

Yaşamımız boyunca karar aldığımız pek çok şey var. Olası bir sürü sonucu olabilecek durumlar için karar almaya çalışıyoruz. E bir yandan da istatistiksel düşünmeye alıştığımız için, “her bir değişkenin alınacak kararın farklı çıktılarıyla nasıl ilişkilidir?” sorusu gelmiyor değil aklımıza. Yaşam içerisinde aldığımız, sıradan gördüğümüz kararları bile teorik olarak sorma kabiliyetine sahip olduğumuz için 🙂 yanıtlarına da teknik yaklaşabiliyor muyuz deneyelim görelim.
Kullanılan değişkenlerden hangisi ya da hangilerinin dikkate alınması gerektiği (sevgilimden ayrılsam mı ayrılmasam mı gibi :)) ve her bir değişkenin kararın farklı çıktılarıyla nasıl ilişkili olduğunun belirlenmesi amacı ile mantığının programlama ortamına aktarılmasında kullanılan karar ağacı yöntemini inceleyelim. Öncesinde kısaca nedir diye bir konuşalım.
Ağaç görünümünde olan karar ağaçları, tanımlayıcı ve tahmin edici modellerdir (Emel ve Taşkın, 2005: 222). Aslında muhtemel sonuçların ve kararların gösterilmesinde kullanılan bir destek aracıdır. Genellikle, araştırma uygulamaları için bir sonuca ulaşabilmek için izlenecek yolun belirlenmesinde kullanılmaktadır (Uysal ve Güyer, 2014: 34). Tümevarım yöntemiyle elde edilen ve sınıfları bilinen örnek veriden oluşturulan bir karar yapısı çeşidi olan karar ağaçlarında (SPSS, 1999: 2), basit karar adımlarının uygulanması sonucu büyük miktarda kayıt içeren veri kümesinin, çok küçük kümelere bölünerek sonuç gruplarına ait her bir değişken diğerleriyle daha çok benzer hale getirilmektedir (Sun ve Hui, 2008: 1-2). Sınıflama problemlerinde doğrusal olmayan ve karmaşık veya hata içeren bilgiler için karar ağaçlarının kullanılması faydalı bir çözümdür. Sınıflama modellerinin içerisinde, güvenilirliklerinin yüksek olması, yorumlamanın kolay olması ve veri tabanlarına kolayca entegre edilebilmesi açısından yaygın kullanılan tekniktir (Türe ve ark., 2009:2017-2018).
Karar ağaçlarının oluşturulmasında bazı algoritmalar geliştirilmiştir. Bu algoritmalar, CHAID (Chi-Squared Automatic Interaction Detector), Exhaustive CHAID, SPRINT (Scalable Paralleizable Induction of Decisin Trees), C5.0, SLIQ (Supervised Learning in Quest), ID3, C4.5, CRT (Classification and Regression Trees), QUEST (Quick, Unbiased, Efficient Statistical Tree) ve MARS (Multivariate Adaptive Regression Splines) olarak sıralanabilirler (Albayrak ve Koltan Yılmaz, 2009: 40). Uygulamada sıklıkla kullanılan CHAID algoritması, Kaas tarafından 1980 yılında tanıtılmıştır. Kaas’ın bu algoritmasında temel amaç, en iyi bölmenin hesaplanması için istatistiksel olarak anlamlı bir farkın olmadığı, hedef değişkene uyan çiftler arasından tahmin değişkeninin olası kategori çiftlerinin birleştirilmesidir (SPSS, 1999:2). En uygun bölmenin hesaplanmasında, kullanılan tahmin değişkenleri hedef değişkene uyan çiftin içerisinde istatistiksel olarak anlamlı fark kalmayana kadar birleştirilmektedir. CHAID algoritmasında, en uygun bölümlerin belirlenmesinde ki-kare testi kullanılmaktadır. Algoritma, yalnızca nominal veya orantısal kategorik tahmincileri kullanmaktadır. Sürekli olması durumunda, kullanılmasından önce sıralı belirleyicilere dönüştürülmesi gerekmektedir. Yukarıda sıralanan diğer algoritmalar ikili ağaçlar türetirken, bu algoritmanın çoklu ağaçlar türetmesi en önemli farklılıktır (Türe ve ark., 2009:2019-2020).
E hadi o zaman hemen bir örnek yapalım. Mesela ufacık bir anket göstereyim size 🙂
Aşağıda görseli verilmiş olan, Twitter üzerinden yapılan ekonomik paylaşımlara göre yatırım ve tasarruf hareketleri yapmayı düşünür müsünüz?
Görseli verilmiş olan yatırım araçlarını yatırım tercih önceliğiniz doğrultusunda sıralayınız.

Bu iki soru arasında değerlendirme yapacak olursak, Bireylerin yatırım araçlarından Euro’yu tercih etmeleri durumu Twitter’da döviz, borsa, altın ve tahvil piyasalarına dair ekonomik göstergeleri takip etme durumunun hangi değişkenler tarafından açıklandığını incelemek amacıyla oluşturulan karar ağacını hemen veriyorum.
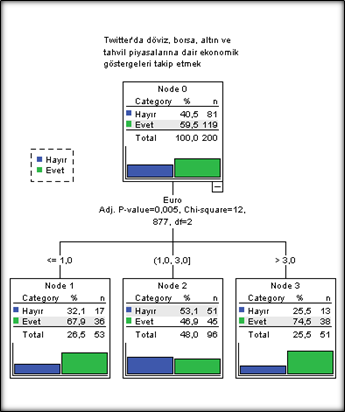
Bireylerin yatırım araçlarından Euro’yu tercih etmeleri durumu Twitter’da döviz, borsa, altın ve tahvil piyasalarına dair ekonomik göstergeleri takip etme durumunun en iyi ve istatistiksel olarak en önemli göstergesidir. (Diğer yatırım araçlarından daha önemli çıktı, bu da ayrı bir konu oluverdi bir anda :)). Toplam 53 bireyin yer aldığı ve Euro yatırım aracının 1.sırada tercih edildiğini ifade eden 1. profilin (Node 1) %67.9’unu ekonomik göstergeleri takip eden ve hesabı olması durumunda takip etmek isteyenler oluştururken, toplam 96 bireyin yer aldığı ve Euro yatırım aracının 2.sırada tercih edildiğini ifade eden 2. profilin (Node 2) %46,9’unu ve toplam 51 bireyin yer aldığı 3 ile 4.sırada tercih edildiğini ifade eden 3.profilin (Node 3) %74,5’ini ekonomik göstergeleri takip eden ve hesabı olması durumunda takip etmek isteyenler oluşturmaktadır.
İyi güzel bir ağacımız oldu. Ama bunu öyle hemen yorumlamak doğru mu oldu? Burada sorulması gereken soru, “modele ait risk tahmini nasıl?” olmalıdır. Hemen bu sonuca da bakalım;

Risk tahmini 0,375 değeri, modelin tahmin ettiği kategorinin (Euro yatırım aracı sıralaması) ekonomik göstergeleri takip etmenin % 37,5’inde yanlış olduğunu göstermektedir. Yani bir bireyi yanlış sınıflandırmanın riski yaklaşık % 37’dir.
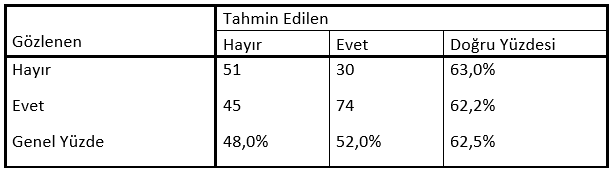
Sınıflandırma tablosundaki sonuçlar risk tahmini ile tutarlıdır. Tablo, modelde ki bireylerin yaklaşık %62,5’ini doğru şekilde sınıflandırdığını göstermektedir. Görüldüğü üzere, kategorik bağımlı değişken için genel doğru sınıflandırma oranı ile benzer bir yorumu vardır. Hop yapıldı bitti bile 🙂 Çok daha karmaşık konularda bile karar alınmasında istatistiğin faydaları diyebiliriz değil mi? (Sevgiliden ayrılırken çok daha fazla kritik durumun değerlendirilmesi gibi :)). Kararlarımızı olası sonuçlarına göre düşünelim, inceleyelim ve alalım. Ama bazen de istatistikçi olarak bakmayalım 🙂
Referanslar
ALBAYRAK, A.S. ve KOLTAN YILMAZ, Ş. (2009). Veri Madenciliği: Karar Ağacı Algoritmaları ve İMKB Verileri Üzerine Bir Uygulama. Süleyman Demirel Üniversitesi İktisadi ve İdari Bilimler Fakültesi Dergisi. 14.1, 31-52.
EMEL, G. G. ve TAŞKIN, Ç. (2005). Veri Madenciliğinde Karar Ağaçları ve Bir Satış Analizi Uygulaması. Eskişehir Osmangazi Üniversitesi Sosyal Bilimler Dergisi. 6.2, 221-239.
SPSS, (1999). AnswerTree Algorithm Summary. ABD: SPSS White Paper.
SUN, J. ve HUI. L. (2008). Data Mining Method for Listed Companies, Financial Distress Prediction. Knowledge-Based Systems, 21.1, 1-5.
TÜRE, M., TOKATLI, F. ve KURT, İ. (2009). Using KaplanMeirer Analysis Together With Decision Tree Methods (C&RT, CHAID, QUEST, C4.5 and ID3) In Determining Recurrence-Free Survival of Breast Cancer Patients. Expert Systems With Applications. 36, 2017-2026.
UYSAL, M. ve GÜYER, T. (2014). İstatistiksel Veri Analizine İlişkin Genişleyebilir Bir Karar Ağacı Tasarımı. Bilişim Teknolojileri Dergisi. 7.3, 33-43.