

![]()
Merhabalar. Pratik Bilgiler ve Komutlar serisinin bu yazısındaki ipuçları Apache Hive ile ilgili olacaktır. Apache Hive HDFS (Hadoop Distributed File System) üzerinde tutulan verileri SQL yeteneklerimizle manipüle etmemizi sağlayan bir araç. Tek cümle ile tanımlamak gerekirse; veri tabanı tadında ama veri tabanı değil. MapReduce kodu yazmak yerine SQL sorguları ile veri manipülasyonu yapmamızı sağlıyor. Aşağıda başımıza geldiğinde öğrenip yapılması uzun sürecek olan işlerle ilgili pratik ipuçları ve örnekler vermeye çalışacağım.
- #Beeline-üzerinden-sql-dosyası-çalıştırma—Run-sql-file-on-beeline-shell#Beeline-üzerinden-sql-dosyası-çalıştırma—Run-sql-file-on-beeline-shellHive tablosunu yanlışlıkla silmeye karşı koruyabilir miyiz? no_drop
- Hive tablosunu nasıl sorgulamaya kapatırız? offline
- HiveQL ile Dünü Seçmek
- Hive değişkeni kullanmak
- Hive insert into with select
- Hive partitioned table oluşturmak
- Hive dynamic partition
- Hive dynamic partitioned table insert into
- Hive show dynamic partitions (partitions listeleme)
- Hive bucketing tablo oluşturma
- Hive join performas artırma ipuçları
- Csv dosyasından Hive tablosuna veri yükleme (hive load data inpath)
- Hive metastore çalışıyor mu? hiveserver2 çalışıyor mu?
- Hive’ın en çok sevdiği dosya formatı nedir?
- Sqoop ile orc formatındaki partitioned hive tablosuna veri aktarım örneği
- Hive external table nedir? Hive external table yaratma örneği
- Beeline üzerinden sql dosyası çalıştırma – Run sql file on beeline shell
- Hive group by sorgusunda alias kullanma tekniği
- Hive select exclude columns – hive select bazı sütunları hariç tutma
- Beeline warning kapatma – beeline shell close warnigs
- Başka bir tabloyu kullanarak boş bir hive tablosu yaratmak
1. Hive tablosunu yanlışlıkla silmeye karşı koruyabilir miyiz? no_drop
Evet koruyabiliriz. alter komutuyla bunu yapabiliriz.
alter table salaries_temp enable no_drop;
Şimdi silmeyi deneyelim:
drop table salaries_temp; FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Table salaries_temp is protected from being dropped
Bu korumayı kaldırmak da basit:
alter table salaries_temp disable no_drop;
2. Hive tablosunu nasıl sorgulamaya kapatırız? offline
Bazen içindeki veriyi tutarak belli bir süre tabloyu işleme kapatmak isteyebiliriz. Bunun için offline özelliğini aktif hale getirmek yeterlidir.
alter table salaries_temp enable offline;
Şimdi deneyelim bakalım kapanmış mı?
select * from salaries_temp limit 3; FAILED: SemanticException [Error 10113]: Query against an offline table or partition Table salaries_temp
3. HiveQL ile Dünü Seçmek
Hive ile bugünü seçebildiğimiz gibi bazı fonksiyonlarla dünü de seçebiliriz. Aşağıdaki sorgu dünü seçiyor, – leri temizliyor ve string formatına çeviriyor.
SELECT cast(replace( date_sub(CURRENT_DATE, 1), '-','') AS STRING); Çıktı: 20200412
4. Hive değişkeni kullanmak
Bazen otomatize etmek istediğiniz sorgular içinde dinamik olarak değişen birşeylere ihtiyaç duyarsınız. Bunun en tipik örneği tarihtir. Eğer bir sorgu ile her gün bir gün öncesine ait veriyi almak ve bunu otomatize etmek istiyorsanız hive değişkenleri işinizi kolaylaştıracaktır.
-- Dün 00
SET hivevar:YESTERDAY = (concat( regexp_replace( cast(date_sub(CURRENT_DATE, 1 ) AS STRING), "-",""), "00")) ;
-- Bugün 00
SET hivevar:TODAY = ( concat( regexp_replace( cast(CURRENT_DATE AS STRING), "-",""), "00") );
-- sorgu içinde kullanma. Düne ait satışlar
SELCT * FROM satislar
where begindate >= ${hivevar:YESTERDAY} and begindate < ${hivevar:TODAY};Yukarıdaki sorguyu bir cron tab ile her gün çalıştırdığınızda size bir gün önceye ait satışları getirecektir.
5. Hive insert into with select
SQL ile bir talodan yapılan seçimi başka bir taloya insert etmek mümkün olduğu gibi HiveQL ile de mümkündür. Bu insert into table insert_edilecek_tablo select * from secilecek_tablo kadar basit ve kolaydır ancak bazen with select ile başlayan sorgularda da insert edilmesi gerektiğinde olay biraz karışabilir. Aşağıdaki sorgu buna örnektir:
WITH yardimci_tablo AS (SELECT * FROM secilecek_tablo) insert INTO insert_edilecek_tablo PARTITION (partition_column) SELECT col1, col2, col3 ... FROM secilecek_tablo WHERE kosullar
6. Hive partitioned table oluşturmak
Partition table performans arttırmaya yönelik olarak birlikte çağırılma ihtimali olan verileri aynı klasör içinde tutulmasını sağlayarak veri erişiminde hız kazandırır. Partition table oluşturma örnek komutu. İpucu: create komutu esnasında partition sütunu (aşağıdaki örnekte sales_date) kesinlikle tablonun diğer sütunları içinde yer almaz.
CREATE TABLE IF NOT EXISTS sales_partitioned_by_date (sales_id int, country string, product_id int, product_name string, quantity int, unit_price float) partitioned by (sales_date date) row format delimited fields terminated by ',' lines terminated by '\n' stored as ORC;
7. Hive dynamic partition
Static ve dynamic olmak üzere iki tür partitioning var. İlkinde partition kullanıcı tarafından oluşturulur ve kayıt girerken partition belirtilir. İkincisinde belirlenen sütun/lara göre hive dinamik olarak partitioning yapar. Bunun için tablo oluşturma komutu 6. maddede örneği verilen ile aynıdır, yani static partitioning’den farksızdır. Dynamic partition için iki ayarın değiştirilmesi gerekir:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonestrict;
Dynaminc partition açık iken insert komutunda partition column en sonda yer almalıdır.
Statik veya dinamik hangisini kullanalım? Statik veriyi iyi tanıdığımızda kullanılabilir ancak kullanıcıyı yorar. Dinamik kullanıcıyı yormaz hive partition olayını kendisi ayarlar ancak statiğe göre biraz yavaştır.
Ayrıca dynamic partition sayısı node başına 100 ile sınırlıdır aksi halde şu hatayı alırsınız:
Caused by: org.apache.hadoop.hive.ql.metadata.HiveFatalException: [Error 20004]: Fatal error occurred when node tried to create too many dynamic partitions. The maximum number of dynamic partitions is controlled by hive.exec.max.dynamic.partitions and hive.exec.max.dynamic.partitions.pernode. Maximum was set to 100 partitions per node, number of dynamic partitions on this node: 101
8. Hive dynamic partitioned table insert into
Peki hive dynamic partitioned tabloya nasıl veri gireriz. Yukarıda 6. maddede oluşturduğumuz tabloya örnek giriş yapalım. Dikkat edilmesi gereken iki püf nokta var.1. Normal insert komutuna ilave olarak PARTITION(column) belirtilmelidir. 2. Partition column verisi en sonda yer almalıdır.
INSERT INTO sales_partitioned_by_date PARTITION (sales_date) VALUES (100001, 'UK', 2134562, 'String Tanbur', 1, 2389.99, '2020-04-20'), (100002, 'USA', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100002, 'UK', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100004, 'TR', 2134563, 'Markbass Apmlifier', 1, 380.99, '2020-03-19'), (100005, 'FR', 2133563, 'Drump Istanbul', 1, 889.99, '2020-04-11'), (100006, 'UK', 2134563, 'Tamaha Bass Quitar', 1, 2359.99, '2020-04-14'), (100007, 'USA', 2134513, 'Ibanez GRG170DX ', 1, 243.99, '2020-04-09'), (100008, 'TR', 2134560, 'Yamaha ERG 121 GPII', 1, 248.99, '2020-04-03'), (100009, 'UK', 2134569, 'Istanbul Samatya Cymbal Set', 1, 465.00, '2020-03-19'), (100010, 'FR', 2134562, 'Zildjian K Cymbal Set', 1, 895.99, '2020-04-11');
Sonucu görelim:
SELECT * from sales_partitioned_by_date ; Çıktı: sales_id|country|product_id|product_name |quantity|unit_price|sales_date| --------|-------|----------|---------------------------|--------|----------|----------| 100002|USA | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|UK | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100004|TR | 2134563|Markbass Apmlifier | 1| 380.99|2020-03-19| 100009|UK | 2134569|Istanbul Samatya Cymbal Set| 1| 465|2020-03-19| 100008|TR | 2134560|Yamaha ERG 121 GPII | 1| 248.99|2020-04-03| 100007|USA | 2134513|Ibanez GRG170DX | 1| 243.99|2020-04-09| 100005|FR | 2133563|Drump Istanbul | 1| 889.99|2020-04-11| 100010|FR | 2134562|Zildjian K Cymbal Set | 1| 895.99|2020-04-11| 100006|UK | 2134563|Tamaha Bass Quitar | 1| 2359.99|2020-04-14| 100001|UK | 2134562|String Tanbur | 1| 2389.99|2020-04-20|
Aslında her bir parçayı ayrı bir dizine koydu hive. Bunu hdfs dosya sisteminden görebiliriz. Örneğin /user/hive/warehouse/sales_partitioned_by_date diznine göz attığımızda aşağıdaki şekilde bu tabloya ait dizinde klasörler oluştuğunu görürüz.
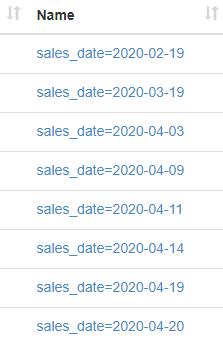
9. Hive show dynamic partitions (partitions listeleme)
Partitined tablo hangi parçalardan oluşuyor aşağıdaki komut ile görebiliriz.
SHOW partitions sales_partitioned_by_country; Çıktı: partition ---------------------| sales_date=2020-02-19| sales_date=2020-03-19| sales_date=2020-04-03| sales_date=2020-04-09| sales_date=2020-04-11| sales_date=2020-04-14| sales_date=2020-04-19| sales_date=2020-04-20|
10. Hive bucketing tablo oluşturma
Bucketing de veri organizasyonu ile ilgilidir. Nasıl partitioning farklı klasörlerde veri tutuyorsa bucketing de partion içinde farklı dosyalarda veri tutar. Bu doyanın kaç tane olacağını tablo oluştururken belirtiriz. Bucketing sorgu ve join performansı için iyidir. Özellikle join sütunları için kullanılabilir. Bucketing tablosu oluşturmadan önce set hive.enforce.bucketing = true; değeri girilmelidir. Örnek bir bucketed tablo oluşturma:
CREATE TABLE IF NOT EXISTS sales_part_country_buck_prodcid (sales_id int, country string, product_id int, product_name string, quantity int, unit_price float) partitioned by (sales_date date) clustered by (product_id) into 4 buckets row format delimited fields terminated by ',' lines terminated by '\n' stored as ORC;
Kayıt girme:
INSERT INTO sales_part_country_buck_prodcid PARTITION (sales_date) VALUES (100001, 'UK', 2134562, 'String Tanbur', 1, 2389.99, '2020-04-20'), (100002, 'USA', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100002, 'UK', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100004, 'TR', 2134563, 'Markbass Apmlifier', 1, 380.99, '2020-03-19'), (100005, 'FR', 2133563, 'Drump Istanbul', 1, 889.99, '2020-04-11'), (100006, 'UK', 2134563, 'Tamaha Bass Quitar', 1, 2359.99, '2020-04-14'), (100007, 'USA', 2134513, 'Ibanez GRG170DX ', 1, 243.99, '2020-04-09'), (100008, 'TR', 2134560, 'Yamaha ERG 121 GPII', 1, 248.99, '2020-04-03'), (100009, 'UK', 2134569, 'Istanbul Samatya Cymbal Set', 1, 465.00, '2020-03-19'), (100010, 'FR', 2134562, 'Zildjian K Cymbal Set', 1, 895.99, '2020-04-11'), (100001, 'UK', 2134562, 'String Tanbur', 1, 2389.99, '2020-04-20'), (100002, 'USA', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100002, 'UK', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100004, 'TR', 2134563, 'Markbass Apmlifier', 1, 380.99, '2020-03-19'), (100005, 'FR', 2133563, 'Drump Istanbul', 1, 889.99, '2020-04-11'), (100006, 'UK', 2134563, 'Tamaha Bass Quitar', 1, 2359.99, '2020-04-14'), (100007, 'USA', 2134513, 'Ibanez GRG170DX ', 1, 243.99, '2020-04-09'), (100008, 'TR', 2134560, 'Yamaha ERG 121 GPII', 1, 248.99, '2020-04-03'), (100009, 'UK', 2134569, 'Istanbul Samatya Cymbal Set', 1, 465.00, '2020-03-19'), (100010, 'FR', 2134562, 'Zildjian K Cymbal Set', 1, 895.99, '2020-04-11'), (100001, 'UK', 2134562, 'String Tanbur', 1, 2389.99, '2020-04-20'), (100002, 'USA', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100002, 'UK', 2134563, 'Lackland Bass Quitar', 1, 1389.99, '2020-02-19'), (100004, 'TR', 2134563, 'Markbass Apmlifier', 1, 380.99, '2020-03-19'), (100005, 'FR', 2133563, 'Drump Istanbul', 1, 889.99, '2020-04-11'), (100006, 'UK', 2134563, 'Tamaha Bass Quitar', 1, 2359.99, '2020-04-14'), (100007, 'USA', 2134513, 'Ibanez GRG170DX ', 1, 243.99, '2020-04-09'), (100008, 'TR', 2134560, 'Yamaha ERG 121 GPII', 1, 248.99, '2020-04-03'), (100009, 'UK', 2134569, 'Istanbul Samatya Cymbal Set', 1, 465.00, '2020-03-19'), (100010, 'FR', 2134562, 'Zildjian K Cymbal Set', 1, 895.99, '2020-04-11');
Sorgu
sales_id|country|product_id|product_name |quantity|unit_price|sales_date| --------|-------|----------|---------------------------|--------|----------|----------| 100002|UK | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|UK | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|USA | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|USA | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|USA | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100002|UK | 2134563|Lackland Bass Quitar | 1| 1389.99|2020-02-19| 100009|UK | 2134569|Istanbul Samatya Cymbal Set| 1| 465|2020-03-19| 100009|UK | 2134569|Istanbul Samatya Cymbal Set| 1| 465|2020-03-19| 100009|UK | 2134569|Istanbul Samatya Cymbal Set| 1| 465|2020-03-19| 100004|TR | 2134563|Markbass Apmlifier | 1| 380.99|2020-03-19| 100004|TR | 2134563|Markbass Apmlifier | 1| 380.99|2020-03-19| 100004|TR | 2134563|Markbass Apmlifier | 1| 380.99|2020-03-19| 100008|TR | 2134560|Yamaha ERG 121 GPII | 1| 248.99|2020-04-03| 100008|TR | 2134560|Yamaha ERG 121 GPII | 1| 248.99|2020-04-03| 100008|TR | 2134560|Yamaha ERG 121 GPII | 1| 248.99|2020-04-03| 100007|USA | 2134513|Ibanez GRG170DX | 1| 243.99|2020-04-09| 100007|USA | 2134513|Ibanez GRG170DX | 1| 243.99|2020-04-09| 100007|USA | 2134513|Ibanez GRG170DX | 1| 243.99|2020-04-09| 100010|FR | 2134562|Zildjian K Cymbal Set | 1| 895.99|2020-04-11| 100010|FR | 2134562|Zildjian K Cymbal Set | 1| 895.99|2020-04-11| 100010|FR | 2134562|Zildjian K Cymbal Set | 1| 895.99|2020-04-11| 100005|FR | 2133563|Drump Istanbul | 1| 889.99|2020-04-11| 100005|FR | 2133563|Drump Istanbul | 1| 889.99|2020-04-11| 100005|FR | 2133563|Drump Istanbul | 1| 889.99|2020-04-11| 100006|UK | 2134563|Tamaha Bass Quitar | 1| 2359.99|2020-04-14| 100006|UK | 2134563|Tamaha Bass Quitar | 1| 2359.99|2020-04-14| 100006|UK | 2134563|Tamaha Bass Quitar | 1| 2359.99|2020-04-14| 100001|UK | 2134562|String Tanbur | 1| 2389.99|2020-04-20| 100001|UK | 2134562|String Tanbur | 1| 2389.99|2020-04-20| 100001|UK | 2134562|String Tanbur | 1| 2389.99|2020-04-20|
Hdfs üzerinden bucketed dosyaları görebiliriz. /user/hive/warehouse/sales_part_country_buck_prodcid/sales_date=2020-02-19 adresinde aşağıdaki 4 parça görünecektir.

Yukarıdaki resmide de görgüğümüz gibi bucket fiziksel bir dosyadır. Bu dosya sayısını değiştirebiliriz. Genelde partitions ile birlikte kullanılır. Bucketed map joinler en hızlı joinlerdir dolayısıyla iki bucketed tablo çok daha hızlı join olur. Eğer partition yapılamayacak kadar çok fazla tekil değer varsa o halde partition kullanmadan bucket kullanılabilir.
11. Hive join performas artırma ipuçları
Hive join operasyonu esnasında ilk tablo bellekte tamponlanır (buffering) ikincisi onun üzerine akıtılır (streaming). Bellek kısıtlı olduğu için büyük tabloyu streaming yapmak gerekir. Bunu ya açıkca belirterek yapabilirsiniz ya da büyük tabloyu sağda bırakarak. Açıkca belirtilmesine örnek aşağıdadır.
SELECT /*+ STREAMTABLE (products) */ categoryname, productname from azhadoop.categories cat JOIN default.products prd ON cat.categoryid = prd.productcategoryid LIMIT 10; Çıktı: categoryname|productname | ------------|---------------------------------------------| Soccer |Quest Q64 10 FT. x 10 FT. Slant Leg Instant U| Soccer |Under Armour Men's Highlight MC Football Clea| Soccer |Under Armour Men's Renegade D Mid Football Cl| Soccer |Under Armour Men's Renegade D Mid Football Cl| Soccer |Riddell Youth Revolution Speed Custom Footbal| Soccer |Jordan Men's VI Retro TD Football Cleat | Soccer |Schutt Youth Recruit Hybrid Custom Football H| Soccer |Nike Men's Vapor Carbon Elite TD Football Cle| Soccer |Nike Adult Vapor Jet 3.0 Receiver Gloves | Soccer |Under Armour Men's Highlight MC Football Clea|
12. Csv dosyasından Hive tablosuna veri yükleme (hive load data inpath)
Öncelikle yükleyeceğiniz dosya türü ile Hive tablosu dosya türü aynı olmalıdır. Yani dtored as parquet olarak create edilmiş bir tabloya .csv dosyası yüklemeye çalışmamalısınız.
Önce yüklenecek csv dosyasını hdfs’e gönderelim.
[murat@cloudera ~]$ hdfs dfs -put retail_db/products.csv /tmp/
Arkasından hive kullanıcısına yetki verelim. Çünkü load komutunu yüklediğimizde bu csv dosyasını kendi /user/hive/warehouse diznine taşıyacak.
[murat@cloudera ~]$ sudo -u hdfs hdfs dfs -chown hive:supergroup /tmp/products.csv
Şimdi beeline veya Dbeaver gibi bir editörden aşağıdaki komut ile tablo içine csv dosyasını yükleyelim:
LOAD data inpath '/tmp/products.csv' INTO TABLE `default`.products;
Yüklenmiş mi kontrol ederim. Çüünkü bazen şema veri uyumsuzluğunda veya ilk satırın başlık olup olmadığı bilgisi yanlış olduğunda tüm tablo null olabilir.
SELECT productid , productname FROM `default`.products limit 10;
Çıktı:
productid|productname |
---------|---------------------------------------------|
1|Quest Q64 10 FT. x 10 FT. Slant Leg Instant U|
2|Under Armour Men's Highlight MC Football Clea|
3|Under Armour Men's Renegade D Mid Football Cl|
4|Under Armour Men's Renegade D Mid Football Cl|
5|Riddell Youth Revolution Speed Custom Footbal|
6|Jordan Men's VI Retro TD Football Cleat |
7|Schutt Youth Recruit Hybrid Custom Football H|
8|Nike Men's Vapor Carbon Elite TD Football Cle|
9|Nike Adult Vapor Jet 3.0 Receiver Gloves |
10|Under Armour Men's Highlight MC Football Clea|Önemli not: Eğer csv dosyasında başlık satırı varsa bunu yükleme (load) komutuyla halledemezsiniz. Mutlaka tablonun özelliklerinde şu şekilde TBLPROPERTIES(‘skip.header.line.count’=’1’) belirtilmesi gerekir.
13. Hive metastore çalışıyor mu? hiveserver2 çalışıyor mu?
pgrep -f org.apache.hive.service.server.HiveServer2 27543 pgrep -f org.apache.hadoop.hive.metastore.HiveMetaStore 27547
14. Hive’ın en çok sevdiği dosya formatı nedir?
ORC
15. Sqoop ile orc formatındaki partitioned hive tablosuna veri aktarım örneği
Partitioned hive tablosu orc formatında ise klasik sqoop hive argümanlarıyla aktarım yapamayız çünkü bunlar orc formatını desteklemiyorlar. Bunun için HCatalog argümanlarını kullanabiliriz. HCatalog, Hadoop için farklı veri işleme araçlarına sahip kullanıcıların Pig, MapReduce ve Hive’ın grid verileri daha kolay okumasını ve yazmasını sağlayan bir tablo ve depolama yönetimi hizmetidir. HCatalog’un tablo soyutlaması, kullanıcılara HDFS’deki verilerin ilişkisel bir görünümünü sunar ve kullanıcıları, verilerinin nerede veya hangi biçimde saklanacağı derdinden kurtarır: RCFile biçimi, metin dosyaları veya SequenceFiles.
Aşağıdaki örnekte partition column invoiceday’dir. Bir günlük aktarım yapılmaktadır.
sqoop import --connect jdbc:postgresql://cloudera/retail \ --driver org.postgresql.Driver \ --username kullanici_adi --password Şifre\ --query "select invoiceno, stockcode, description, quantity, invoicedate, \ unitprice, customerid, country, id, adcools1 from online_retail WHERE invoiceday = '2010-12-03' AND \$CONDITIONS " \ --m 1 \ --hive-partition-key invoiceday --hive-partition-value '2010-12-03' --hive-table sqoop_works.online_retail \ --hcatalog-database sqoop_works --hcatalog-table online_retail --hcatalog-storage-stanza "stored as orcfile"
16. Hive external table nedir? Hive external table yaratma örneği
- Internal table durumunda hem metadata hem veri hive tarafından yönetilir.
- Eğer bu tablo verisine erişmek istiyorsak bunu sadece hive üzerinden yapabiliriz.
- Internal table drop edildiğinde metadata ve veri silinir.
- Normal create table komutu varsayılan olarak internal table yaratır.
- Bu tablolar için varsayılan adres: “/user/hive/warehouse/tabloadı” şeklindedir.
- External table durumunda ise sadece metadata hive tarafından yönetilir.
- Sözdizimi internal table ile aynıdır. Sadece “create external table” ile yaratılır.
- Herhangi bir adres belirtilmez ise bu tablolar da “/user/hive/warehouse/tabloadı” dizininde saklanır.
- Bu tabloların metadatası hive tarafından, veri ise hdfs tarafından yönetilir. Internal ile arasındaki en büyük fark budur.
- External table drop edildiğinde metadata silinir ancak veri hdfs’te kalmaya devam eder.
Örnek:
Öncelikle external table yaratılacak dosya/lar bir klasör içinde olmalıdır.
hdfs dfs -mkdir -p /user/train/datasets/hiveExternal/advertising # veriyi dizine taşı hdfs dfs -put ~/datasets/Advertising.csv /user/train/datasets/hiveExternal/advertising
Create table
create external table if not exists adv_ext like advertising location '/user/train/datasets/hiveExternal/advertising';
Sonuçları kontrol et.
select * from adv_ext limit 5; /* * id|tv |radio|newspaper|sales| --|-----|-----|---------|-----| 1|230.1| 37.8| 69.2| 22.1| 2| 44.5| 39.3| 45.1| 10.4| 3| 17.2| 45.9| 69.3| 9.3| 4|151.5| 41.3| 58.5| 18.5| 5|180.8| 10.8| 58.4| 12.9| */ SELECT count(1) from adv_ext; -- 200
17. Beeline üzerinden sql dosyası çalıştırma – Run sql file on beeline shell
beeline -n myuser -w ${HOME}/sqoop.password -u jdbc:hive2://localhost:10000 \
-f /home/train/mysql.sql18. Hive group by sorgusunda alias kullanma tekniği
Hive sorgularında seçilen sütunlara as ile alias verirseniz group by içinde alias olarak kullandığınız sütun ismini tanımayacaktır. Bunu çözmek için küçük bir ayar değişikliği yapıp group by cümleciğinde sütunlara indeksleri ile işaret edebilirsiniz.
# Ayar
set hive.groupby.orderby.position.alias=true;
# Sorgu
SELECT sk_id_bureau,
case when status in ('C') then 1 else 0 end as status_c,
case when status in (0) then 1 else 0 end as status_0,
case when status in ('X') then 1 else 0 end as status_x,
case when status in (1) then 1 else 0 end as status_1,
case when status in (2) then 1 else 0 end as status_2,
case when status in (3) then 1 else 0 end as status_3,
case when status in (4) then 1 else 0 end as status_4,
case when status in (5) then 1 else 0 end as status_5,
SUM(months_balance) as months_balance
from homecredit.bureau_balance_orc_snappy bb
group by 1,2,3,4,5,6,7,8,9
limit 10;Çıktı
sk_id_bureau|status_c|status_0|status_x|status_1|status_2|status_3|status_4|status_5|months_balance|
------------|--------|--------|--------|--------|--------|--------|--------|--------|--------------|
5001709| 0| 0| 1| 0| 0| 0| 0| 0| -1001|
5001709| 1| 0| 0| 0| 0| 0| 0| 0| -3655|
5001710| 0| 0| 1| 0| 0| 0| 0| 0| -2021|
5001710| 0| 1| 0| 0| 0| 0| 0| 0| -254|
5001710| 1| 0| 0| 0| 0| 0| 0| 0| -1128|19. Hive select exclude columns – hive select bazı sütunları hariç tutma
select `(sk_id_prev|sk_id_prev|sk_id_prev|name_contract_status_active_sum|sk_dpd_mean|sk_dpd_max)?+.+` <table_name>
20. Beeline warning kapatma – beeline shell close warnigs
Beeline shell kullanırken bilgi logları sonuçlarınızı görmeyi güçleştiriyorsa şu şekilde bunu kapatabilirsiniz.
set hive.server2.logging.operation.level=NONE;
21. Başka bir tabloyu kullanarak boş bir hive tablosu yaratmak
create table if not exists adv_lk like advertising; select * from adv_lk; +------------+------------+---------------+-------------------+---------------+ | adv_lk.id | adv_lk.tv | adv_lk.radio | adv_lk.newspaper | adv_lk.sales | +------------+------------+---------------+-------------------+---------------+ +------------+------------+---------------+-------------------+---------------+