikte kullanıldığını ve ilişkilerinin olduğu grafiktir. Alttaki zinciri takip ettiğimizde Endustri 4.0’dan Yapay Zekaya, oradan Makine Öğrenmesine, oradan Derin Öğrenmeye, Büyük Veriye, iot’e, Analitiğe ve Veriye giden bir harita(zincir) oluşmuş. Aynı zincirin diğer kırılımlarına indiğimizde Bulut Teknolojilerini, Blockchainleri, Marketing ve İş gibi alt başlıkları görebiliyoruz. Yukarıdaki grupta ise Derin Öğrenme ile Makine Öğrenmesi ayrı bir şekilde kümelenmiş.
Bu uygulamadan çıkarmamız gereken sonuç; Twitter’dan veri bilimi ile yola çıktık ve son olarak elimizde onlarca alt başlık oldu. Bu alt başlıkları anlamadan, veri bilimine ulaşmamız zor olacaktır. Temelimizi sağlam tutmak için ilişkileri incelemeli ve bunları anlamalıyız. Grafikte Veri Bilimi merkezinde, en yakın ve güçlü komşuları olan Makine Öğrenmesini, Derin Öğrenmesini, Yapay Zekayı ve Büyük Veriyi anlamamız ve üzerinde çalışmalıyız.
Günümüzde artık her şey veri. Bizler ise bu veriyi anlamlı hale getiren, modelleyen, raporlayan, görselleştiren, algoritmalar kuran-kullanan kişileriz ve hepimizin odağında veri var. Bu sebeple Veri Bilimcisi Yol Haritası veri ile başlar, veri okur yazarlığı ile biter ve bu böyle devam eder.
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın..
Kaynak: https://www.tidytextmining.com/
Kaynak: https://www.earthdatascience.org/
Kaynak: https://towardsdatascience.com/setting-up-twitter-for-text-mining-in-r-bcfc5ba910f4
Kaynak: https://www.data-imaginist.com/2017/ggraph-introduction-edges/
Görsel Kaynak: http://blog.datumbox.com/