
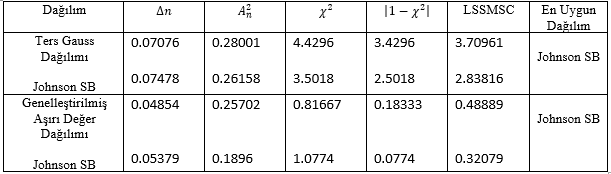
Bu yazıda, internetle birlikte hayatımıza giren yeniliklerin ufak bir parçasının değerlendirilmesi üzerinde duracağız. “Tıklama istatistiklerinden oluşan sayfa merkezli verilerin dağılımının modellenmesi sonucu, planlamalara ve benzetim modellerine kaynak nasıl yaratılır?” sorusunun cevabını birlikte arayacağız. Bu soru için, hedef web sayfaları olarak hazır giyim ve aksesuarların pazarlandığı e-ticaret siteleri ile bilgi edinme amaçlı gezilen haber siteleri seçilmiştir. Seçilen sitelere yönelik elde edilen verilerin hangi dağılım ya da dağılımlara uygun olduklarının belirlenmesi amacıyla EasyFit 5.6 programı aracılığı ile distribution fitting işlemi yapılmıştır. Değişkenlerin incelenen dağılımlara uygunlukları Kolmogorov-Smirnov, Anderson-Darling ve Ki-Kare uygunluk testleri aracılığıyla incelenmiştir. Karar verilemeyen durumlar için de LSSMSC kriterine göre değişkenlere ait uygun olan dağılımlar arasından seçim yapıldığında, Sitede Bir Günde Harcanan Ortalama Süre (daily time) değişkeni için E-Ticaret sitelerinde Dagum, haber sitelerinde Johnson SB dağılımı, Hemen Çıkma Oranı (bounce rate) değişkeni için E-Ticaret sitelerinde Burr, haber sitelerinde Johnson SB ve Kullanıcı Başına Düşen Ortalama Ziyaret Edilen Sayfa Sayısı (daily pageviews per visitor) değişkeni için E-Ticaret ve haber sitelerinin her ikisi için de Dagum dağılımının uygun olduğu sonucuna ulaşılmıştır. O zaman giriş, gelişme ve sonuç aşamalarına birlikte bakalım 🙂
İnternet, iş yaşamının geleneksel yollarını, sunduğu yeni alternatifler ile kapatarak, kurumların müşteri ile iletişimini yeni kanallara taşımış ve tüm dünyaya açık hale getirmiştir. İnternet tabanlı interaktif uygulamalar olarak tanımlanan sosyal yazılımlar bu gelişmeyi ivmelendirmiştir. Aynı zamanda internet, bilginin elektronik tavsiye (e-WOM) gücü ile yayılmasına olanak sağlamaktadır. Bilgisayar ağlarının planlanması ve kaliteli ağ servisi sağlamak için internet veri trafiği modellerinin kesin tahminlerine ihtiyaç duyulmaktadır. Bu planlama ve benzetim modelleri gerçek hayat olgularından elde edilen deneysel sonuçlara göre üretilmektedir. Web sunucuları veya üçüncü taraf servis sağlayıcılar tarafından internet kullanımına dair elektronik kayıtlara tıklama verisi (clickstream data) denmektedir. Web sayfasına giriş, yüklenen elemanlar, sayfada kalma süresi, buradan bağlantılı sayfalara geçiş adedi temel bilgilerdir. Bir siteye ayda giriş sayısı, burada geçirilen süre ve ulaşılan bağlı sayfa sayısı bir sitenin ilgili teorilere göre sosyal görünürlüğünü temsil etmektedir. Web sitelerine ait tüm bu istatistikler, sosyal etkinin fonksiyonlarıdır. Belirli bir web sayfası için tasarlanmış verilerin toplanması “site merkezli” ve “kullanıcı merkezli” şeklinde gerçekleştirilmektedir. Kullanıcı merkezli verinin en büyük dezavantajı ortak bilgisayar kullanımı ve bireysel kayıt ile giriş ihtiyacı olmasıdır. Kişi bazlı verilerin kullanıldığı araştırmalarda, kişi bazlı hareketlerin heterojenliği, farklı kanallardan ulaşımları ve bunların etkileşimini içermeleri nedeniyle sorunlar meydana gelebilmektedir.
Şimdi yukarıda verilen bilgiler doğrultusunda, hedef web sayfaları olarak hazır giyim ve aksesuarların pazarlandığı e-ticaret siteleri ile bilgi edinme amaçlı gezilen haber sitelerine ait istatistikleri inceleyelim. “Neden bu siteler?” sorusunu duyar gibiyim. Çünkü içerik bakımından farklı olan bu web sitelerinin araştırıldığı pek çok çalışmada, sonuçların ayrıştığı ve aynı olduğu yönünde iki zıt görüş mevcuttur. Bu nedenle biz de inceleyip hangi görüşü destekleyici sonuçlar olduğuna bakabiliriz. İstenen web sitelerine ait veriler, sitelere ait ölçümlerin yapılıp yayınlandığı Alexa Traffic Rank sitesi aracılığı ile elde edilmiştir. İncelenmesi mümkün olan tüm moda ve haber sitelerine manuel olarak giriş yapılarak Alexa web sitesi aracılığı ile yapılan ölçüm değerleri temin edilmiştir. Bu ölçüm değerleri;
- Bounce Rate (hemen çıkma oranı)” olarak isimlendirilen, web sitesini ziyaret eden kişilerin açılış sayfası haricinde diğer bir sayfayı ziyaret etmeden siteden ayrılma yüzdesini gösteren bir ölçüm değeridir. Bu değer, web sitelerinin ziyaretçiler tarafından ne sıklıkla ziyaret edildiğinin incelenmesinde bir yardımcı araç olmakla birlikte, web siteleri için bu değerin düşük olması pozitif bir durumdur.
- Daily Pageviews Per Visitor (sayfa görüntüleme sayısı)” olarak isimlendirilen, ilgili web sitesindeki ziyaretçilerin ortalama açtıkları sayfa sayısını ifade eden bir değerdir.
- Daily Time (sitede kalma süresi)” olarak isimlendirilen, ilgili web sitesindeki ziyaretçilerin web sitesinde ortalama gezinme sürelerini ifade eden bir göstergedir.
Elde edilen ölçüm değerleri 65 adet moda web sitesi ve 62 adet haber web sitesine ait olmakla birlikte toplamda 127 web sitesine aittir. Bu web sitelerinden moda siteleri 1 ve haber siteleri 2 olarak kodlanarak gruplandırılmıştır. Gruplar arası farklılığın incelenmesi için SPSS programı aracılığı ile iki grubun karşılaştırılması durumunda kullanılan t-testi uygulanmıştır. Hadi sonuçlara aşağıda verilen tablo yardımıyla bakalım.
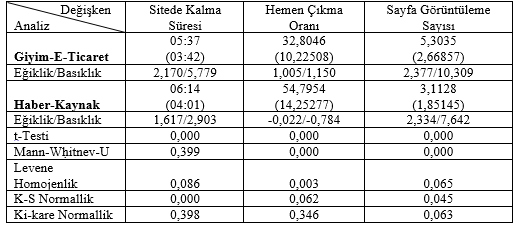
Gruplar arası farklılığın incelenmesi amacıyla uygulanan t-testi sonucunda iki grup arasında anlamlı farklılık olduğu görülmüştür. Anakütle örnekleme dağılımı normallik şartı aranmaması için ve test sonucunun tutarlı olup olmadığının kontrolü amacıyla bağımsız örneklem t-testine alternatif olarak Mann-Whitney U testi de kullanılmıştır. Sitede kalma süresinde iki farklı amaçlı site grubunun ortalamaları arasında anlamlı bir fark gözlenmemiştir Diğer taraftan bağımsız site gruplarının hemen çıkma oranıları ve sayfa görüntüleme sayıları arasında anlamlı fark bulunmuştur. Farklılıkların incelenmesinin ardından normal dağılım durumunun incelenmesi için Kolmogorov-Smirnov ve Ki-kare uygunluk testleri yapılmıştır. Eğiklik ve basıklık katsayılarının normal dağılıma göre sapma gösterdiği ortaya çıkmıştır. Uygunluk testlerine göre normal dağılıma uygunluk reddedilmiştir. Değişkenlere uygulanan t-testi sonucunda görüldüğü üzere, değişkenlerin kategorileri arasında anlamlı farklılık olması nedeniyle haber ve e-ticaret siteleri her bir değişken için ayrı ayrı incelenmiştir. Seçilen sitelere yönelik elde edilen verilerin hangi dağılım ya da dağılımlara uygun olduklarının belirlenmesi amacıyla EasyFit 5.6 programı aracılığı ile distribution fitting işlemi yapılmıştır. Farklı tip disiplinlerdeki araştırmacılar tarafından da kullanılabilen bu program, örnek veriye uygun olan olasılık dağılımının belirlenmesinde 61 tip teorik dağılım modeli aracılığı ile simülasyon yapmaktadır. Program, belirlenen olasılıklara ait parametrelerin belirlenmesinde farklı dağılımlara göre L-momentler, en küçük kareler yöntemi, olasılık-ağırlıklı momentler ve en çok benzerlik yöntemlerinden birini standart olarak kullanmaktadır. Hangi değişken hangi dağılıma uygunluk göstermiş bakalım.

Aslında zaten EasyFit programı bize Kolmogorov-Smirnov, Anderson Darling ve Ki-Kare test sonuçlarında ki sıralamaya göre değişkenin hangi dağılıma uygun olduğu bilgisini veriyor. Ancak sıralamalara bakıldığında, iki dağılım arasında karar verilemeyen durumlar için ne yapmak gerekli? LSSMSC (Least Sum of Statistics Model Identification Criterion) kriteri kullanabiliriz. En az istatistik toplamı temeline dayanan LSSMSC model tanımlama kriterine göre, Kolmogorov-Smirnov, Anderson Darling ve Ki-Kare uygunluk testlerine ait istatistikler birleştirilerek, tek bir kritere entegre edilmektedir. LSSMSC’nin gösterimi aşağıda verilmiştir.

Hadi şimdi de bu kritere göre nasıl karar verildiğine bakalım.
Peki, web sitelerine ait istatistiklerin dağılımlarını bulmak ne işimize yarayacak? Elde edilen dağılım bilgileri, özellikle özel sektörde satış simülasyonlarında, web sitelerinin okuma sıklıklarının belirlenmesinde, web siteleri arası performans değerlendirmede, multimedya satış sorumlularının kendi performanslarının değerlendirilmesinde vb. pek çok alanda kullanılabilmektedir. Ayrıca incelenen değişkenlerin ilişki olması sonucu marjinal dağılımlar elde edilmiştir. Nasıl anladık peki ilişkili olduklarını? Aşağıda sırasıyla e-ticaret ve haber siteleri için verilen korelasyon tablolarına bakabiliriz.
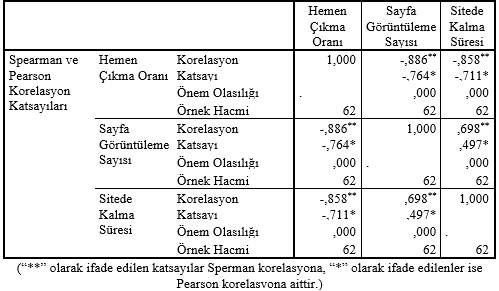
E-ticaret sitelerinde hemen çıkma oranının, sitede kalma süresi ve sayfa görüntüleme sayısı değişkenleri ile ters yönlü orta derece ilişki içerisinde olduğu görülmüştür. Aynı zamanda sitede kalma süresi ile sayfa görüntüleme sayısı pozitif yönlü yüksek ilişki içerisindedir.
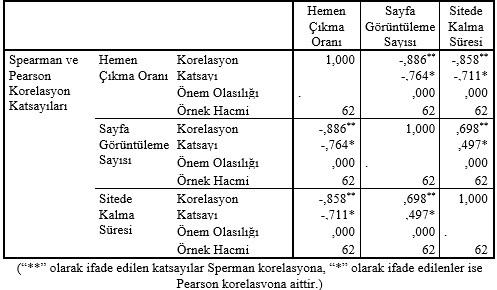
Haber sitelerinde hemen çıkma oranının, sitede kalma süresi ve sayfa görüntüleme sayısı değişkenleri ile ters yönlü yüksek derece ilişki içerisinde olduğu görülmüştür. Aynı zamanda sitede kalma süresi ile sayfa görüntüleme sayısı pozitif yönlü orta derece ilişki içerisindedir. Sperman ve Pearson korelasyon katsayıları karşılaştırıldığında, Sperman korelasyon katsayısının her değişken için daha güçlü sonuç vermesi sonucu, değişkenler arası ilişkinin doğrusal olmadığını söylemek mümkündür. Buradan hareketle, koşullu dağılımların da elde edilebileceği mümkün gözükmektedir. Örneğin, web sitelerinden hemen çıkma oranının 1 olması durumunda okunma sayısının kaç olduğu bilgisine ulaşılabilecektir. Bu imkân da bize stratejik kararların alınmasında fayda sağlayabilecektir. Gördüğünüz gibi birkaç temel istatistiksel analiz bilgisiyle çok önemli sonuçlar elde edebiliyoruz. Tabii bu noktada, “niye illa ki bir dağılıma uydurmak zorundayız?” sorusuyla non-parametrik yaklaşımları savunduğunuzu duyar gibiyim. Fakat eğer elimizde uygun teknikleri kullanmaya olanak varsa, unutmayalım ki parametrik yaklaşımlar her zaman daha etkin sonuçlar elde etmemizi sağlar. Bu arada yaklaşım demişken, “benzetim modeliyle ekonometrik model arasındaki fark ne ki?” sorusu da çıktı şimdi. Ekonometrik modeller, büyüme, salınım vb. pek çok bileşenlerin değişim ve davranışlarını ifade eder. Evet bu modeller kendi içerisinde yer alan değişkenlerin kestirilmesinde oldukça faydalıdır. Fakat karmaşık olan sistemlerin yapı ve davranışlarını anlamada ve buna uygun ölçütleri belirleyerek strateji geliştirmede karşımıza benzetim modellerinin imkânları çıkmaktadır.
Sizinle karşılıklı istişare etmek çok keyifli oldu. Fakat siz daha fazla soru sormadan kaçayım… Sohbetimizden doğan sorulara yeni cevaplar arayışı için farklı bir yazıda görüşmek üzere. Hep birlikte nice düşünmekten yorgun düştüğümüz günlere 🙂
(Not: Olur da EasyFit programını incelemek isterseniz, denediğinizde aşina olmanız adına kısa bir görsel bırakıyorum.)