

![]()
AWS Glue, birden çok kaynaktan veri keşfetmeyi, hazırlamayı, taşımayı ve entegre etmeyi kolaylaştıran sunucusuz bir veri entegrasyon hizmetidir. AWS üzerinde ETL ihtiyaçları genellikle Glue ile karşılanır. Bu yazımızda S3 üzerindeki csv dosyalarını parquet formatına çeviren basit bir AWS Glue ETL Job oluşturacağız. Parquet dosyaları analitik sorgular için CSV’ye göre daha performanslıdır ve daha az yer kaplar. Parquet formatı kullanmak hem depolama hem de sorgulama (Örn. Athena) maliyetlerini düşürür.
Örnek uygulamamızın adımları sırasıyla şöyle olacak:
- S3 bucket oluşturup üzerinde csv ve parquet için 2 klasör oluşturma
- CSV dosyalarını S3’e yükleme
- AWS Glue için IAM Role oluşturma
- AWS Glue Job oluşturma
- AWS Glue Job çalıştırma
- Sonuçları (parquet dosyalarını) S3 üzerinde görme
1. S3
1.1. S3 Bucket Oluşturma
Hem csv hem de parquet dosyalarını saklayacağımız S3 bucket ve bunun üzerinde 2 klasör yaratalım.
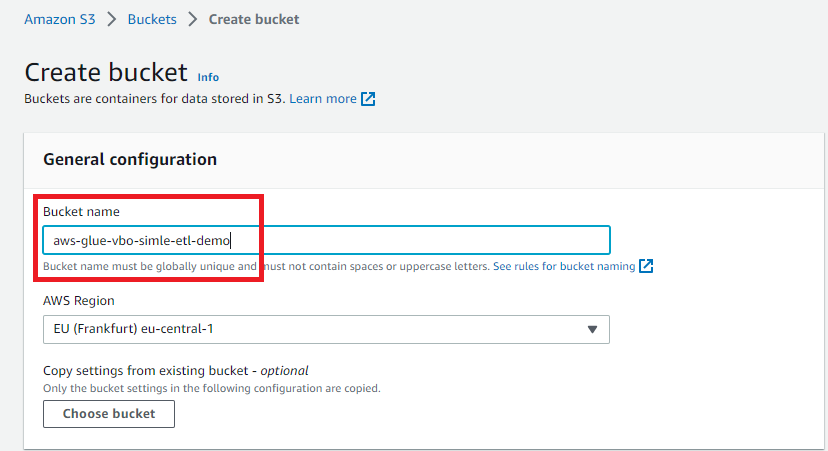
Create bucket butonuna tıkladığımızda açılan sayfada sadece bucket ismi belirleyelim. İsimde aws-glue paterni olmasında fayda var çünkü ileride ekleyeceğimiz AWSGlueServiceRole içindeki politikalardan s3 nesleleri yaratma ve silme ile ilgili olanlarda bu patern var. Farklı bir isim verdiğimizde bu politika işlemeyeceğinden S3 için ayrıca bir role tanımlamak gerekebilir.
1.2. S3 Bucket Üzerinde Klasörleri Oluşturma
Varsayılan ayarlarla bucket yaratabiliriz. Şimdi bu bucket üzerinde csv ve parquet dosyaları için 2 tane klasör oluşturalım.
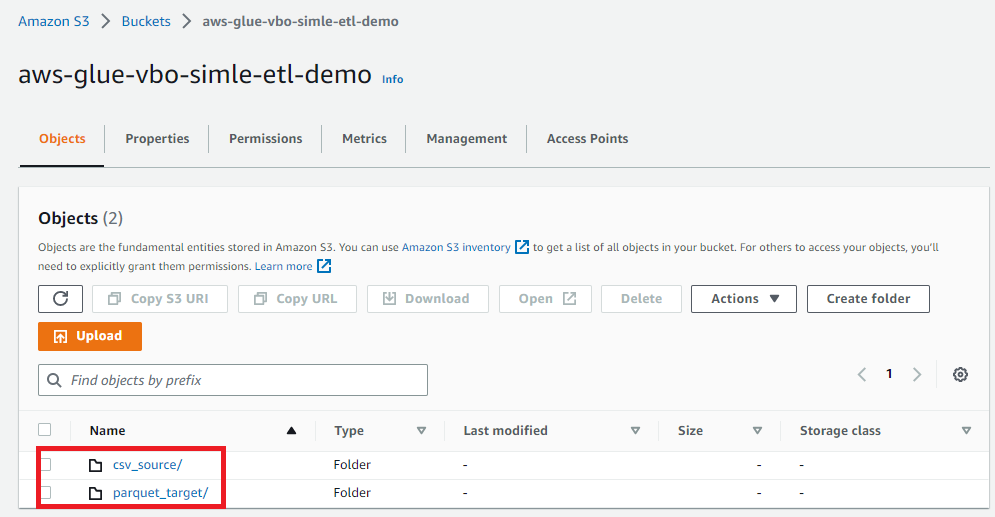
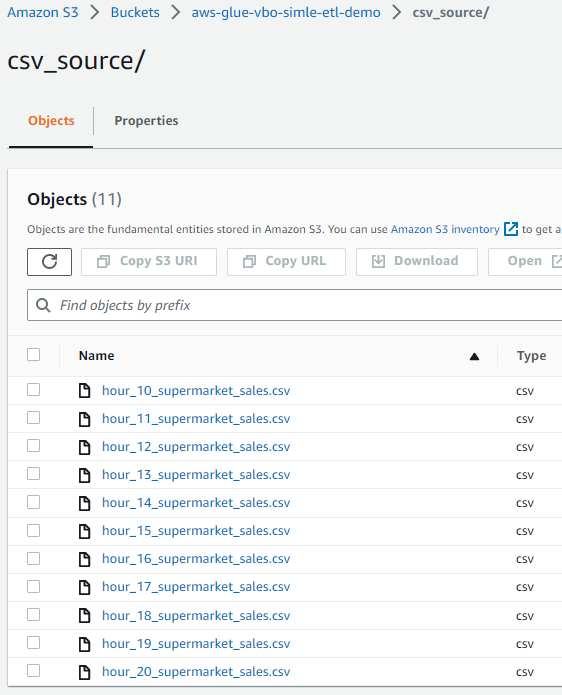
1.3. CSV Dosyalarını S3’e Yükleme
Buradaki csv dosyalarını bilgisayarınıza indirin ve csv_source klasörüne yükleyin. Bir reponun tamamını değilde sadece bir klasörünü zip olarak indirmek için bu sayfayı kullanabilirsiniz.
2. AWS Glue
2.1. Glue IAM Role Yaratma
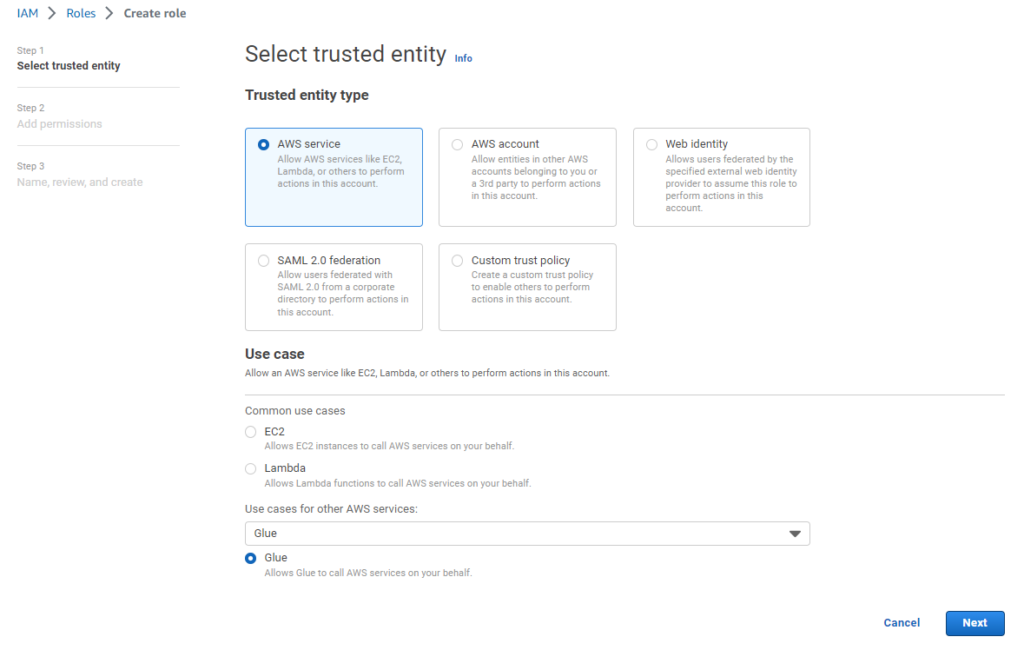
AWS Glue job için kullanacağımız IAM Role yaratalım. Glue servisi bir entegrasyon servisi olduğu için S3 gibi bir çok farklı servis ile alış-verişi var. Amazon bunun için bir politika tanımlamış zaten. Bu politikayı kendi “Glue Job”umuza atamak işimizi görecektir. IAM servisinden;
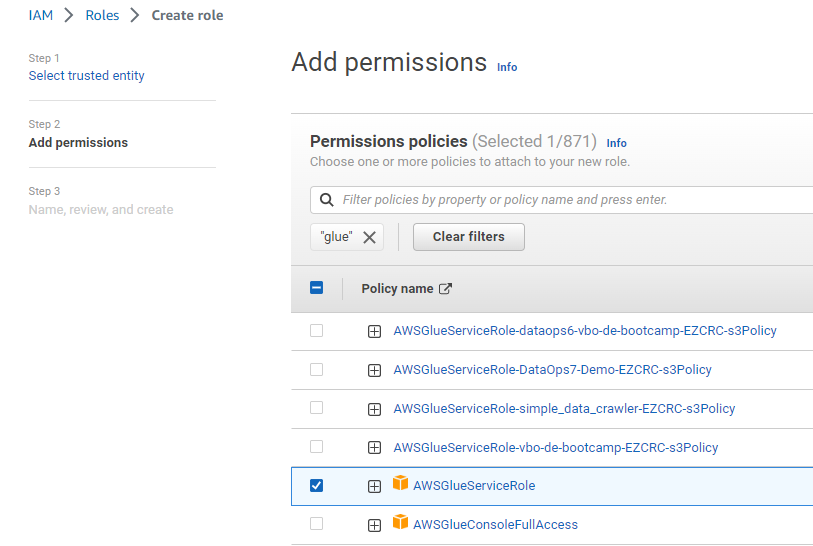
Arama penceresinden glue kelimesini aratınca AWSGlueServiceRole politikası çıkacaktır sonuçlarda. Onu seçelim.
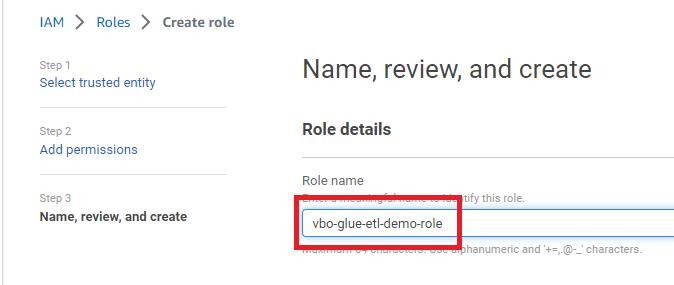
Create role butonuna tıklayarak role oluşturun.
2.2. Glue Job Yaratma
Şimdi Glue servisini açıp bir job yaratalım.
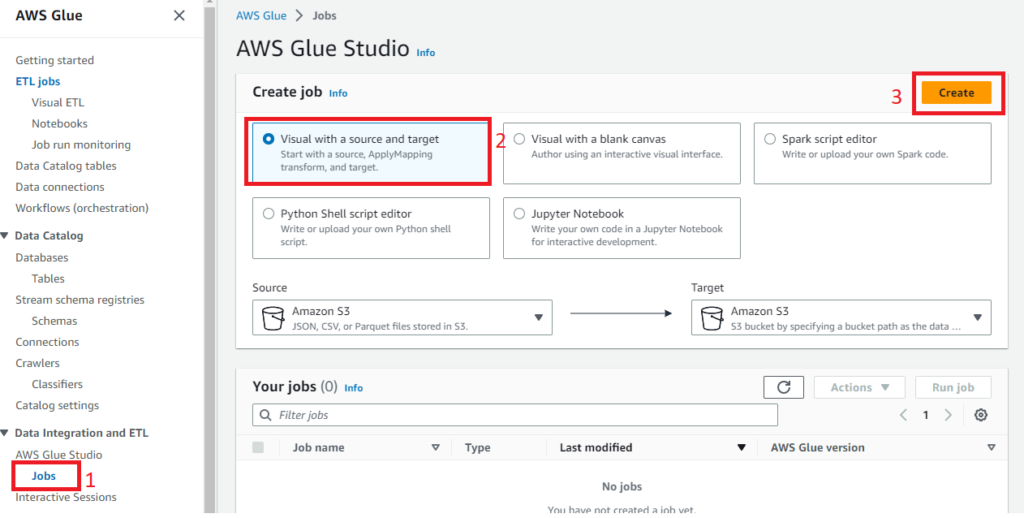
Bir sonraki sayfada karşımıza etl akışının görsel hali gelecek. Burada önce jon ismini (1) girelim. Ardından veri kaynağı düğümünü seçelim (2), seçince sağ menü değişecektir. Burada klasör ismini de içerecek şekilde kaynak S3 bucketi seçelim (3). Browse S3 ile (4) csv_source klasörünü (5) seçelim. Infer schema (6) butonuna tıklayalım.
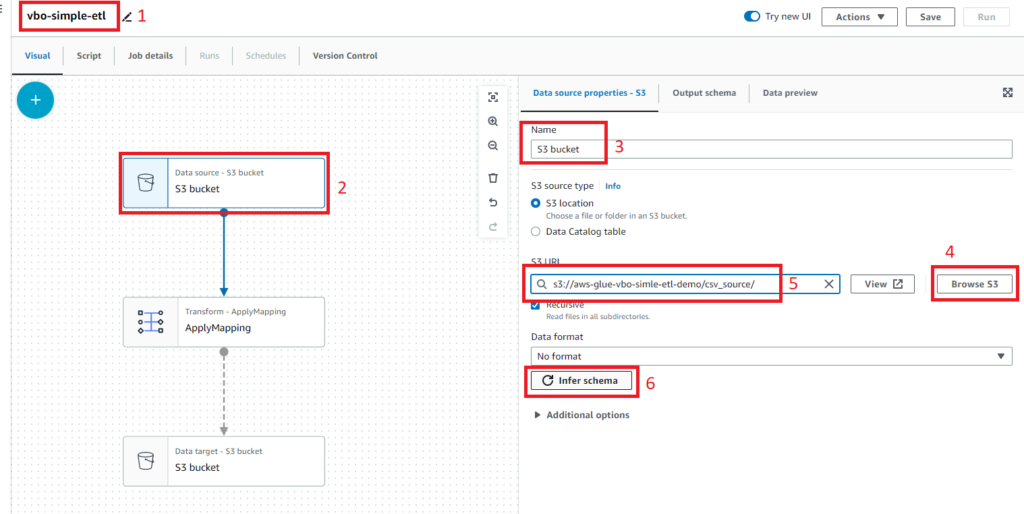
2.3. Transform Apply Mapping Düğümü
ApplyMapping düğümünü seçelim ve şemayı aşağıdaki gibi güncelleyelim.
| invoice_id | string | – |
| branch | string | – |
| city | string | – |
| customer_type | string | – |
| gender | string | – |
| product_line | string | – |
| unit_price | float | – |
| quantity | smallint | – |
| tax5% | float | – |
| Total | float | – |
| Date | string | – |
| Time | string | – |
| Payment | string | – |
| cogs | float | – |
| gross_margin_percentage | float | – |
| gross_income | float | – |
| rating | float | – |
| hour | tinyint | – |
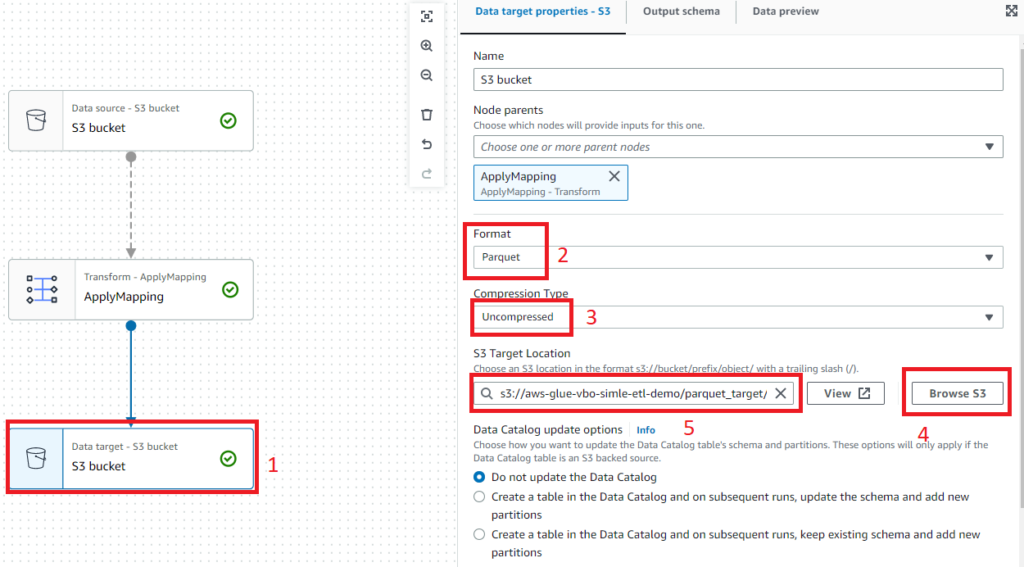
2.4. Data target- S3 Bucket Düğümü
2.5. Job details
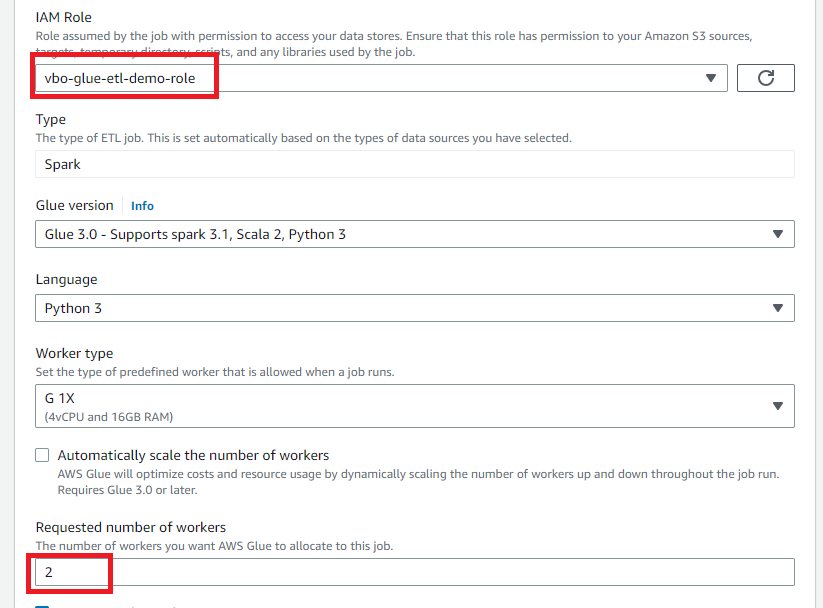
Şimdi kanvasın üstündeki tablardan Job details seçelim. Sadece daha önce yarattığımız IAM Role ve workers için 2 seçmek yeterli olacaktır. Varsayılan 10 workers bizim için fazla olur.
Sağ üst köşeden önce Save ile tanımladığımız işi kaydedelim arkasından Run butonuna basarak ETL işini başlatalım.

Runs tabına tıklayalım ve Job details’i inceleyelim.
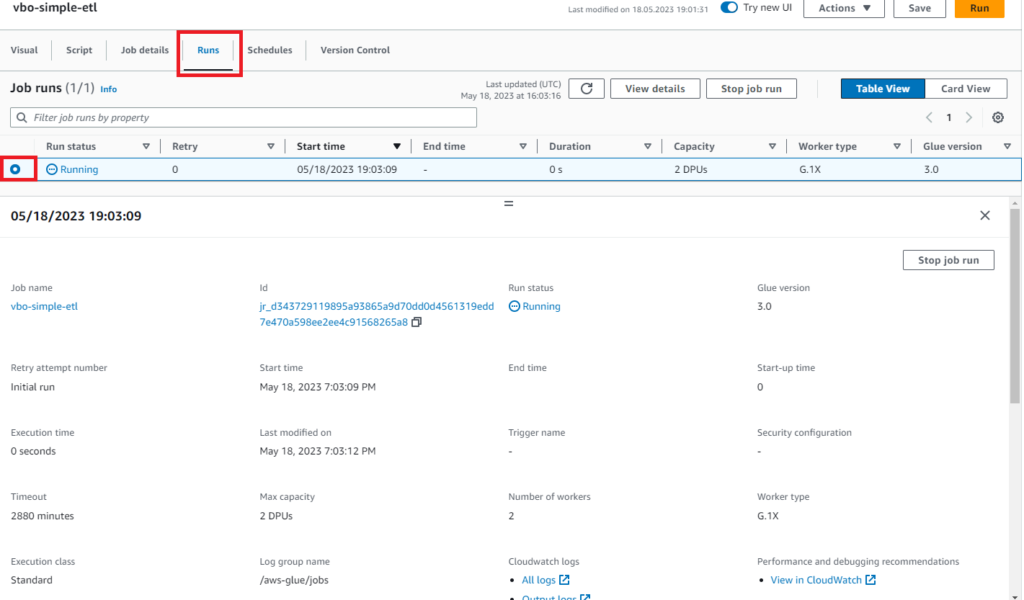
Refresh butonundan sonuçları yenileyelim ve Succeeded durumuna geçtiğini görelim.

3. Sonuçlar için S3
S3 bucket parquet_target klasörünü açıp ve sonuçları görelim. Aşağıdaki gibi parquet uzantılı dosyalar görüyorsak işin başarıyla tamamlandığını doğrulamış oluyoruz.
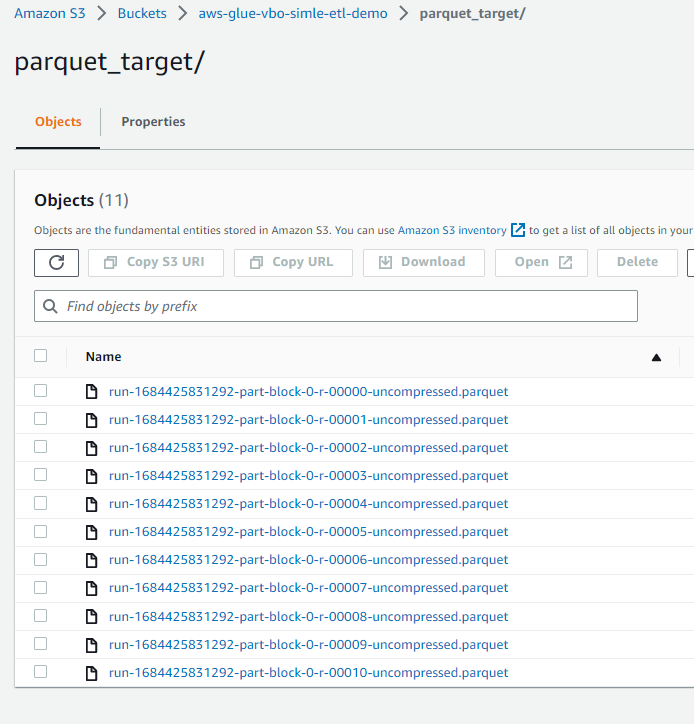
Dilerseniz bundan sonra bu klasörü Athena’da bir tablo olarak tanımlayıp sorgulayabilirsiniz.
AWS Cloud Data Engineering konusunda çok daha fazlasını öğrenmek ve bir kariyer olarak seçmek isterseniz AWS Cloud Data Engineering VideoCamp programımızı tavsiye ederim.
Başka bir yazıda görşmek üzere hoşçakalın…
Kaynaklar
Kapak Görseli: Ricardo Rocha on Unsplash