

Kümeleme serimizin son iki yazısında kümeleme konusuna giriş yaptık ve K-Ortalamalar algoritmasının temel çalışma mantığından bahsettik. Bu yazımızda küme sayısının nasıl seçileceğinden bahsedeceğiz.
Öncelikle bir çok konuda olduğu gibi ideal küme sayısını neye göre seçeceğimizi belirleyecek bir metrik olmalıdır. Kümelemedeki temel mantığı hatırlayalım: Birbirine benzeyenler, yakın olanlar aynı kümede olsun birbirine benzemeyenlerle mümkün olduğunca uzak olsunlar (yabancı düşmanlığı :)). Bunu sağlayacak bir metrik var: Within Clusters Sum of Square (WCSS) Türkçesi şöyle: Kümeler içi kareler toplamı.

$ WCSS =\sum _{ { P }_{ i }Kume_1 }^{ }{ mesafe({ P }_{ i },C_{ 1 })^{ 2 }+ } \sum _{ { P }_{ i }Kume_2 }^{ }{ mesafe({ P }_{ i },C_{ 2 })^{ 2 }+… } $
Yukarıdaki resmin yardımıyla metriğimiz olan (WCSS) kümelerin kareler toplamına değinelim. Küme sayısını belirledik. Algoritmayı çalıştırdık. Algoritma her bir noktayı bir kümeye yerleştirdi. Her bir noktanın küme merkezine olan uzaklığının karesinin toplamını alıyoruz. Bunu her küme için yapıyoruz. Toplamda çıkan rakam ne kadar düşük ise kümeleme o kadar iyi çalışmış merkez noktalar ile kümeye dahil noktalar birbirine yakın durmuş demektir.
Bilmem aklınıza hiç geldi mi? Aslında her nokta bir kümedir ve aynı zamanda küme merkezidir. Her nokta aynı zamanda bir küme ve küme merkezi olursa mesafeler hep sıfır olacaktır. O halde her noktanın küme olduğu modelde WCSS sıfır olacaktır. Peki o halde bu model mi en iyi diyeceğiz? Tabi ki hayır. Eğer böyle dersek kümeleme yapmamızın anlamı kalmaz. Kümelemedeki temel amaç birbirine benzeyen nesneleri sınırlı bir sayıda kümede toplayabilmekti.
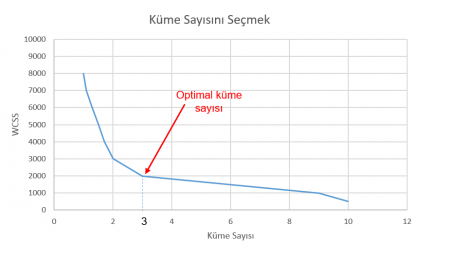
Yukarıda küme sayısı ve WCSS arasındaki ilişkiye dair grafiği görüyoruz. İyi modelin WCSS’i daha düşük olur demiştik. Yukarıda küme sayısı 3’e kadar WCSS çok hızlı bir şekilde düşüyor. 3’ten sonra yatay seyretmeye başlıyor. Burada anlıyoruz ki 3 bu veri seti için optimal küme sayısıdır. Çünkü daha fazla küme WCSS’i azaltmadığı gibi modelin yorumlanabilirliğini (interpretibility) azaltıyor. Yönteme dirsek yöntemi (elbow method) deniyor.
Yöntem elbette oldukça keskin bir şekilde bize küme sayısını vermez. Bu konuda biraz da alan bilgisi ve veri bilimcinin yorumları devreye girer. Zaten algoritma parametre olarak araştırmacıdan bir küme sayısı istiyor. Bu sebeple bu yöntem küme sayısına karar vermede yardımcı olabilecek iyi bir yöntem olarak kabul edilebilir. Veri bilimcinin de bu kadarlık da olsa çorbada tuzu bulunsun değil mi? 🙂 Arkadaş her şeyi makineler yapacak da veri bilimci ne iş yapacak? Artık bir küme sayısını da seçiversin…