

![]()
Apache Spark ile zamanla edindiğim ipuçları ve pratik bilgileri diğer pratik bilgiler ve komutlar yazı dizilerinde olduğu gibi sizlerle paylaşacağım. Faydalı olmasını umuyorum.
- Spark RDD[String] nasıl dataframe yapılır? Rdd’yi Dataframe’e Dönüştürmek
- Spark Dataframe Vektör tipini Array tipine çevirmek
- Pyspark ile Excel’e yazmak
- Spark ile otomatik olarak sütun seçmek (Scala)
- spark-shell’i başlatırken konfigürasyonları nasıl ayarlarım?
- PySpark ile her bir sütunu null kontrolü nasıl yaparım? Spark Dataframe içinde hangi sütunda boşluk var nasıl öğrenirim?
- PySpark Dataframe iki sütun arasındaki Euclidean mesafeyi hesaplamak
- Spark dataframe seçilecek sütunları filtrelemek, sütunların bir alt kümesini seçmek
- Spark lookup table: Başka bir dataset’e bakarak olmayanları tutmak
- Spark dataframe’i diske yazmak
- SparkSession örneği (SparkSession example)
- Spark’ın en sevdiği dosya formatı nedir?
- Spark sütun isimlerinde boşluk varsa selectExpr içinde hata almadan nasıl kullanırız? – column name contains space
- PySpark ile nümerik bir sütuna ait histogramı nasıl çizeriz? pyspark histogram
- PySpark eğitilmiş ML modellerini nasıl kaydeder, üzerine yazarız? PySpark ML Model overwrite
- PySpark birden fazla örüntüye uyan metni değiştirmek – pyspark multiple regexp_replace
- Spark uygulamasına birden fazla jar dosyasını nasıl ekleriz? Sparksession multiple jar
- PySpark log seviyesini değiştirme
- Structured Streaming console output row number and truncate example
- PySpark drop multiple columns
- PySpark dataframe python dictionary çevirmek – Convert pyspark dataFrame to Dictionary
1. Apache Spark RDD[String] nasıl dataframe yapılır? Rdd’yi Dataframe’e Dönüştürmek
Kütüphaneler ve RDD’nin mevcut hali:
import org.apache.spark.sql.{Row}
import org.apache.spark.sql.types.{StructField, StructType, DoubleType}
transformedRDD.take(5).mkString("\n")Çıktısı:
res29: String = 68.0,111.0,0.9972458756419185 52.0,109.0,0.9938358369887756 98.0,119.0,0.9809337257443007 17.0,65.0,0.9333647875381205 76.0,85.0,0.9941287079162111
Yukarıda gördüğümüz gibi her bir satırda tek bir string içinde 3 tane sütun (double türünde) var. Bunları split edip Row yapısına dönüştürelim:
val rowRDD = transformedRDD.map(row => {
val r = Row( row.split(",")(0).toDouble,
row.split(",")(1).toDouble,
row.split(",")(2).toDouble)
r
})Veriye uygun şema tanımlama:
val schema = new StructType()
.add(StructField("row", DoubleType, true))
.add(StructField("col", DoubleType, true))
.add(StructField("val", DoubleType, true))Şimdi rdd ile şemayı kullanarak spark dataframe oluşturma:
import spark.implicits._ val df = spark.createDataFrame(rowRDD, schema) df.show(5,false)
Çıktı:
+----+-----+------------------+ |row |col |val | +----+-----+------------------+ |68.0|111.0|0.9972458756419185| |52.0|109.0|0.9938358369887756| |98.0|119.0|0.9809337257443007| |17.0|65.0 |0.9333647875381205| |76.0|85.0 |0.9941287079162111| +----+-----+------------------+ only showing top 5 rows
Başka yöntemler de var. Biz yukarıda bir tanesi ile dataframe oluşturduk.
2. Apache Spark Dataframe Vektör tipini Array tipine çevirmek
Spark Dataframe ile basit veri türlerini cast gibi fonksiyonlarla dönüştürebilsek da bir vector türünü array türüne bu kadar kolay çeviremeyebiliriz. Bu örneğimizde vector türündeki bir sütunu array türüne çevireceğiz. Neden buna ihtiyaç duyarız? Makine öğrenmesinde VactorAssembler ile tüm nitelikleri bir araya toplarız. Ancak bunun kolay bir geri dönüşü yoktur. VectorAsssembler ile oluşturulup bir sütuna tepiştirilmiş vector tipindeki veri alıp işlemek için (özellikle RDD ile) önce onu vector tipinden dışarı çıkarmalıyız. En azından bana kolay gelen yöntemi bu.
İşlemek istediğim vector (SparseVector) aşağıdaki gibidir.
+--------+--------+-------------------+ |sutun_01|sutun_02| featureVector| +--------+--------+-------------------+ | Bir| İki|(7,[1,6],[1.0,1.0])| | Bir| Sıfır| (7,[1],[1.0])| | İki| Bir|(7,[0,4],[1.0,1.0])| | Beş| İki| (7,[6],[1.0])| | Dört| Bir|(7,[2,4],[1.0,1.0])| | İki| Üç|(7,[0,5],[1.0,1.0])| | İki| Üç|(7,[0,5],[1.0,1.0])| | Sıfır| Bir|(7,[3,4],[1.0,1.0])| +--------+--------+-------------------+
Yukarıdaki dataframe çıktısında sutun_01 ve sutun_02 orijinal nitelikleri, featureVector ise onların StringIndexer, OneHotEncoder ve VectorAssembler yardımıyla vektör haline gelmiş halidir. Şimdi bu featureVector sütununu array yapacağız. Ama önce mevcut şemayı bir görelim.
root |-- sutun_01: string (nullable = true) |-- sutun_02: string (nullable = true) |-- featureVector: vector (nullable = true)
Açıklamaları kod yorumu olarak yazdığım için burada kısa kesiyorum. Ben susayım kodlar konuşsun 🙂
// Herhangi bir vektör türünü Array[Double] türüne çeviren fonksiyon
val VecToArrFunc: Any => Array[Double] = _.asInstanceOf[SparseVector].toArray
// Fonksiyonu SparkSQL dünyasından erişebilmek için udf ile kaydedelim
val VecToArrFuncRegisteredUDF = F.udf(VecToArrFunc)
// fonksiyonu kullanarak vector sütununu seçip yeni bir sütunda array türünde elde edelim
val df2 = vecDF.withColumn("vecArr", VecToArrFuncRegisteredUDF($"featureVector"))
// Sonuç:
df2.show(false)
+--------+--------+-------------------+-----------------------------------+
|sutun_01|sutun_02|featureVector |vecArr |
+--------+--------+-------------------+-----------------------------------+
|Bir |İki |(7,[1,6],[1.0,1.0])|[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0]|
|Bir |Sıfır |(7,[1],[1.0]) |[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0]|
|İki |Bir |(7,[0,4],[1.0,1.0])|[1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0]|
|Beş |İki |(7,[6],[1.0]) |[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0]|
|Dört |Bir |(7,[2,4],[1.0,1.0])|[0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0]|
|İki |Üç |(7,[0,5],[1.0,1.0])|[1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0]|
|İki |Üç |(7,[0,5],[1.0,1.0])|[1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0]|
|Sıfır |Bir |(7,[3,4],[1.0,1.0])|[0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0]|
+--------+--------+-------------------+-----------------------------------+Yeni şema:
root |-- sutun_01: string (nullable = true) |-- sutun_02: string (nullable = true) |-- featureVector: vector (nullable = true) |-- vecArr: array (nullable = true) | |-- element: double (containsNull = false)
3. Pyspark ile Excel’e yazmak
Csv’ye yazmak sıradan iş, excel ise Spark’ın içinde hazır yok maalsef. Ancak pyspark kullanıyorsak pandas’ın avantajlarından faydalanabiliriz.
Pyspark’ta güzel bir özellik var. spark_df.toPandas() dediğiniz zaman spark dataframe pandas dataframe oluyor. Bundan sonrasında pandas_df.to_excel() ile devam edebilirsiniz.
Burada dikkat etmek gerek iki husus var. Birincisi; spark_df.limit(n).toPandas() ile driver’a dönecek satır sayısına mutlaka limit koymalısınız. İkincisi ise pip install openpyxl ile openpyxl paketini kurmalısınız.
4. Spark ile otomatik olarak sütun seçmek (Scala)
Spark ile nitelik mühendisliği çalışmalarında bazen onlarca ve yüzlerce sütun ile çalışmak gerekebilir. Bunların hepsini el ile seçmek, ayırmak ve gruplamak imkansızdır. Dolayısıyla seçilecek sütun isimlerini otomatiğe bağlamanın yöntemlerini bilmek belli bir sütun sayısından sonra zorunluluk haline gelmektedir. Aşağıda veriyi okuduğumuz bir dataframe sütunları içinden çıkarılacakları belirttikten sonra, kalanları topluca nasıl seçeceğimizin örneğini vereceğim.
val selectedCols = (dfOriginal.columns.toSet.diff(Array("istenmeyenSütunAdı_1","istenmeyenSütunAdı_2").toSet).toArray)
val df = dfOriginal.select(selectedCols.head, selectedCols.tail: _*)Yukarıdaki iki satır ile orijinal verideki “istenmeyenSütunAdı_1″,”istenmeyenSütunAdı_2” sutunları hariç kalanları otomatik seçmiş oluyoruz.
5. spark-shell’i başlatırken konfigürasyonları nasıl ayarlarım?
–conf key=value ile ayarlayabilirim. Örnek:
[user@cdh1 ~]$ spark-shell --conf spark.dynamicAllocation.enabled=true spark.shuffle.service.enabled=true
Aynı yöntem spark-submit için de geçerlidir.
Peki shell açıldıktan sonra konfigürasyon girebilir miyim? Evet
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)6. PySpark ile her bir sütunu null kontrolü nasıl yaparım? Spark Dataframe içinde hangi sütunda boşluk var nasıl öğrenirim?
from pyspark.sql import functions as F
for col in df.columns:
if df.filter(F.col(col).isNull()).count() > 0:
print("{} null mevcut".format(col))7. PySpark Dataframe iki sütun arasındaki Euclidean mesafeyi hesaplamak
Elimizde bir dataframe var ve iki tane vektör tipinde sütunu var. Bu iki sütunun arasındaki öklid mesafesini hesaplayarak yeni bir sütunda yazmak istiyoruz.
import pyspark.sql.functions as F
from pyspark.sql.types import FloatType
from scipy.spatial import distance
distance_udf = F.udf(lambda x, y: float(distance.euclidean(x, y)), FloatType())
df2 = df.withColumn('distances', distance_udf(F.col('features'), F.col("pca")))
Örnek çıktı:
+--------------------+--------------------+---------+
| features| pca|distances|
+--------------------+--------------------+---------+
|[1.0,0.0,0.275616...|[0.61642950650853...| 2.963177|
|[0.0,1.0001000100...|[0.02277172397525...|1.6929647|
|[1.0,2.0002000200...|[0.43060259539934...|2.5141695|
|[0.0,3.0003000300...|[0.73666921489550...|2.3154056|
|[0.0,4.0004000400...|[-0.0072074167979...| 3.038008|
+--------------------+--------------------+---------+8. Spark dataframe seçilecek sütunları filtrelemek, sütunların bir alt kümesini seçmek
Spark dataframe içinde onlarca sütun var ancak siz istemediklerinizin dışındakilerini seçmek istiyorsunuz. Yani sütunları filtrelemek istiyorsunuz. Buna biraz da kara liste mantığı diyebiliriz. İşaretlediklerim hariç hepsi seçilsin.
val df = spark.createDataFrame(Seq(
("Bir", "İki","Üç", "Sıfır","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır"),
("Bir", "İki","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır"),
("Bir", "İki","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır"),
("Bir", "İki","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır","Bir", "Sıfır")
)).toDF("col1", "col2","col3", "col4","col5", "col6","col7", "col8","col9", "col10")Dataframe’i görelim.
df.show +----+----+----+-----+----+-----+----+-----+----+-----+ |col1|col2|col3| col4|col5| col6|col7| col8|col9|col10| +----+----+----+-----+----+-----+----+-----+----+-----+ | Bir| İki| Üç|Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| | Bir| İki| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| | Bir| İki| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| | Bir| İki| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| +----+----+----+-----+----+-----+----+-----+----+-----+
Seçeceğimiz sütunları filtreleyelim. Bunun için df.columns’u kullanabiliriz. df.columns bize tüm sütunları içeren bir array döner. Bu array üzerinde filtreleme yaparak istediğimiz sütunları içeren yeni bir array elde edelim. Bunun içinde Set collection yapısını ve iki set arasındaki farkı alan diff metodunu kullanacağız. Aşağıdaki örnekte “col2″,”col5″,”col7” filtrelenecektir.
val colsToSelected = df.columns.toSet.diff(Array("col2","col5","col7").toSet).toArray
colsToSelected: Array[String] = Array(col8, col3, col6, col9, col10, col1, col4)Şimdi kalan sütunları seçelim. Bunun için select() içine aşağıdaki ilginç ifadeyi kullanıyoruz.
df.select(colsToSelected.head, colsToSelected.tail:_*).show +-----+----+-----+----+-----+----+-----+ | col8|col3| col6|col9|col10|col1| col4| +-----+----+-----+----+-----+----+-----+ |Sıfır| Üç|Sıfır| Bir|Sıfır| Bir|Sıfır| |Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| |Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| |Sıfır| Bir|Sıfır| Bir|Sıfır| Bir|Sıfır| +-----+----+-----+----+-----+----+-----+
9. Spark lookup table: Başka bir dataset’e bakarak olmayanları tutmak
Bazen veri akışında kayıtların tekrarlanmasını önlemek için veya eşleştirme yapmak için bir dataset’e bakarak o dataset içinde olmayanları tutmak isteriz. Örneğin streaming uygulamasında çeşitli sebeplerle bazı kayıtları elememiz lazım elenecek kayıtlarında başka bir tabloda olduğunu varsayalım. O halde ben bütün streaming kayıtlarını diske yazmadan önce o tabloda olup olmadığını kontrol edip yazmam gerekir.
Elimde insanlar tablom var:
val insanlar = spark.createDataFrame(Seq(("Cemal",35,"İşçi","Ankara"),("Ceyda",42,"Memur","Kayseri"),("Timur",30,"İşsiz","İstanbul"),("Burcu",29,"Pazarlamacı","Ankara"))).toDF("isim","yas","meslek","sehir")
insanlar.show
+-----+---+-----------+--------+
| isim|yas| meslek| sehir|
+-----+---+-----------+--------+
|Cemal| 35| İşçi| Ankara|
|Ceyda| 42| Memur| Kayseri|
|Timur| 30| İşsiz|İstanbul|
|Burcu| 29|Pazarlamacı| Ankara|
+-----+---+-----------+--------+Lookup tablom:
val lookup = spark.createDataFrame(Seq(("Cemal",35,"İşçi","Ankara"),("Burcu",29,"Pazarlamacı","Ankara"))).toDF("isim","yas","meslek","sehir")
lookup.show
+-----+---+-----------+------+
| isim|yas| meslek| sehir|
+-----+---+-----------+------+
|Cemal| 35| İşçi|Ankara|
|Burcu| 29|Pazarlamacı|Ankara|
+-----+---+-----------+------+Şimdi insanlar tablomu lookup tablosundan geçireceğim. Cemal ve Burcu lookup tablosunda olduğuna göre geçecek kişiler Ceyda ile Timur olmalıdır. Bunun için dataset’in ecxept() metodunu kullanıyoruz. Format df1.except(df2)
insanlar.except(lookup).show +-----+---+------+--------+ | isim|yas|meslek| sehir| +-----+---+------+--------+ |Ceyda| 42| Memur| Kayseri| |Timur| 30| İşsiz|İstanbul| +-----+---+------+--------+
10. Spark dataframe’i diske yazmak
df.coalesce(1)
.write
.option("header","true")
.option("sep",",")
.mode("overwrite")
.csv("output/path")coalesce(1): parçaları tek parça haline getirmek için. Çıktıyı alıp birine gönderecekseniz mantıklı. Csv dışındaki formatlar için o formatın adını kullanabilirsiniz. Örneğin parquet(“output/path”). Parquet sütun isimlerinde “( ) + /” gibi karakterleri sevmez. Bunun için alias kullanmanızı tavsiye ederim.
11. SparkSession örneği (SparkSession example)
Aşağıdaki örnek python için. Scala da bundan çok farklı değil.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Spark YARN Deneme") \
.master("yarn") \
.config("spark.executor.memory","2g") \
.config("spark.executor.cores","1") \
.config("spark.executor.instances","2") \
.enableHiveSupport() \
.getOrCreate()12. Spark’ın en sevdiği dosya formatı nedir?
Parquet
13. Spark sütun isimlerinde boşluk varsa selectExpr içinde hata almadan nasıl kullanırız?
df.selectExpr("MAX(`Incident Date`)","MIN(`Incident Date`)").show()14. PySpark ile nümerik bir sütuna ait histogramı nasıl çizeriz? pyspark histogram
Pandas ve matplotlib ile küçük veri dünyasında histogram veya grafik çizmek çocuk oyuncağı. Ancak iş büyük veriye gelince zorlaşıyor. Çünkü veri büyük ve sizin çalıştığınız makineye sığmıyor. O yüzden amele işi worker sunuculara yapıp sadece çizilecek veri setini (epey küçülmüş oluyor çünkü) dirver makineye çağırırsanız burada python dünyasının imkanlarından sonuna kadar faydalanabilirsiniz. Aşağıdaki kod parçacığı spark dataframe’e ait bir nümerik sütunun histogram çizimine aittir.
AgeHH2_histogram = df4.select('AgeHH2').rdd.flatMap(lambda x: x).histogram(20)# Loading the Computed Histogram into a Pandas Dataframe for plotting
pd.DataFrame(
list(zip(*AgeHH2_histogram)),
columns=['bin', 'frequency']
).set_index(
'bin'
).plot(kind='bar');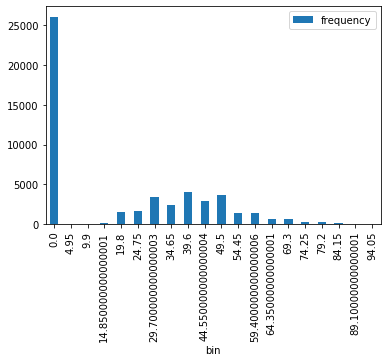
15. PySpark eğitilmiş ML modellerini nasıl kaydeder, üzerine yazarız? PySpark ML Model overwrite
pipeline_model.stages[-1].write().overwrite().save("file:///home/train/venvspark/dev/saved_models/gbt_churn_pca10")16. PySpark birden fazla örüntüye uyan metni değiştirmek – pyspark multiple regexp_replace
PySpark sql fonksiyonu regexp_replace formatı şöyle regexp_replace(‘sütun_adı’, ‘aranan_örüntü’,’yerine geçecek yeni metin’). Burada eğer birden fazla aranan örüntü kullanmak istiyor isek örüntüleri | ile ayırmamız yeterli olacaktır. Aşağıda yapılmak istenen [‘ ve boşluklardan kurtarmak.
df3 = df2.withColumn("exp_tags", F.explode("Tags")) \
.withColumn("clean_tags", F.regexp_replace("exp_tags","\[' |'|]",""))df3.select("Tags","exp_tags","clean_tags").limit(10).toPandas()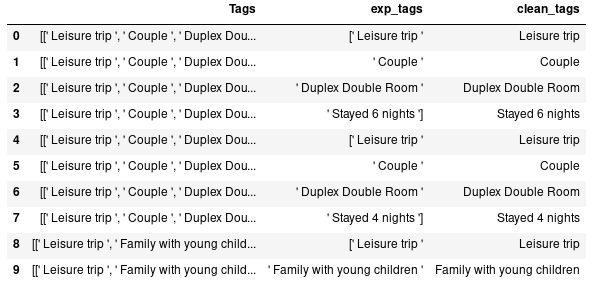
17. Spark uygulamasına birden fazla jar dosyasını nasıl ekleriz?
Zaman zaman Spark’ın kendi sistem classpath’inde olan jar dosyaları haricinde uygulamamıza jar dosyası eklemek isteyebiliriz. Bunların en klasik örnekleri veri tabanı driver ve spark ml harici ml kütüphanelerine ait jar dosyalarıdır. Uygulamaya jar eklemenin bir çok farklı yolu var ben burada PySpark ile SparkSession oluşturma esnasında nasıl yapacağımıza örnek vereceğim. Benim eklemek istediğim jar dosyaları SPARK_HOME/mmlspark_jars klasörü içinde. Önce jar dosyalarının bulunduğu adresi bir string olarak değişkene atıyorum:
mmlspark_jars_dir = os.path.join(os.environ["SPARK_HOME"], "mmlspark_jars")
Daha sonra bu klasör içindeki jar dosyalarının for ile dolaşıp her bir jar dosyasını ve dosya yolunu string olarak bir liste içine atıyorum. Sonuçta her bir jar dosyası ve yolu bir liste elemanı oluyor.
mmlspark_jars = [os.path.join(mmlspark_jars_dir, x) for x in os.listdir(mmlspark_jars_dir)]
Şimdi bu listeyi SparkSession oluştururken kullanıyorum:
spark = SparkSession.builder \
.appName("Churn Scoring LightGBM") \
.master("local[4]") \
.config("spark.jars", ",".join(mmlspark_jars))\
.getOrCreate()Spark UI’dan kontrol yapabiliriz:
18. PySpark log seviyesini değiştirme
conf/log4j.properties içinden
log4j.rootCategory=INFO, console
değerini
log4j.rootCategory=ERROR, console
19. Structured Streaming console output row number and truncate example
streamingQuery = (lines
.writeStream
.format("console")
.outputMode("append")
.trigger(processingTime="1 second")
.option("numRows", 4)
.option("truncate",False)
.start())20. PySpark drop multiple columns
df.drop(*null_column_list_to_drop)
21. PySpark dataframe python dictionary çevirmek – Convert pyspark dataframe to Dictionary
Çok basit, ancak aşırı büyük veriler için uygun değildir.
df.toPandas().to_dict()