

![]()
 İnsanlık, Büyük Biraderini Arıyor…
İnsanlık, Büyük Biraderini Arıyor…
George Orwell, 1984 romanında totaliter bir yönetim yapısından bahseder. Bu yapı ile insanların tüm aktiviteleri devlet tarafından yönetilir, denetlenir ve hiçbir şekilde özgürlük tanımına yer verilmez. Düşünce Polisi insanların yaşamlarını, özel hayatlarını hatta düşüncelerine kadar takip eder. Kitapta belirtilen takip mekanizması, 70 yıl önce yazılmış bir kitaba göre, günümüz teknolojileri ile birçok benzerlikler göstermektedir.
Şuan kullandığımız Facebook, Instagram gibi birçok uygulamayı ücretsiz bir şekilde kullandığımızı düşünüyoruz… Ancak bu kullanımın karşılığı olarak büyük bir veri kaynağı sağlıyoruz ve günümüzde en değerli şey olan kişisel verilerimizi gözümüz kapalı bir şekilde birilerine teslim ediyoruz. 21. Yüzyılın en büyük deneyi yapılıyorken biz, her şeyden habersiz bir şekilde profillerimizi daha iyi sınıflandırmaları için her gün düzenli bir şekilde veri sağlıyoruz…
Bu teknolojiler yardımıyla kurulan modeller veya sistemler kısa vadede değil, uzun vadede yönetim mekanizmaları için vazgeçilmez birer araç olabilir. İnsanlar daha ne olduğunu anlamadan sistemler kurulmuş olabilir. Yönetim sistemleri, denetim sistemleri, adalet sistemleri tek bir merkez tarafından, Büyük Birader denilen karakter veya bir Yapay Zeka tarafından, yönetilebilir. Büyük Birader siyah dekorlu odasında ellerini ovuşturarak o günü beklerken büyük şirketler hangi savda yer alacaklar? Sizce, insanlık tarihinde elde edilebilecek en büyük güç hangi amaçlar için kullanılacak? Aylık distopya dozumuzu aldıysak, Kategorik Veri Analizi için yeni bir uygulamaya başlayabiliriz 🙂
İkili Lojistik Regresyon
Bundan önceki yazılarımda model tahmini, modelin ve katsayıların anlamlılık testleri ve güven aralıkları konularını teorik ve uygulamalı olarak işlemiştik. Şimdi yeni bir veri seti kullanarak tüm bu özellikleri tekrar gözden geçireceğiz.

Düşük doğum ağırlığına ait veri setimizi bir değişkene kaydettik.

glm() fonksiyonu yardımıyla modelimizi kurduk ve summary() fonksiyonu ile model hakkında bir özet bilgi elde ettik.
“Yaptığınız, söylediğiniz ya da düşündüğünüz her şeyi en ince ayrıntısına dek ortaya çıkarabilirler ama gönlünüzün derinliğine, işleyişine, sizin bile bilmediğiniz o yere el uzatamazlar.”(Orwel, 1984)
Model
![]()
Yukarıda elde edilen model Doğrusal Regresyon Modeli olarak tahmin edilseydi “yaş değişkeni bir birim arttırıldığında, düşük doğum ağırlığında … kadar artış veya azalış olur” gibi bir yorum yapabilirdik, ama Lojistik Regresyon Modeli ile tahmin ettiğimizden bu yorumu yapamıyoruz malesef :). Modelin anlamlı olup olmadığına karar verdikten sonra Logit Fonksiyonundan yararlanarak bir güven aralığı elde etmeli ve bu değerler üzerinden yorumlama yapmalıyız.
Model Anlamlılığı

Model anlamlılığını test ederken, bağımlı değişken üzerinde etkisini olduğunu düşündüğümüz tüm değişkenlerin 0 değerine eşit olup olmadığını test ediyoruz. Burada dikkat edilmesi gereken, ![]() değişkeninin anlamlılığını test etmiyor olmamız. Bunun sebebi, zaten
değişkeninin anlamlılığını test etmiyor olmamız. Bunun sebebi, zaten ![]() değişkeni modelde hiçbir değişken yokken, yada tüm bağımsız değişkenler 0 değerini aldığı zaman, bağımlı değişkenin ortalama değeridir. Yani annenin yaşı veya sigara içip içmemesi durumu dikkate alınmadan ortalama düşük doğum sayısını verir.
değişkeni modelde hiçbir değişken yokken, yada tüm bağımsız değişkenler 0 değerini aldığı zaman, bağımlı değişkenin ortalama değeridir. Yani annenin yaşı veya sigara içip içmemesi durumu dikkate alınmadan ortalama düşük doğum sayısını verir.

G test istatistiği ile k=2 serbestlik dereceli Chi-Square tablo değeri ile karşılaştırdık ve %95 güvenle modelin anlamlı olduğuna karar verdik. Bir önceki yazıdan, model anlamlılığı için kullanılan G istatistiği ve değişken anlamlılığı için kullanılan Wald test istatistiğinin aynı sonuca ulaşabildiğimizi biliyoruz. Burada birden fazla bağımsız değişken olduğu için ayrı ayrı Wald testi uygulayıp değişkenleri ayrı ayrı incelememiz gerekiyor. Bu bölümde modelin anlamlı olduğuna karar verdik, ancak hangi değişkenin anlamlı olduğunu henüz bilmiyoruz. O yüzden yapılabilecek en mantıklı yorum; annelerin düşük doğum ağırlığına sahip olup olmaması, annenin sigara içip içmemesi ve yaşı değişkenlerinden en az bir tanesi ile açıklanabilmektedir, şeklinde olacaktır.
Katsayıların Anlamlılığı

Şeklinde kurulan hipotezde wald test istatistiği;
 fonksiyonu ile hesaplanır. Bu değişkenleri summary() fonksiyonu ile model için çıkardığımız özet bilgiden kolaylıkla elde edebiliriz.
fonksiyonu ile hesaplanır. Bu değişkenleri summary() fonksiyonu ile model için çıkardığımız özet bilgiden kolaylıkla elde edebiliriz.

Yas değişkeni için hesapladığımız Wald değeri ile tablodan hesapladığımız Z değerini karşılaştırıyoruz. Burada hesaplanan Wald değeri, Z tablo değerinin sağ tarafındaki 1.96 değer ile karşılaştırılıyor. Sonuç olarak, Yaş değişkeninin, annenin düşük doğum ağırlığına sahip olup olmaması üzerinde %95 güvenle anlamlı bir etkisi yoktur.


Sigara değişkeni için yaptığımız anlamlılık testinde, katsayının anlamlı olduğuna karar verdik. %95 güvenle, bir annenin düşük doğum ağırlığına sahip olup olmaması üzerinde, sigara içip içmemesi durumu anlamlıdır. Yani annenin hamilelik sırasında sigara içip içmemesi, bebeğin doğum ağırlığını etkileyebilir.
Güven Aralıkları
![]() parametreleri için güven aralıkları aşağıdaki formülle hesaplanır.
parametreleri için güven aralıkları aşağıdaki formülle hesaplanır.
![]()
R’da güven aralıklarını tek tek hesaplamak yerine, confint() fonksiyonu modeldeki tüm değişkenlerin güven aralıklarını hesaplayabiliriz.

Bu bölümde de yaş değişkeninin bu model için anlamlı olmadığını güven aralığına bakar da anlayabildik. Eğer bir bağımsız değişken için oluşturulan güven aralığı 0 değerini içeriyorsa, model için anlamlı değildir.
“Gerçekler, ne yaparsanız yapın, gizlenemezdi. Araştırıp kovuşturarak ortaya çıkarılabilir, işkence yapılarak sizden sökülüp alınabilirdi. Ama amacınız hayatta kalmak değil de insan kalmaksa, sonuç ne fark ederdi ki?”(Orwel, 1984)
Bir Soru :
35 yaşında, sigara içen annelerde düşük doğum ağırlıklı bebek dünyaya getirenlerin oranını, %95’lik güven ile tahmin ediniz.
- G İstatistiği Değeri Hesaplanır

- G İstatistiği’nin Güven Aralığı Hesaplanır
![]()
- Z tablo değeri hesaplanır
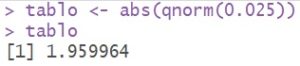
- G İstatistiği için hata değeri hesaplanır
Bir önceki yazıda kullandığımız G istatistiğine ait varyans formülü sadece bir bağımsız değişken ile kurulan modeller için kullanılıyordu. Formül;
![]()
Burada kullanacağımız veri setinde annenin yaşı ve sigara içip içmemesi durumu olarak iki bağımsız değişken olduğundan formül biraz daha karmaşık hale gelecek.
![]()
Elde edilen model için k adet bağımsız değişkene ait kapalı formül yukarıdaki gibidir. Bizim 2 bağımsız değişkenimiz olduğu için k=2’ye göre formülü açıyoruz;

vcov() fonksiyonu ile elde ettiğimiz varyans kovaryans matrisinden değerleri dikkatli bir şekilde seçiyoruz.(![]() değeri her zaman 1 değerini alır.)
değeri her zaman 1 değerini alır.)

Şekilde modeldeki değişkenlere ait varyans kovaryans matrisini görüyoruz. Burada sadece 2 bağımsız değişken varken matris 3×3 oluyor ve varyans hesaplama işlemi uzun sürmüyor. Ancak 10 tane bağımsız değişken içeren modellerde biraz karışıklık olabiliyor o yüzden değerleri doğru tespit etmeli ve çarpanları doğru bir şekilde belirlemeliyiz.

- Elde edilen sonuçlar ile G istatistiğine ait güven aralığı hesaplanır

- Elde edilen alt ve üst limit değerleri ile P istatistiğinin güven aralığı hesaplanır.

35 yaşında ve sigara içen annelerde, düşük doğum ağırlığında bebek dünyaya getirenlerin oranı %95 güvenle 0.5216744 ile 0.8690208 değerleri arasındadır.
Aynı modeli kullanarak 25 yaşında sigara içmeyen anneler için tahmin yapıldığında, oran değeri 0.6626278 ile 0.8277285 değerleri arasında çıkıyor. Oran değeri biraz düştü ama bu konuda doğru sonuçlara ulaşabilmek ve bir çözüm bulabilmek için elimizde başka kanıtların da olması gerekiyor. Dolayısıyla her ne kadar anlamlı bir model elde etsek de, bu bağımlı değişken üzerinde daha başka değişkenlerin de etkisinin olduğunu gösteriyor. Gerçekleşen düşük doğum ağırlığı problemini çözmek için çalışmayı daha da genişletmek, yeni değişkenler belirleyerek bu konular hakkında veri toplamak ve etkili bir model kurmak gerekiyor.
Not : Uygulamada yazılan tüm fonksiyonlar ve çıktılar görsel olarak verilmiştir. Aşağıda, uygulamada kullanılan fonksiyonlara ulaşabilirsiniz. Ek olarak aynı veri seti üzerinde farklı işlemler yapmak isteyen arkadaşlar bana mail yoluyla ulaşabilirler.
veri<-read.table("lowbwt.dat",header = F)
DDA <- veri$V2
yas <- veri$V3
sigara <- veri$V6
model <- glm(DDA~yas+sigara,family = binomial,data = veri)
summary(model)
g<-model$null.deviance-model$deviance
g
k <- model$df.null-model$df.residual
k
tablo <- qchisq(0.95,k)
0.98954
tablo
if(g>tablo){
"H0 reddedilir, %95 güvenle model anlamlıdır"
}
wald_yas <- (0.04978-0) / 0.03197
wald_yas
tablo <- abs(qnorm(0.025))
tablo
ifelse(wald_yas>tablo,yes = "H0 reddedilir, %95 güvenle katsayı anlamlıdır",
no = "H0 reddedilir, %95 güvenle katsayı anlamlı değildir")
wald_sigara <- (0.69185-0) / (0.32181)
wald_sigara
tablo <- abs(qnorm(0.025))
tablo
ifelse(wald_sigara>tablo,yes = "H0 reddedilir, %95 güvenle katsayı anlamlıdır",
no = "H0 reddedilir, %95 güvenle katsayı anlamlı değildir")
confint(model)
vcov(model)
vgx <- (1*0.57353313)+
((35^2)*(1.022205e-03))+
(1*1.035591e-01)+
2*((1*35*(-2.320662e-02))+
(1*1*(-4.732921e-02))+
(35*1*2.837881e-05))
Shi ny
ny
 ny
nyGeçen yazımda, Shiny uygulamasında bilgisayarda bulunan .csv uzantılı bir dosyayı ekrana yansıtma işlemleri hakkında bir uygulama yapmıştık. Şimdi ekrana yansıttığımız veri üzerinde Basit Lojistik Regresyon işlemleri yapacağız. Uygulamaya her yeni bir özellik eklendiğinde server ve ui dosyalarındaki tüm fonksiyonları paylaşacağım, böylece kullanılan fonksiyonları kullanabilir ve sorunsuz bir şekilde çalıştırabilirsiniz.
Uygulamada kullanacağımız veri setinde, kişinin kalp hastası olup olmaması üzerinde yaş değişkeninin etkisini araştırmıştık. Uygulamayı çalıştırdığımızda ilk olarak aşağıdaki görüntü bizi karşılayacak. Bu bölümde bilgisayarda bulunan .csv uzantılı dosyayı ekleyerek, yapmak istediğimiz istatistiksel analizi yukarıda bulunan sekmelerden seçiyoruz ve analize başlıyoruz. Şuan sadece İkili Lojistik Regresyon yapabiliriz ancak zamanla birçok istatistiksel analiz yapabilen bir Shiny uygulaması geliştirmeyi düşünüyorum.

İlk sekmede kullanmak istediğimiz veriyi seçiyoruz, uygun bir gösterim şekli belirliyoruz ve Basit Lojistik Regresyon sekmesine tıklıyoruz.

Sol taraftaki panelde bağımlı ve bağımsız değişkenleri seçtikten sonra otomatik olarak ekrana, modele ait bir özet bilgi yansıtıyoruz. Bundan sonraki yazımda birden çok bağımsız değişken içeren model kurma işlemleri, kategorik olan bağımsız değişkenlerde faktör ekleme işlemleri, değişken ekleme ve çıkarma işlemleri yapabilen bir Shiny uygulaması geliştireceğiz.
Not: Aşağıda, uygulamada kullandığım fonksiyonlar buluyor. Tüm fonksiyonları kopyalayıp, açtığınız Shiny uygulamasına yapıştırarak uygulamayı çalıştırabilirsiniz. Shiny üzerinde herhangi bir geliştirme yaparsanız benimle paylaşabilirsiniz, bir sonraki yazımda sizden gelenleri de uygulamaya ekleyebilirim.
library(shiny)
ui<- fluidPage(
# titlePanel() fonksiyonu ile uygulamaya verdiGimiz ana basligi belirtiyoruz
titlePanel("Kategorik Veri Analizi"),
# mainPanel() fonksiyonu ile bir ana panel aciyoruz ve icerisinde kullanmak istedigimiz ozellikleri ekliyoruz
mainPanel(
# tabsetPanel() fonksiyonu ile sekmeli bir panel olusturuyor
tabsetPanel(
# tabPanel() fonksiyonu ile ilk sekmeyi aciyoruz ve bu sekmede veri okuma ve ekrana yansitma islemleri yapiyoruz
tabPanel("Veri Okuma Islemi",
# siderbarPanel() ile veri girdisi icin bir tarayici, checkbox ve radioButton bulunan bir bolum olusturuyoruz
sidebarPanel(
# bir satirlik bosluk birakiyoruz
br(),
# fileInput() fonksiyonu ile veriyi okuma islemi yapiyoruz
fileInput("file", "Choose CSV File",
multiple = FALSE),
checkboxInput("header", "Header", TRUE),
br(),
radioButtons("sep", "Separator",
choices = c(
Semicolon = "\t",
Tab = ";"),
selected = ";"),
br(),
radioButtons("disp", "Display",
choices = c(Head = "head",
All = "all"),
selected = "head")
)
),
# tabPanel() fonksiyonu ile ikinci sekmeyi ekliyoruz
tabPanel("Basit Lojistik Regresyon",
# sidebarLayout() fonksiyonu ile bir duzen olusturuyoruz
sidebarLayout(
# sidebarPanel() fonksiyonu ile bir panel olusturuyoruz
sidebarPanel(
# uiOutput() fonksiyonu ile server dosyasinda bir degiskene kaydedilen ciktiyi ekrana yansitiyoruz
uiOutput("Select_Dependent_Variable"),
uiOutput("Select_Independent_Variables")),
# mainPanel() fonksiyonu ile bir panel olusturuyoruz
mainPanel(
# verbatimTextOutput() fonksiyonu ile bir degiskene kaydedilen ciktiyi ekrana yansitiyoruz
verbatimTextOutput("model")
))
)
),
# tableOutput() fonksiyonu ile .csv uzantili verinin goruntusunu ekrana yansitiyoruz
tableOutput("contents")
))
server <- function(input, output) {
# renderTable() fonksiyonu ile veriyi okuyup bir cikti degiskenine aktarma islemi yapiyoruz
output$contents <- renderTable({
# req() fonksiyonu ile once girdi degerlerinin olup olmadigi kontrol edilir, eger bir yanlislik varsa islem durdurulur
req(input$file)
# tryCatch() fonksiyonu ile belirli kosullar belirterek olagandisi durumlarin yontemi ile ilgili islemler yapilir
# Ornegin asagida ayristirma ile ilgili ve verinin gosterimi ile ilgili bir problem oldugu durumlarda
# hangi islemleri yapmasi gerektigini belirtiyoruz.
tryCatch(
{
df <- read.csv(input$file$datapath,
header = input$header,
sep = input$sep,
quote = input$quote)
error = function(e) {
stop(safeError(e))
}
if(input$disp == "head") {
return(head(df))
}
else {
return(df)
}
})
})
# reactive() fonksiyonu ile widget inputlarindaki her degisimi otomatik olarak guncellenir
data <- reactive({
file1 <- input$file
if(is.null(file1)){return()}
read.table(file=file1$datapath,header = T,sep = ";")
})
output$table <- renderTable({
if(is.null(data())){return ()}
data()
})
# renderUI() fonksiyonu ile girdi olarak kaydedilen islem arayuz ciktisi olarak bir degiskene kaydedilir
output$Select_Dependent_Variable <- renderUI({
# selectInput() fonksiyonu ile degiskenler listesinden secilen bagimli degisken girdi olarak kaydedilir.
selectInput("dep_var_select","Select Dependent Variable",choices = as.list(names(data())))
})
output$Select_Independent_Variables <- renderUI({
checkboxGroupInput("ind_var_select","Select Independent Variable(s)",choices = as.list(names(data())))
})
output$model <- renderPrint({
input$dep_var_select
input$ind_var_select
veri <- data()
# Lojistik Regresyon Modeli kurarken "caret" kutuphanesinden yararlaniyoruz
library(caret)
# kullanilan degiskenleri belirli bir format haline getiriyoruz ve bu duzen otomatik olarak her degisiklikte korunuyor
format <- sprintf("%s~%s",input$dep_var_select,paste0(input$ind_var_select,collapse="+"))
print(format)
# glm() fonksiyonu ile modelimizi kuruyoruz ve bir degiskene kaydediyoruz
model <- glm(as.formula(format),family=binomial(),data=veri)
print(summary(model))
})
}
shinyApp(ui, server)Sonuç olarak, model anlamlılığı, katsayıların anlamlılıkları, güven aralıkları konularını tamamladık. Bu yazıdan sonra bu konular hakkında teorik bilgilerin dışında, yaptığımız analizlerin yorumlanması üzerinde duracağım. Bir sonraki yazımda değişken ekleme çıkarma işlemleri konusunda bilgiler verdikten sonra bu özellikleri Shiny üzerinden pratik bir şekilde nasıl yapabileceğimiz hakkında bilgiler vereceğim.
Not: Bundan sonraki yazımda alıntılar yapacağım kitabın adı “Aldous Huxley – Cesur Yeni Dünya” olacaktır. Okumak isteyenlere şiddetle tavsiye ederim 🙂
“Şu anda somut bir başkaldırı, hatta bir başkaldırı hazırlığı bile olanaksızdır. Proleterlerin korkulacak bir yanı yoktur. Kaderlerine terk edilmiş Proleterler, yalnızca başkaldırı dürtüsünden yoksun olarak değil, aynı zamanda dünyanın daha farklı olabileceğini kavrama gücünden de yoksun bir biçimde kuşaklar ve yüzyıllar boyunca çalışacak, üreyecek ve öleceklerdir.”(Orwel, 1984)
Değerli zamanınızı ayırdığınız için teşekkürler.
Merhabalar ,
Yüksek lisans öğrencisiyim ve örnek uygulamalar için veri setini alabilmem mümkün mü acaba ?
Mail olarak gönderdim,kolay gelsin.
Sayın Mustafa Hocam
Uygulamalı istatistik dersinde lojistik regresyon uygulamasında kullanacağım veri setine ulaşamıyorum bana gönderebilir misiniz ? teşekkürler.
Merhabalar, mail adresinize gönderdim iyi çalışmalar.
Merhabalar İstatistik öğrencisiyim iki düzeyli kategorik değişken veri seti ile lojistik regresyon yapmam gerekiyor çok acil bir ödevim. Ellinizde örnek veri seti var mı acaba?
Selamlar, mail adresinize ilettim. İyi çalışmalar