

Apache Spark büyük veri analizinin en önde gelen platformu olarak popülerliğini ve önemini gittikçe arttırıyor. Bir çok insan Spark’ın bu değerini farkettiğinden Spark öğrenmeye başlıyor. Birçok kullanıcının bilgisayarında Windows işletim sistemi kurulu. Spark’ı Windows işletim sistemi üzerine de kurarak kullanabiliriz. Ancak bu hususta çok detaylı bir kılavuz olmadığından bir çok Spark öğrencisi Windows üzerinde Spark kurmayı başaramıyor. Bu açığı gidermek amacıyla burada tüm detaylarıyla Windows 10 üzerine Spark kurulumunu anlatacağız.
1. Java Kontrol/İndirme/Yükleme
Bilgisayarda java olup olmadığını ve varsa versiyonunu kontrol etme:
- Windows+R tuşuna basınız. Karşınıza çalıştır gelecektir.
- Çalıştır kutusu içine cmd yazıp enter tuşuna basınız.
- Komut satırına
java -versionkomutunu yazınız. Eğer java yüklü ise aşağıdakine benzer bir sonuç göreceksiniz. - Eğer java yüklü değilse bir sonraki adıma geçiniz.
Java Kurulumu
- Google’da “java development kit 8” araması yapınız veya bu bağlantıdan Oracle’ın ilgili sayfasına ulaşınız.
- Lisans anlaşmasını kabul ediniz.
- En alttaki “Windows x64 207.27 MB jdk-8u171-windows-x64.exe” olan bağlantıyı tıklayarak java kurulum dosyalarını indiriniz.
- İndirdiğiniz dosyaları kurunuz.
- Kurulum sonrası java versiyonunu kontrol edelim.
- Birinci maddedeki gibi Windows+R ile çalıştır ekranına gelip oradan cmd ile komut satırını çalıştıralım. Üçüncü maddedeki
java -versionkomutunu çalıştırdığımızda aşağıdaki ekran görüntüsü gelmelidir.
2. Spark’ı İndirme ve Dosyalarını Açma
- Google’da Apache Spark sözcüklerini aratınız veya buradan spark download sayfasına ulaşınız.
- spark-2.3.1-bin-hadoop2.7.tgz linkine tıklayarak Spark’ı indiriniz.
- spark-2.3.1-bin-hadoop2.7.tgz dosyasına sağ tıklayarak 7-zip ile “burada çıkart” diyerek açınız.
- Aynı şekilde spark-2.3.1-bin-hadoop2.7.tar dosyasını bulunduğunuz dizine açınız. En son spark-2.3.1-bin-hadoop2.7 klasörüne ulaşacaksınız.
- C diskinde spark isminde bir klasör yaratınız. spark-2.3.1-bin-hadoop2.7 içindeki tüm dosyaları kesip yeni yarattığınız spark klasörü içine yapıştırınız. Sonuç aşağıdaki resimde görüldüğü gibi olmalıdır.

3. Winutils.exe İndirme ve Yerleştirme
- Buradan winutils.exe dosyasını indiriniz.
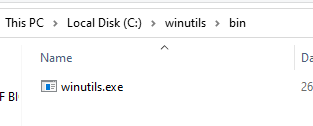
- C dizininde winutils adında bir klasör oluşturunuz. İçine girerek bin isminde bir klasör daha oluşturunuz.
- İndirdiğiniz winutils.exe dosyasını bin klasörü içine taşıyınız. Son hali aşağıdaki resimde görülmektedir.
4. Ortam Değişkenleri
Yeni yüklemelerden sonra JAVA_HOME, SPARK_HOME ve HADOOP_HOME değerlerini ortam değişkenlerine ekleyelim.
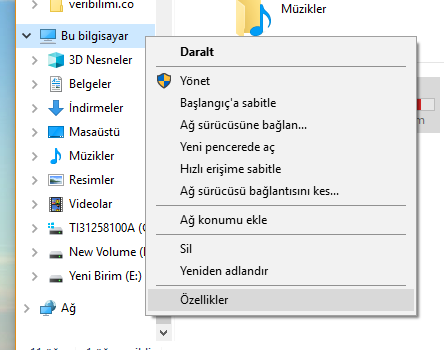
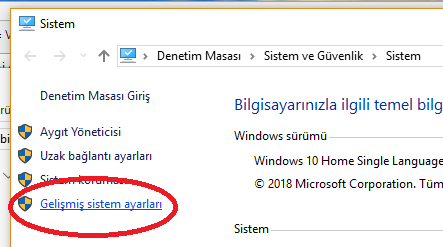
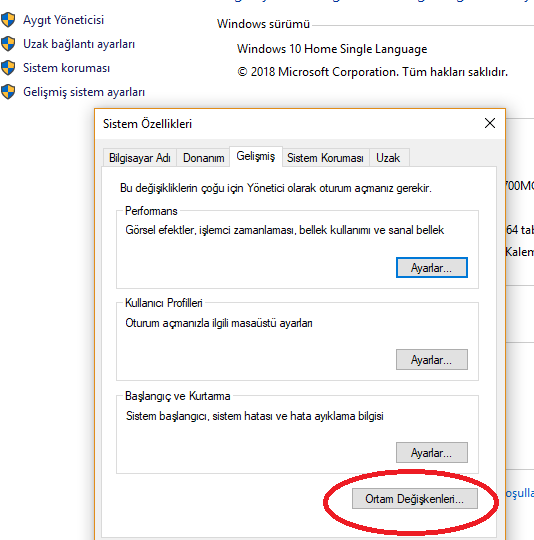
Ortam değişkenlerine aşağıdaki şekillerde görüldüğü şekilde ulaşınız.
=======================
=======================
=======================
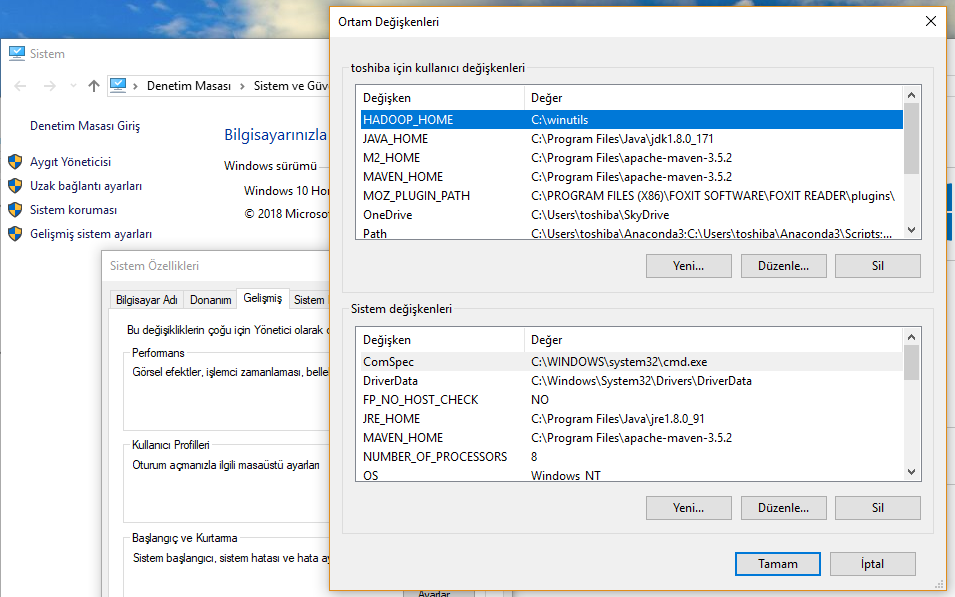
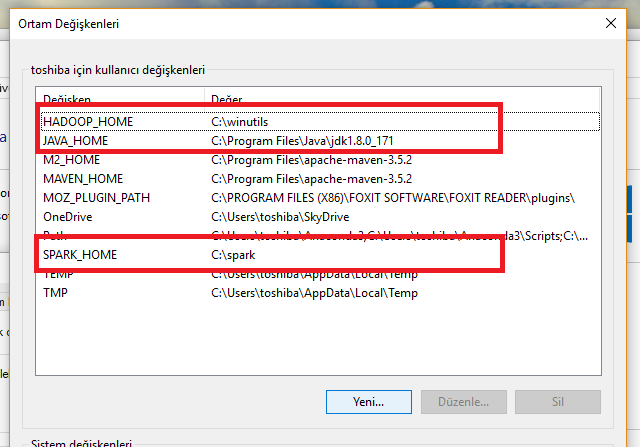
Yukarıdaki ortam değişkenleri penceresine ulaştıktan sonra “Yeni” butonuna basarak aşağıdaki satırları ekliyoruz. Kendi sisteminizde ufak tefek farlılıklar olabilir onları siz kendinize uyarlarsınız.
Home değişkenlerini ekledikten sonra aşağıdaki resimde bulunan Path satırını seçip (1) Düzenle butonuna basınız (2) ve Yeni (3) butonuna basınız. Son iki satırı ekleyiniz.
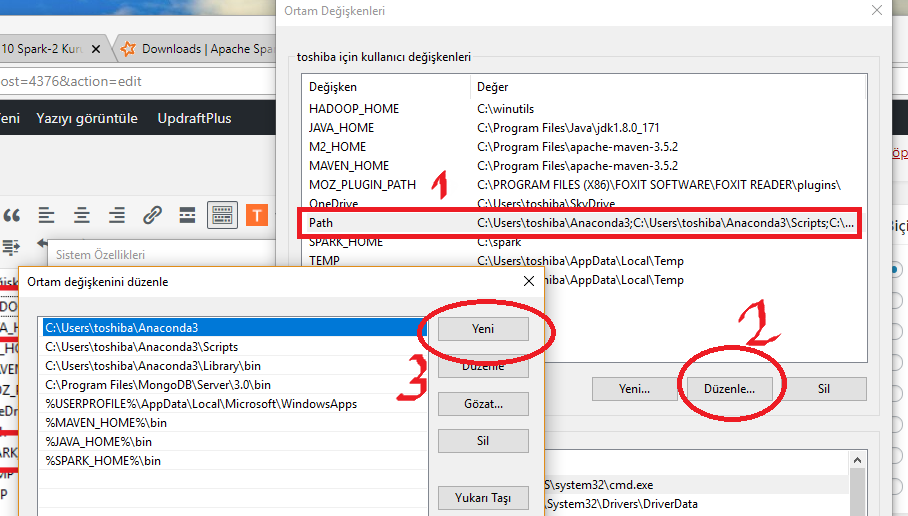
Açılan pencereleri Tamam diyerek kapatarak Windows’u yeniden başlatınız.
5. Spark-shell
Windows başladıktan sonra Windows+R tuşuyla çalıştırı, ardından cmd ile komut satırını başlatınız. Komut satırına spark-shell yazarak Spark’ı başlatınız.
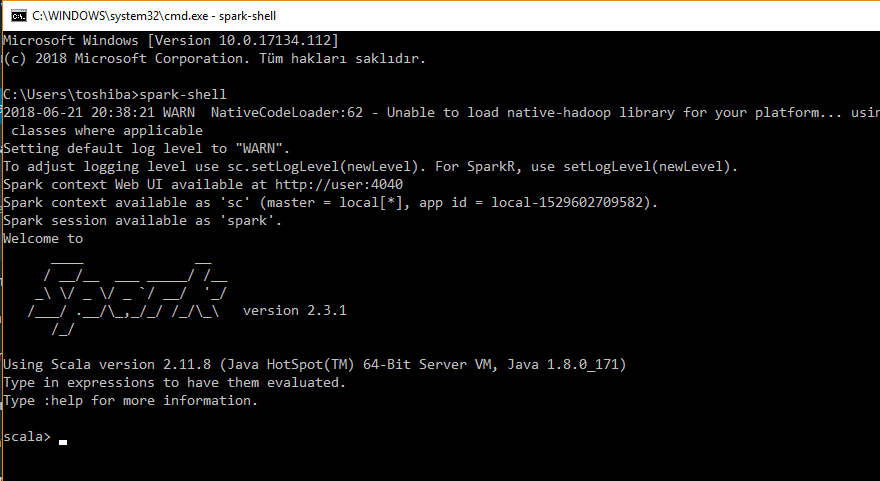
Yukarıdaki sonucu görmüşseniz Spark kabuğunu Scala modunda çalıştırdınız demektir. Çıkmak için :q tuşlayınız. Spark’ı Python (PySpark) ile kullanmak için komut satırına pyspark yazınız.
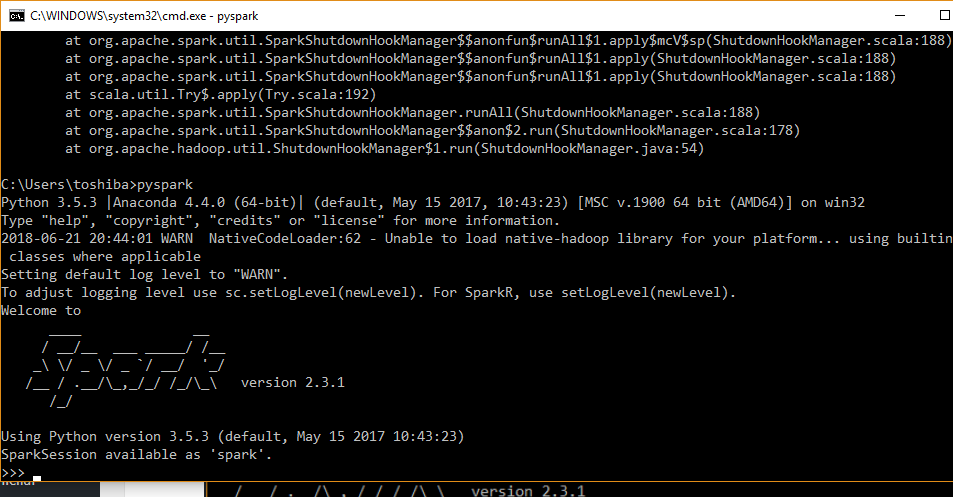
Yukarıdaki ekranı görmüşseniz tebrikler Spark’ı Python (PySpark) ile kullanınız. Çıkmak için exit() yazınız.
6. Muhtemel Hatalar ve Çözümü
6.1. Could not locate executable winutils.exe
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
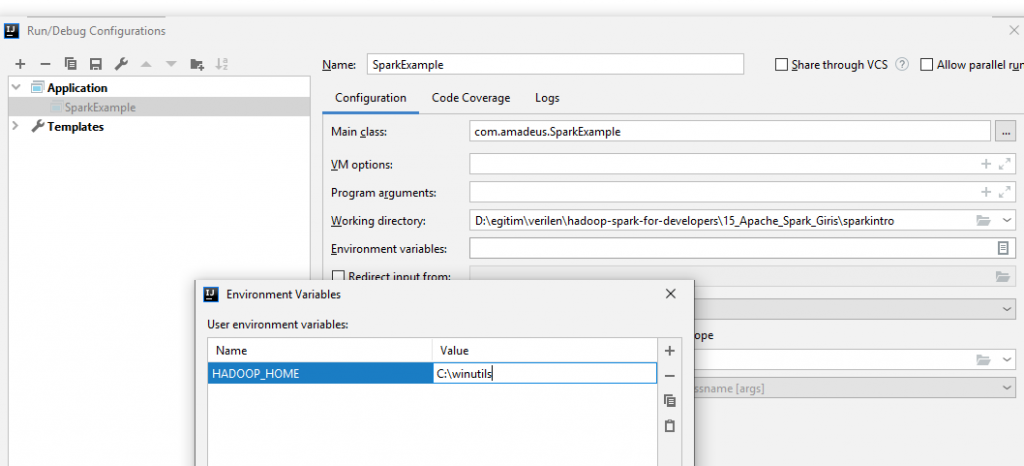
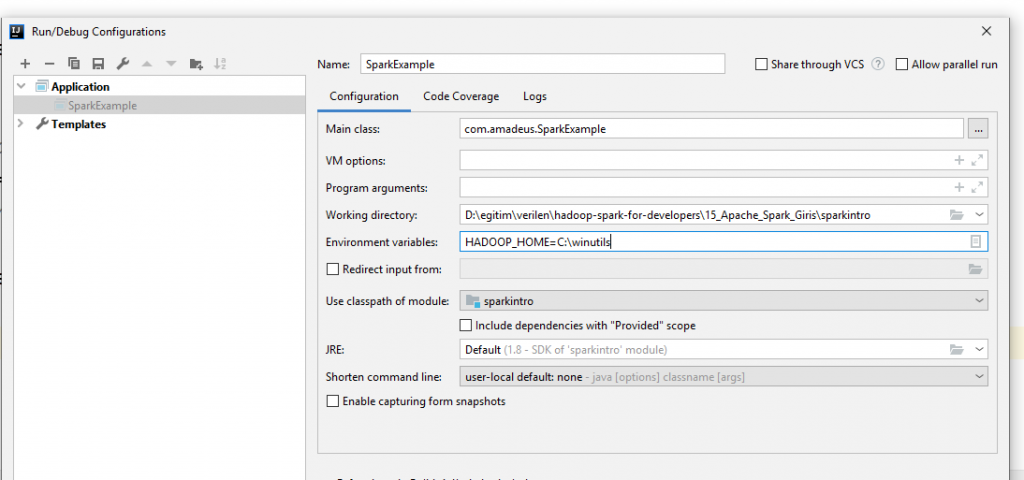
Intellij üzerinde aşağıdaki gibi Environment variables içine HADOOP_HOME ekleyiniz
Spark’ı güle güle kullanınız.
Başka bir yazıda görüşmek üzere, hoşçakalın..