

![]()
Merhaba. Bu yazımda outlier detection Türkçe ifadesiyle aykırı gözlem (anomali), anormallik tespitinden bahsedeceğim. Yazının devamında aykırı, sıra dışı, anormal, outlier, anomaly, anomali kelimelerini benzer anlamlarda kullanıyor olacağım.
Aykırı gözlem nedir?
Grubbs[1]’a göre aykırı gözlem; “Aynı örneklem içindeki diğer gözlemlerden belirgin derecede farklı olan / sapma gösterendir“.
Belli bir zamana kadar aykırılık tespitine veri ön işlemesinin bir parçası olarak, “bulunup görüldüğü yerde ümüğüne çökülmesi gereken” gözlemler olarak yaklaşılmış. Ancak bu yaklaşım 2000’li yıllardan sonra değişmeye başlamış. Artık aykırılar bulunup yok edilmesi gereken uzaylı yaratıklar değil. Elbette hala öyle olanlar da var ancak bir çok iş probleminde kendileri artık altın değerindeler. Niçin derseniz? Bilgisayar ağlarında aykırı bağlantıları ve bankacılıkta aykırı/sahteci işlem ve davranışları tespit etmek başlı başına bir amaç, yani altın değerinde. Bulun bankacılara sahtecileri, yığsınlar önünüze altınları.
Şimdi aykırılık tanımına biraz daha kafa yoralım. Ne anladık yukarıdaki tanımdan? Öncelikle bunlar normallerden farklılar. İkinci olarak bu farklılık özelliklerden kaynaklanıyor. Üçüncü olarak ise normallere göre çok azınlıktalar.
Bir Anormallik Tespiti Sistemi Nasıl Bir Çıktı Üretir?
Bir anormallik tespit modeli iki farklı sonuç üretir. Birincisi, gözlemin anormal olup olmadığına dair kategorik bir etiket; ikincisi ise bir skor ya da güven değeri. Skor etikete göre daha çok bilgi taşır. Çünkü bize gözlemin ne derecede anormal olduğunu da söyler. Etiket ise sadece anormal olup olmadığını söyler. Gözetimli (supervised) yöntemlerde etiket daha yaygın iken gözetimsiz (unsupervised) ve yarı gözetimli (semisupervised) yöntemlerde skor daha yaygındır. Skor kullanılırken genelde skorlar büyükten küçüğe sıralanır ve en anormal 20 gözlem, en anormal 50 gözlem şeklinde kullanıcıların nazarına sunulur. İstenilirse bir eşik değeri kullanılarak skorlar etiketlere çevrilebilir.
Artık gelelim konumuza. Aykırılık tespit yöntemlerini sınıflandırabilir miyiz? Sınıflandırabilir isek nasıl olur bu? sorularının cevabını devam eden başlıklarda bulabileceğimizi umuyorum.
Aykırılık Tespit (Outlier Detection) Yöntemleri Sınıflandırma
Aşağıdaki şekil sınıflandırmayı biraz daha anlaşılır kılacaktır.

Algoritma Stratejisi Bakımından
Olasılığa Dayalı (Probabilistic) Yöntemler
Olasılığa dayalı ve istatistiksel modellerde veri kapalı form olasılık dağılımı şeklinde modellenir ve bu modelin parametreleri öğrenilir. Dolayısıyla burada anahtar varsayım spesifik veri dağılımı seçimidir. Örneğin Gauss karışık modeli, veri üretken bir sürecin çıktısıdır ve her nokta k adet Gauss kümesinden birine aittir. Bu Gauss dağılımının parametreleri beklenti-maksimizasyonu (expectation-maximization-EM) algoritması ile öğrenilir. Bu modelde önemli bir sonuç da veri noktalarının her bir kümeye ait olma olasılıklarıdır ya da yoğunluğa dayalı model uyumudur.
Mesafe Bazlı (Distance-Based) Yöntemler
Bu yöntem, gözlemlerin benzerlik ve farklılıklarını aralarındaki mesafeye göre belirler. Mesafe ölçümü Öklid, Mahalanobis vb. yöntemlerle yapılır.
Komşu Bazlı (Neighbor-Based) Yöntemler
Komşu bazlı yöntemler, aykırı noktaları belirlemek için her bir veri noktasının çevresini inceler.
Bilgi Teorisi (Information-Theoretic) Modelleri
Yukarıda bahsedilen modellerin çoğu genelleyici modellerdir. Bu modellerde, genelden tespit edilen sapmalar anormal kabul edilir. Bilgi Teorisinde de benzer bir yaklaşım biraz farklı bir istikamette uygulanır. Veri setini tanımlamayı güçleştiren veya tanım için kullanılacak kod veya cümleyi uzatan kayıtlar anormallik ölçütü olarak alınır. Örneğin bir kutuda 50 adet kırmızı top olsun. Kutu içindeki veriyi tanımlarken 50 kırmızı top diye tanımlarken içine iki mavi, üç yeşil, iki beyaz top atıldığında tanım uzayacaktır. Tanımı uzatan toplar anormal olarak kabul edilir.
Yapay Sinir Ağları (Neural Networks)
Yapay sinir ağları kullanarak da anomali tespiti yapılabilir. Gözetimsiz (unsupervised) yöntemlerde öne çıkan iki yöntem vardır: Kendini Örgüleyen Ağ (Self-Organizing Map – SOM) ve Otomatik kodlayıcı (Autoencoder). SOM düğümler ve kenarlar ekleyerek/çıkararak kendini veriye uydurur ve böylelikle aykırıları ortaya çıkarır. Otomatik kodlayıcı ise orijinal verileri gürültüyü görmezden gelerek bir kısa koda sıkıştırmaya başlar. Ardından, algoritma orijinal girişe olabildiğince yakın bir görüntü oluşturmak için bu kodu geri açar. Bu esnada orijinal giriş ile farklılıklar olacaktır. Aykırı değerler daha yüksek yeniden yapılandırma hatası olacaktır, bu hata değerleri aykırı değerlerin otomatik kodlayıcı kullanılarak tespit edilmesini sağlar.
Alan Bazlı (Domain-Based) Yöntemler
Verilerin giriş alanının kalanından ayıran bir sınırın oluşturulmasına dayanarak nominal sınıfın alanını tahmin eder. Sınırlandırılmış sınırın dışına düşen herhangi bir veri noktası bu nedenle sıra dışı olarak işaretlenir. Örneğin Destek Vektör Makineleri (Support Vector Machines-SVM) alanından Tek Sınıflı SVM(One-class SVM)
Çok Boyutlu (High-Dimensional) Verilerde Aykırılık Tespiti
Bir sürü nitelik gürültülü ve bazıları birbiriyle alakasız olacağından çok boyutlu veride anormallik analizi yapmak güçtür. Alakasız nitelikler; mesafelerin düzgün ve hassasiyetle hesaplanmasını güçleştirir. Çok boyutlu veride boyut arttıkça verinin seyrekleşme eğilimi de artar. Noktaların mesafelerinin ayırt edici gücü azalır. Böylelikle anormallik skoru noktaları birbirinden ayıramaz. Böyle durumlarda alt uzay anormallik tespiti yapılır. Bu yaklaşım anormallerin alt uzayda da gizli ve alışılmadık davranışlar gösterdiği varsayımına dayanır.
Aykırılık Tespitinde Öğrenici Toplulukların Kullanımı (Outlier Ensembles)
Rastgele Orman (Random Forest) yönteminde olduğu gibi sınıflandırma ve kümelemede birçok zayıf öğrenici bir araya gelerek daha güzel sonuçlar üretebilmektedir. Benzer yöntem aykırılık tespitinde de kullanılabilmektedir. Bu yöntemler ardışık (sequential ensembles) ve bağımsız yöntemler (independent ensembles) olmak üzere ikiye ayrılabilir.
Model Eğitiminde Etiketli Veri Kullanılıp Kullanılmaması Bakımından:
Gözetimli Aykırı Gözlem Belirleme (Supervised Outlier Detection)
Bu yöntemde model eğitilirken kullanılan veri etiketlidir. Yani daha önceden elle veya başka bir sistem ile hangi gözlemin aykırı değer (outlier) olduğu bilinmektedir. Ayrıca model eğitilirken bu etiketlerden faydalanılmaktadır.
Gözetimsiz Aykırı Gözlem Belirleme (Unsupervised Outlier Detection)
Bu yöntemde model eğitilirken kullanılan veri etiketli olabilir veya olmayabilir. Etiketli olsun olmasın bu yöntemi gözetimli (supervised) yöntemlerden ayıran en önemli husus model eğitimi esnasında etiket bilgisinin kullanılmamasıdır.
Aykırı Gözlem Arayışının Lokal veya Genel Olması Bakımından (Bölgelere Göre)
Lokal Aykırı Gözlem Belirleme (Local Outlier Detection:
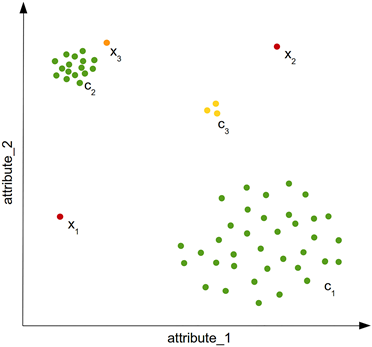
Veri setinin tamamına bakıldığında anormal görünmeseler de lokal yoğunlukların gözlendiği bölgelere odaklanıldığında bu bölgede anormal gözlemler olabilir. X3 buna örnektir.
Genel Aykırı Gözlem Belirleme Global Outlier Detection:
Veri setinin tamamı nazara alındığında diğerlerinden ayrı düşen gözlemlerdir. Aşağıdaki şekilde X1 ve X2 global anomali gözlemlerdir.
Küçük Kümeler (Micro clusters)
Bazı kümeler C3 örneğinde olduğu gibi veri seti içindeki diğer kümelere göre az sayıda olabilir. Peki bu gözlemlere normal bir küme (cluster) olarak mı bakacağız yoksa hepsine anormal mi diyeceğiz. Cevabı kolay olmayan bir soru. Bu gözlemlere skor üreten algoritmalar açıkça anormal olanlar kadar yüksek puan vermeseler de normalleden biraz daha yüksek puan verirler.
Aykırı Gözlem Anlayışına Göre
Her ne kadar genel kabul, anormallerin azınlık olduğu ve sık gözlenmediği yönünde olsa da bazı durumlarda anormaller daha sık gözlenir. Hatta belli bir örüntüye sahip olabilirler. Böylece kendiler sanki normalmiş gibi büyük bir küme altında toplanabilirler.
Nokta Bazlı Anomali Belirleme (Point Anomaly Detection)
Büyük bir veri setinde anormalleri tek tek tespit etmeye çalışmaktır. Neredeyse mevcut tüm anormallik tespit algoritması bu türdendir.
Toplu Anomali Belirleme (Collective Anomaly Detection)
Anormal gözlemler birbirine benzeyen ve gruplar halindedir.
Bağlamsal Anormallik (Contextual anomaly)
Anormalliğin yere ve şartlara göre, kısacası bağlama göre tespitidir. Bir yılı göz önüne aldığımızda 26 derece anormal bir sıcaklık sayılmaz ancak zamanı Ocak ayına çektiğimizde 26 derece anormal bir sıcaklıktır. Ya da 10 derece sıcaklık kutuplara yakın yerlerde normal iken ekvatora yakın yerlerde anormaldir.
Üretilen Sonuç Bakımından
Aykırı Değer / Aykırı Değer Değil Olmak Üzere Kategorik Sonuç
Üretilen sonuç, gözlemin outlier olup olmadığını seklinde kategoriktir.
Skor:
Üretilen sonuç gözlemin outlier derecesini belirten bir puandır. Örneğin puan ne kadar yüksek ise o derecede aykırı bir gözlem olarak değerlendirilir. Bu şekilde üretilen puanlara bir eşik konularak kategorik sonuçlar rahatlıkla elde edilebilir.
Sonuç
Bu yazımızda aykırılık tespiti yöntemlerini sınıflandırmaya çalıştık. Başka bir yazıda görüşmek dileğiyle hoşçakalın.
Kaynakça
- Grubbs FE. Procedures for Detecting Outlying Observations in Samples. Technometrics. 1969; 11(1):1–21. doi: 10.1080/00401706.1969.10490657
- Goldstein, Markus, and Seiichi Uchida. “A comparative evaluation of unsupervised anomaly detection algorithms for multivariate data.” PloS one 11.4 (2016): e0152173.