

 Fahreneight 451, bir kitabı yakmak için gereken sıcaklık değeridir. İnsanlığın bilincini oluşturan, gerçeklik hakkında bilgiler veren, devletler kurup yıktıran bu inanılmaz güçten bahsediyorum. İtfaiyeciler, insanları bilinçsizleştirmek için onların kitap okumalarını engelleyerek onları tekdüze hale getirmeye çalışan bir sistemin işçileri. Görev aşkı ile yanıp tutuşan bu canavarlar, gelen ihbarlara anında kulak veriyor ve hedefi yok ediyorlar. Eskiden görevleri yangın söndürmek olan bu kişiler, artık devletlerin birer kundakçıları oluyor.
Fahreneight 451, bir kitabı yakmak için gereken sıcaklık değeridir. İnsanlığın bilincini oluşturan, gerçeklik hakkında bilgiler veren, devletler kurup yıktıran bu inanılmaz güçten bahsediyorum. İtfaiyeciler, insanları bilinçsizleştirmek için onların kitap okumalarını engelleyerek onları tekdüze hale getirmeye çalışan bir sistemin işçileri. Görev aşkı ile yanıp tutuşan bu canavarlar, gelen ihbarlara anında kulak veriyor ve hedefi yok ediyorlar. Eskiden görevleri yangın söndürmek olan bu kişiler, artık devletlerin birer kundakçıları oluyor.
Bir kitabın yakılması ile o kitabın Tavsiye Algoritmaları ile hesaplanan değerler arasında son sıralarda yer alması arasındaki ilişkiyi düşünelim. Günümüzde tavsiye sistemlerini en çok kullanan şirketlerinden biri olan Netflix, kullanıcılarının “Kaliteli Zaman” geçirmelerini sağlamak için çok büyük yatırımlar yapıyor. Bu içerikleri keyifle izleyen bireyler o konular hakkında belirli bir bakış açısı kazanıyor. Dolayısıyla düzenli olarak Netflix’in tavsiye ettiği içerikleri izleyen bireyler o konulara karşı ortak bir görüşe sahip oluyor. Yani bu insanların dünya görüşü bu konular hakkında tekdüze hale geliyor. Dolayısıyla tehlikeli kitapları yakmak veya teknoloji ile iç içe yaşayan toplumların, bu algoritmalar yardımıyla algılarını yönetmek aslında aynı şey.

Günde ortalama 2 saatimizi Netflix de geçirdik, şimdi geri kalan 22 saatimizi nasıl “Kaliteli” bir şekilde geçireceğimizi düşünüyor ve yine belirli algoritmaların bize tavsiye ettiği bir kitabı okumaya başlıyoruz. 2 saat kitap okuduk, şimdi yine belirli algoritmaların tavsiye ettiği kıyafet kombinlerini giyip dışarı çıkma vakti! Bir yerde oturduk, içtiğimiz kahvenin resmini paylaştıktan sonra arkadaşlarımızın ne kadar “Mutlu” olduğunu izleme vakti. “Ben bunları tüketebiliyorum” bombardumanlarından kurtulduktan sonra eve dönüyoruz ve ne kadar heyecansız bir hayatımız olduğunu düşünüyoruz. Bir anda bir Fastfood zinciri kendinizi mutlu hissetmeniz için size bir menü öneriyor. O anda yapabileceğiniz tek şey, mutlu olmak için o yemeği söylemek ve yanında bir de tatlı sipariş etmek. Çünkü bu yemeği yiyenler yanında da o tatlıyı söylüyorlar…
Bu böyle yıllarca gidiyor ve yıllarca bu algoritmaların tavsiyeleri hayatlarımızın içine daha çok giriyor ve zamanla birbirimize daha çok benzetiliyoruz. Devletlerin yönetim yapısı, insan hakları, insan ilişkileri gibi birçok temel konuya olan bakış açılarımız yukarıdan, aşağıdan, sağdan, soldan törpüleniyor ve daha tahmin edilebilir, sindirilebilir toplumlar haline geliyoruz.
”Kitaplar, tören alayı büyük bir gürültü içinde caddede ilerlerken, Sezar’ın kulağına ‘Unutma, Sezar, sen de ölümlüsün’ diyen pretoryen muhafızlarıdır.”(Bradbury, Fahrenheit 451)
Lojistik Regresyon Uygulaması
Çalışmanın Amacı
İlaç bağımlılığını etkilediği düşünülen bazı bağımsız değişkenlerle lojistik regresyon modeli kurarak, bu değişkenlerin tedavi sonunda hastanın kanında ilaç kalıp kalmadığının üzerindeki etkisi araştırılmaktadır.
Değişkenler
- Kayıt Yaşı (AGE) – Sürekli
- Depresyon Testi Puanı (BECK) – Sürekli
- Uyuşturucu Madde Kullanımı (IVHX) – Kategorik(1:Hiç Kullanılmamış, 2:Eskiden Kullanmış, 3:Kullanıyor)
- İlaç Tedavisi Sayısı (NDRUGTX) – Sürekli
- Hastanın Irkı (RACE) – Kategorik(0:Beyaz, 1:Diğerleri)
- Tedavi Grubu (TREAT) – Kategorik(0:Kısa Süreli Tedavi, 1:Uzun Süreli Tedavi)
- Tedavi Bölgesi (SITE) – Kategorik(0:A, 1:B)
- Tedavi Sonrası Hastanın Durumu (DFREE) – (1:İlaç Var, 0:İlaç Yok)
Modelin Kurulması
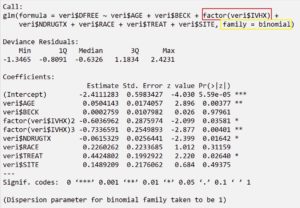
Burada dikkat edilmesi gerekenler;
- Bağımsız değişken olan IVHX değişkeni kategorik ve 2’den fazla düzeye sahip olduğu için bu değişken faktör değişkeni olarak tanımlanmalıdır. Bu şekilde değişkenin diğer düzeyleri de modele dahil edilmiş olur.
- family(binomial) olarak tanımladığımız parametre ile Lojistik Regresyon Modeli kurma işlemi yapıyoruz. Bu parametreyi değiştirerek istediğiniz istatistiksel modeli seçebilirsiniz.
Modelin Anlamlılığının Test Edilmesi
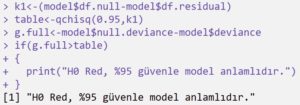
Bu bölümde k1 serbestlik dereceli Chi-Square dağılımı ile deviance değerlerinden hesapladığımız G test istatistiğini karşılaştırarak modelin anlamlı olup olmadığı kontrol edilir.
Yaş Değişkenin Anlamlılığının Test Edilmesi
Modelin anlamlı olup olmadığına karar verdikten sonra, modele katkısı olup olmayan değişkenleri belirlememiz gerekiyor. Değişkenlerin, Estimate ve SE değerleri ile hesaplanan Wald test istatistiği ile Z test istatistiği karşılaştırılır. Bu bölümde sadece Yaş değişkeninin anlamlılığını test ediyoruz, isterseniz diğer değişkenleri de bu yöntemle test edebilirsiniz.

Bu işlemi, modeldeki tüm bağımsız değişkenler için uyguladıktan sonra modele anlamlı katkısı olan değişkenler ile tekrar model kurulur.
Yeni Modelin Kurulması
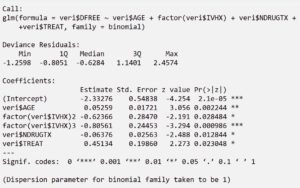
Yeni model kurulduktan sonra bu modelin de anlamlı olduğu test edilir ve bu model de anlamlı çıkarsa hangi modelin daha açıklayıcı olduğunu test etmek için bu iki modelin özet bilgilerinden elde ettiğimiz istatistikleri kullanarak uygun model tercih edilir.
Yeni Modelin Anlamlılığının Test Edilmesi
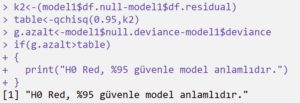
Kurduğumuz iki modelin de anlamlı olduğunu kanıtladık. Bu modellerden hangisinin anlamlı olduğunu test etmek için, modelden çıkarılan değişkenlerin anlamlı olup olmadığını test ediyoruz.
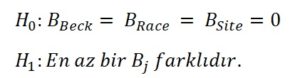

İki modelin de Deviance değerlerini birbirlerinden çıkardıktan sonra bir G istatistiği elde ediyoruz. Anlamsız olduğu düşünülen ve modelden çıkarılan 3 serbestlik derecesine karşılık gelen bir Chi-Square değeri buluyoruz ve bu değeri G istatistik değeri ile karşılaştırıyoruz.
Değişkenlerin Yorumlanması
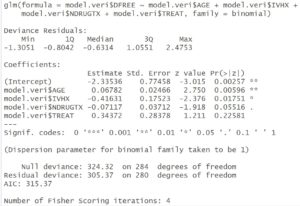
Azaltılmış modeli tercih ettikten sonra, bu modelin summary() fonksiyonu ile özet istatistiklerini çıkardıktan sonra “TREAT” değişkenini yorumlayalım.

THREAT değişkeninin ![]() değeri 0.45134 olarak bulunmuştur. Bu değeri üzeri olarak hesapladığımızda çıkan sonuç ile ODDs oranını yorumlayabiliyoruz.
değeri 0.45134 olarak bulunmuştur. Bu değeri üzeri olarak hesapladığımızda çıkan sonuç ile ODDs oranını yorumlayabiliyoruz.
Yeni Gelen Bir Hastanın Verileri ile Tahminleme Yapılması
Yaşı 33, önceden uyuşturucu kullanmış, 3 kere ilaçla tedavi olmuş ve uzun süreli tedavi grubundaki hastaların oranını tahmin ediniz.
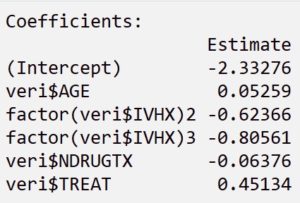
Şeklinde 2. modele eklediğimiz değişkenlerin katsayılarını kullanarak bir model oluşturuyoruz. Oluşturduğumuz modele, yeni gelen bir hastanın verilerini ekleyerek bir G istatistiği elde ediyoruz. G istatistiğini kullanarak da aşağıdaki matematiksel işlem ile P değeri hesaplıyoruz ve sonucu P değeri üzerinden yorumluyoruz.
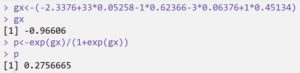
Yaşı 33, önceden uyuşturucu kullanmış, 3 kere ilaçla tedavi olmuş ve uzun süreli tedavi grubundaki hastaların kanlarının ilaçtan arınmış olması oranı 0.275665’dir.
“Sana gereken kitaplar değil, bir zamanlar kitapların içinde olan bazı şeyler(…). Onu nerede bulursan al, eski plaklarda, eski filmlerde ve eski dostlarda; onu doğada ara ve onu kendi içinde ara. Kitaplar bir tür depo gibidir ve biz onlarda unutacağımızdan korktuğumuz şeyleri saklarız. İçlerinde büyülü bir şey yoktur. Büyü sadece o kitapların anlattıklarındadır.”(Bradbury, Fahrenheit 451)
Sensitivity ve Specificity Değerleri
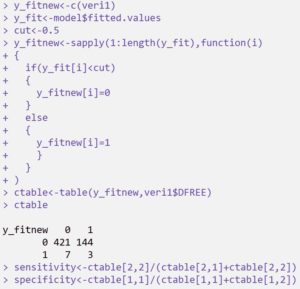
fitted.values değerleri tahmin edilen değerler olarak da bilinir. Bu değerler, cut-off değeri olarak belirlenen 0.5 değeri ile karşılaştırılır, büyük olanlara 1, küçük olanlara 0 değerleri atanır. Sonra atanan tüm değerler ile eldeki verinin bağımlı değişkeninin aldığı değerler karşılaştırılır ve bir tablo oluşturulur. Bu tablo ile modelin tahmin performansı hakkında bütün bilgiler yer alır. Duyarlılık ve seçicilik kavramları için bir önceki yazımı inceleyebilirsiniz.
Duyarlılık; tedavi sonrasında hastanın kanında ilaca rastlandığında model tahminine göre de hastanın kanında ilaca rastlanma olasılığı 0.30’dur.
Duyarlılık; tedavi sonrasında hastanın kanında ilaca rastlandığında model tahminine göre de hastanın kanında ilaca rastlanma olasılığı 0.745’dir.
ROC Eğrisi
Bir modelin tahmin performansını ölçmek için sınıflama tablosundan yararlanılır. Bu tablodan elde edilen duyarlılık ve seçicilik değerleri ile modelin performansı hakkında bilgiler edilir. Ek olarak, bu değerler kullanılarak ROC eğrisi de çizdirilir. Modelin tahmin yeteneği bu eğrinin altında kalan alan ile ölçülür. Alan ne kadar büyük ise modelin tahmin performansı o kadar iyidir.
ROC eğrisinin kullanımının bir diğer özelliği sadece bir cut-off değeri değil tüm cut-off değerleri ile çizdirilmesidir. Bazı kaynaklarda cut-off değeri 0.5 iken, bazı kaynaklarda 1’lerin oranı kadar alınmalıdır.
Sonuç olarak, ROC eğrisi farklı cut-off’lar için, duyarlılık ve 1-seçicilik ile çizdirilir.
- ROC < 0.5 ise “Modelin ayrım yeteneği yoktur”
- 0.7 < ROC < 0.8 ise “Kabul edilebilir ayrım yeteneği vardır”
- 0.8 < ROC < 0.9 ise “Mükemmel ayrım yeteneği vardır”
- ROC >0.9 ise “Muhteşşşem ayrım yeteneği vardır

“ROSE” paketini kütüphaneye yükledikten sonra bağımlı değişkende kaç tane 1 kaç tane 0 olduğunu görmek için table() fonksiyonu ile tablo halde görebiliyoruz.
Deneme ve Tahmin Verilerinin Ayrılması

Veri setinde 1 veya 0’lardan hangisi az ise onun yarısını deneme veri seti için diğer yarısını tahmin veri seti için ayırıyoruz.
X olarak hesaplanan değer ham verideki 0’ların 1’lere oranıdır. Deneme ve tahmin veri setinde de aynı oranı korumak için 73 adet başarı sayısının X katı kadar başarısızlık sayısı eklenir. Bu işlem iki veri seti için de aynı şekilde uygulanır.
Deneme Verisini Kullanarak Modeli Eğitme İşlemi

model.veri olarak kaydettiğimiz veri setindeki değişkenleri kullanarak bir Lojistik Regresyon Modeli kurduk. Bir sonraki işlemde, başka bir veri setindeki bağımsız değişkenleri yerlerine koyarak bağımlı değişken olan DFREE değişkenini tahmin edeceğiz.
Tahminleme İşlemi ve ROC Eğrisi

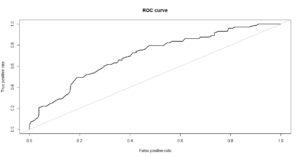
predict() fonksiyonunu kullanarak model3 olarak kaydettiğimiz model ile tahmin.veri setindeki değişkenleri kullanarak tahmin değerlerimizi oluşturduk. Oluşturulan bu değerler ile yukarıdaki gibi 0.5 cut-off değerini de kullanabilirdik fakat bir farklı cut-off değerleri ile modelin tahmin performansını görmek istiyorsak ROC eğrisi çizdirmemiz gerekiyor.
“ROSE” kütüphanesi ile gelen roc.curve() fonksiyonu ile ROC eğrimizi çizdiriyoruz. Yukarıda hesaplanan AUC değeri 0.702, yani modelimiz kabul edilebilir bir ayrım yeteneği var yorumunu yapıyoruz
Buraya kadar yaptığımız tüm işlemler ve daha fazlası için “Makine Öğrenmesi Algoritmaları: Lojistik Regresyon” videosunu izleyebilirsiniz.
https://www.youtube.com/watch?v=CgsiEyVi1gI&list=PLkbyF4y0lKkDAJUFHyjoChY7C26aqAxKQ&index=2&t=0s
 Kullanılan fonksiyonlar için Github linki
Kullanılan fonksiyonlar için Github linki
“Bir evi çivisiz ve ahşapsız inşa edemezsin. Eğer bir evin yapılmasını istemiyorsan, ahşap ve çivileri sakla. Eğer politik bakımdan mutsuz bir adam istemiyorsan, kaygılandıracak bir soruda ona iki bakış açısı verme, birini ver. Daha iyisi hiç verme.”(Bradbury, Fahrenheit 451)
Shi ny
ny
Shiny Eğitim Serisinin 7. videosu ile karşınızdayım. Bu sefer kanlı canlı karşınızdayım 🙂 Bundan sonraki videolar bu şekilde olacağından biraz daha eğlenceli geçeceğini düşünüyorum. Serimizin bu bölümünde genel olarak Shiny’de veriyi okutma ve basit istatistiksel analizler yaptık. Ek olarak, tabsetpanel() fonksiyonu ile Shiny’de sekmeli bölümler oluşturarak uygulamaları daha açık ve anlaşılabilir şekillerde tasarlayabileceğimizi gördük. Hız kesmeden devam ediyoruz 🙂
https://www.youtube.com/watch?v=y9HBgEM3KwI&t=247s
Kaynaklar
https://tezverianaliz.com/biyoistatistik-dershanesi/ozgulluk-ve-duyarlilik-specificity-and-sensitivity-1/
https://shiny.rstudio.com/gallery/widget-gallery.html
https://shiny.rstudio.com/tutorial/written-tutorial/
https://www.dicle.edu.tr/Contents/3b4d94e3-3582-4384-939b-c5957b348bdd.pdf