

![]()
Bölüm 5/6’da düzenli yapıda olmayan metin verilerini, çeşitli araçlarla nasıl düzenli hale getirebileceğimizi öğrendik. Bu bölümde bahsi geçen dönüştürme araçlarının konu modellemesi üzerinde metin analizine katkısı anlatılacaktır.
6. Bölüm – Konu Modellemesi – Topic Modelling
Metin madenciliğinde , döküman topluluklarını yani blog gönderileri veya haber makaleleri gibi metinleri anlayabilmek için doğal gruplara ayırmamız gerekir. Konu modellemesi, sayısal verileri kümelemeye benzer bir şekilde metin içerisinde aradığımız şeylerden emin olmadığımız durumlarda bile doğal metin gruplarını bulmaya çalışır.
Latent Dirichlet Allocation (LDA), konu modellemesi için popüler bir yöntemdir. Her belge konuların bir karışımıdır ve her konu ise kelimelerin karışımı olarak ele alınır. Bu da belgelerin doğal dilin tipik kullanımını yansıtarak, ayrık gruplara ayrılması yerine içerik bakımından birbiri ile örtüşmesini sağlar.
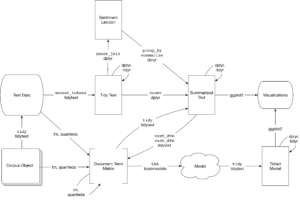
Yukarıdaki şema konu modellemeyi de içeren bir metin analizinin bir akış şemasıdır. topicmodels paketi ile elimizdeki Document-Term Matrix (Döküman-Terim Matrisi) ’i girdi olarak alır ve tidytext ile işlenebilecek bir model oluşturur. Böylelikle dplyr ve ggplot2 kütüphaneleri ile manipülasyon ve görselleştirme işlemleri yapılır.
Şemada gördüğümüz gibi şuana kadar öğrendiğimiz tüm araçlar ile konu modellemesi için tidy text – düzenli metin ilkelerini kullanabiliriz. Bu bölümde topicmodels paketi ile LDA nesnelerini nasıl işleyeceğimizi öğreneceğiz. Ayrıca kitaplardan bölümler ile kümeleme işlemleri yapıp, metinler içerisindeki farklılığı anlayıp anlamadığımızı göreceğiz.
6.1. Latent Dirichlet Allocation
Latent Dirichlet Allocation, konu modellemesi için en yaygın algoritmalardan biridir. İşin matematiğine girmeden, konu modellemesinin iki ilke tarafından ilerlediğini anlayabiliriz.
- Her bir belge konuların bir karışımıdır. Her bir belge, çeşitli konulardan belirli oranlarda kelimeler içerir. Örneğin, elimizdeki metinin iki başlık altında modellendiğini düşünelim. “1. Belge” %90 A konusunu ve %10 B konusunu, “2. Belge” %30 A konusunu ve %70 B konusunu içersin.
- Her bir belge konuların karışımı ise her bir konu da kelimelerin karışımıdır. Örneğin, Amerikan haberlerinin “siyaset” ve “eğlence” konuları ile iki konu modeli olduğunu düşünelim. Siyaset konusundaki en yaygın kelimeler “Başkan”, “Hükümet”, “Meclis” gibi kelimelerden oluşabilirken, eğlence konusundaki en yaygın kelimeler “filmler”, “aktör” ve “televizyon” kelimelerinden oluşabilir. Ayrıca bazı kelimeler de konular arasında paylaşılıyor olabilir. “bütçe” gibi bir kelime hem siyaset hem de eğlence konularında eşit olarak görülebilir.
LDA yukarıdaki iki maddeyi aynı anda tahmin etmek için yapılmış bir yöntemdir: Her bir konuyla ilişkili kelimelerin karışımını bulmak ve ayrıca her bir dökümanı tanımlayan konuların karışımını belirlemek temel amaçtır.
Associated Press veri seti bir Document-Term Matrix olarak topicmodels paketi içerisinde yer alır. Bu veri seti 1988’de yayınlanan bir Amerikan haber ajansından 2246 haber makalesinin bir derlemesidir.
library(topicmodels)
data("AssociatedPress")
AssociatedPress## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)topicmodels paketi LDA() fonksiyonu ile LDA modeli oluşturmamızı sağlar. k = 2 argümanını kullanırsak iki konulu bir model oluşturmuş oluruz.
k artarsa modeldeki konu sayısı da artar.
LDA() fonksiyonu kelimelerin konularla nasıl ilişkilendirildiği ve konuların belgerle nasıl ilişkilendirildiği gibi modelin tüm ayrıntılarını içeren bir nesne verir.
# modelin çıktısını ön görebilmek için seed kullanma
ap_lda <- LDA(AssociatedPress, k = 2, control = list(seed = 1234))
ap_lda## A LDA_VEM topic model with 2 topics.Modelin oluşturulması kolay kısımdı. Analizin geri kalanı için tidytext paketi ile modelin incelenmesini ve yorumlanması gerekir.
6.1.1. Kelime-Konu Olasılıkları – Word-Topic Probabilities
broom paketinden tidy() fonksiyonunu anlatmıştık. tidy(), model nesnelerini düzenleme için kullanılır. tidytext paketi modelden konu başına kelime olasılıklarını incelemek için β’yı (“Beta”) kullanır.
library(tidytext)
ap_topics <- tidy(ap_lda, matrix = "beta")
ap_topics## # A tibble: 20,946 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 aaron 1.69e-12
## 2 2 aaron 3.90e- 5
## 3 1 abandon 2.65e- 5
## 4 2 abandon 3.99e- 5
## 5 1 abandoned 1.39e- 4
## 6 2 abandoned 5.88e- 5
## 7 1 abandoning 2.45e-33
## 8 2 abandoning 2.34e- 5
## 9 1 abbott 2.13e- 6
## 10 2 abbott 2.97e- 5
## # ... with 20,936 more rowsYukarıdaki işlevin modeli satır başına bir konu ve bir terim olarak dönüştürdüğüne dikkat edelim. Her bir kombinasyon için model, kelimelerin bir konuya ait olma olasılıklarını hesaplar.
Örneğin, “aaron” kelimesinin 1. ve 2. konuya ait olma olasılıklarına yani beta’ya bakalım.
ap_topics[1:2,]## # A tibble: 2 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 aaron 1.69e-12
## 2 2 aaron 3.90e- 5top_n() ile her konu içerisindeki en yaygın 10 terimi bulmak için dplyr kütüphanesini kullanabiliriz. Sonrasında ggplot2 kütüphanesi ile bunu görselleştirelim. Aşağıda her bir konu içindeki en yaygın terimleri göreceksiniz.
library(ggplot2)
library(dplyr)
ap_top_terms <- ap_topics %>%
group_by(topic) %>%
top_n(10, beta) %>%
ungroup() %>%
arrange(topic, -beta)
ap_top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip() 
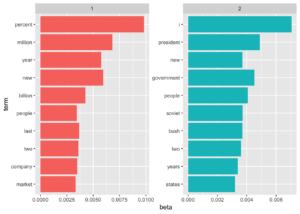
Yukarıdaki görselleştirme ile makalelerden çıkarılan iki konuyu anlamamızı sağlar. 1. konudaki kelimelerden bazıları, “percent”, “million”, “billion” ve “company” kelimeleri iş veya finansal haberler olabilir, 2. konudaki kelimelerden bazıları ise, “president”, “goverment” ve “soviet” kelimeleri de siyasi haberler olabilir. Yani bu kelimelerden yola çıkarak 1. konu iş veya finansal haberler, 2. konu ise siyasi haberler olabilir.
Ayrıca iki konuda da aynı kelimelerin ortaya çıkması konu modellemesinin, kümelemeye göre daha avantajlı olduğunu gösterir.
Alternatif olarak, konu 1 ve konu 2 arasındaki β’nın büyük bir fark olduğunu düşünelim. β1β1 ve β2β2 ’lerin 2 tabanında logaritmik oranlarını almak işe yarar bir yöntemtir. Çünkü logaritmik oranlar aradaki farkı simetrik bir hale getirir. Konulardaki yaygın kelimeleri bulmak için de betaların 1/1000’den büyük olmasını isteriz. logaritmik oran pozitif ve negatif değerler alır. B1B1, B2B2’den büyük ise logaritmik oran negatif bir değer olur. Eğer B2B2, B1B1’den büyük olursa logaritmik oran pozitif bir değer olur.
library(tidyr)
beta_spread <- ap_topics %>%
mutate(topic = paste("topic", topic)) %>%
spread(topic, beta) %>%
filter(topic1 > .001 | topic2 > .001) %>%
mutate(log_ratio = log2(topic2 / topic1))
beta_spread## # A tibble: 198 x 4
## term topic1 topic2 log_ratio
## <chr> <dbl> <dbl> <dbl>
## 1 administration 0.000431 0.00138 1.68
## 2 ago 0.00107 0.000842 -0.339
## 3 agreement 0.000671 0.00104 0.630
## 4 aid 0.0000476 0.00105 4.46
## 5 air 0.00214 0.000297 -2.85
## 6 american 0.00203 0.00168 -0.270
## 7 analysts 0.00109 0.000000578 -10.9
## 8 area 0.00137 0.000231 -2.57
## 9 army 0.000262 0.00105 2.00
## 10 asked 0.000189 0.00156 3.05
## # ... with 188 more rowsİki konu arasındaki büyük farka sahip olan kelimelerin görselleştirmesini yapalım. Konu 1 ve Konu 2 arasındaki beta farkının büyük olduğu kelimeler,
ggplot(
rbind(
beta_spread %>% select(term, log_ratio) %>% top_n(10),
beta_spread %>% select(term, log_ratio) %>% top_n(-10)),
aes(
reorder(term, log_ratio),log_ratio)
)+
geom_col()+
coord_flip()+
labs(x = "term",
y = "Log2 ratio of beta in topic 2 / topic 1")## Selecting by log_ratio## Selecting by log_ratio
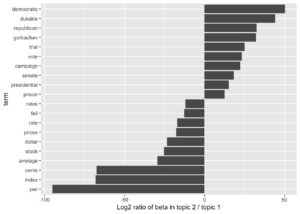
Konu 2’de yer alan kelimelerin “democratic” ve “republican” gibi siyasi partilerin yanı sıra “dukakis” ve “gorbachev” gibi politikacıların isimlerinin de geçtiğini görüyoruz. Konu 1’de ise “yen”, “dollar” gibi para birimlerinin yanı sıra “index”, “prices” gibi finansal kelimeleri de görüyoruz. Bu kelimeler iki konunun siyasi ve finansal haberler olduğunu doğrulamaya yeterli olur.
6.1.2. Döküman-Konu Olasılıkları – Document-Topic Probabilities
Her bir konuyu kelimelerin bir karışımı olarak tahmin etmenin yanında, LDA ayrıca her bir dökümanı konuların bir karışımı olarak modellemektedir.tidy() fonksiyonu içerisinde matrix argümanına “beta” yerine “gamma” yazarsak döküman-konu modelini ederiz.
ap_documents <- tidy(ap_lda, matrix = "gamma")
ap_documents## # A tibble: 4,492 x 3
## document topic gamma
## <int> <int> <dbl>
## 1 1 1 0.248
## 2 2 1 0.362
## 3 3 1 0.527
## 4 4 1 0.357
## 5 5 1 0.181
## 6 6 1 0.000588
## 7 7 1 0.773
## 8 8 1 0.00445
## 9 9 1 0.967
## 10 10 1 0.147
## # ... with 4,482 more rowsgamma değerlerinin her biri, mensubu olduğu konudan oluşturulan belgenin tahmin edilen bir oranını ifade eder. Örneğin, kurulan model, Belge 1’deki kelimelerin yalnızca %24.8’inin Konu 1’den oluşturulduğunu tahmin edebiliriz.
Bu dökümanların çoğu iki konunun karışımından elde edildi, ama Döküman 6’ya bakarsak Konu 1 için gamma değerinin sıfıra yakın olduğunu görebiliriz. Bunu da kontrol etmek için tidy() ile Document-Term Matrix – Döküman-Terim Matrisini ve bu dökümanda en sık kullanılan kelimelerin neler olduğuna bakalım.
tidy(AssociatedPress) %>%
filter(document == 6) %>%
arrange(desc(count))## # A tibble: 287 x 3
## document term count
## <int> <chr> <dbl>
## 1 6 noriega 16
## 2 6 panama 12
## 3 6 jackson 6
## 4 6 powell 6
## 5 6 administration 5
## 6 6 economic 5
## 7 6 general 5
## 8 6 i 5
## 9 6 panamanian 5
## 10 6 american 4
## # ... with 277 more rowsEn yaygın kelimelere dayanarak, Amerikan hükümeti ile Panama diktatörü Manuel Noriega arasındaki ilişki hakkında bir makale olduğunu düşünebiliriz. Bu da algoritmanın doğru çalıştığını ve Döküman 6’nın Konu 2’ye (Siyasi haberler olarak) eğilimli olduğunu gösterir.
6.2. Örnek: Büyük Kütüphane Soygunu
İstatistiksel bir yöntemi incelememiz gerektiğinde, doğru cevabı bildiğimiz çok basit bir durum için bu yöntemi denememiz yararlı olacaktır.
Örneğin, metin madenciliği için dört ayrı konuyla ilgili bir dizi belge toplayalım. Daha sonra algoritmanın dört grubu da doğru şekilde ayırt edip edemeyeceğini görmek için konu modellemesini gerçekleştirebiliriz.
Elimizde dört adet kitap var ve bu dört kitabın bir vandal tarafından karıştırıldığını ve parçalara ayırıldığını düşünelim:
- Charles Dickens – Great Expectations
- HG Wells – The War of the Worlds
- Jules Verne – Twenty Thousand Leagues Under the Sea
- Jane Austen – Pride and Prejudice
Bu vandal, kitapları bireysel bölümlere ayırdı ve büyük bir yığın halinde bıraktı. Bu dağınık bölümleri orijinal kitaplarına nasıl geri yükleyebiliriz? Bireysel bölümlerin etiketlenmemiş olduğundan zor bir sorun ile karşı karşıyayız. Kelimeleri hangi gruplara ayıracağımızı bilmiyoruz. Bu yüzden konu modellemesi ile bölümlerden her birinin kitaplardan birini temsil eden farklı konulara nasıl ayrıldığını keşfedeceğiz.
Bu dört kitabı gutenberg paketi ile elde edebiliriz.
titles <- c("Twenty Thousand Leagues under the Sea", "The War of the Worlds",
"Pride and Prejudice", "Great Expectations")library(gutenbergr)
books <- gutenberg_works(title %in% titles) %>%
gutenberg_download(meta_fields = "title")Ön işlem olarak, bunları bölümlere ayıralım, daha sonra tidytext paketinden unnest_tokens() ile kelimelere parçalayalım. Daha sonra da duraklama kelimelerini (stop words) kaldırmamız gerekir.
Biz böyle bir adla ayrı bir “belgenin”, her biri her bölüm tedavi ediyoruz Great Expectations_1 veya Pride and Prejudice_11. (Diğer uygulamalarda, her belge bir gazete makalesi veya bir blog yazısı olabilir).
Her bir bölümü bir belge olarak ayırabilmemiz için her birini isimlendirmemiz gerekir, Great Expectations_1, Pride and Prejudice_11 gibi.
library(stringr)
# Dökümanları ayırma işlemi, her biri bir bölümü temsil edecek
by_chapter <- books %>%
group_by(title) %>%
mutate(chapter = cumsum(str_detect(text, regex("^chapter ", ignore_case = TRUE)))) %>%
ungroup() %>%
filter(chapter > 0) %>%
unite(document, title, chapter)
# kelimelere parçalama
by_chapter_word <- by_chapter %>%
unnest_tokens(word, text)
# belge-terim frekansı bulma
word_counts <- by_chapter_word %>%
anti_join(stop_words) %>%
count(document, word, sort = TRUE) %>%
ungroup()## Joining, by = "word"word_counts## # A tibble: 104,722 x 3
## document word n
## <chr> <chr> <int>
## 1 Great Expectations_57 joe 88
## 2 Great Expectations_7 joe 70
## 3 Great Expectations_17 biddy 63
## 4 Great Expectations_27 joe 58
## 5 Great Expectations_38 estella 58
## 6 Great Expectations_2 joe 56
## 7 Great Expectations_23 pocket 53
## 8 Great Expectations_15 joe 50
## 9 Great Expectations_18 joe 50
## 10 The War of the Worlds_16 brother 50
## # ... with 104,712 more rows6.2.1. Kitapların Bölümlerinde LDA
Şu anda veri setimiz düzenli veri formatında, ancak topicmodels paketi ile Document-Term Matrix yani Döküman-Terim Matrisine dönüştürmemiz gerekiyor. Bunu da cast_dtm() fonksiyonu ile yapalım.
chapters_dtm <- word_counts %>%
cast_dtm(document, word, n)## Warning: Trying to compute distinct() for variables not found in the data:
## - `row_col`, `column_col`
## This is an error, but only a warning is raised for compatibility reasons.
## The operation will return the input unchanged.chapters_dtm## <<DocumentTermMatrix (documents: 193, terms: 18215)>>
## Non-/sparse entries: 104722/3410773
## Sparsity : 97%
## Maximal term length: 19
## Weighting : term frequency (tf)Şimdi LDA() fonksyionu ile konu modellememizi dört olarak ayarlabiliriz. Çünkü elimizde dört adet kitap var ve dört adet konu aradığımızı biliyoruz. Başka problemler için k değerinin ayarlanması gerekebilir.
chapters_lda <- LDA(chapters_dtm, k = 4, control = list(seed = 1234))
chapters_lda## A LDA_VEM topic model with 4 topics.Associated Press verilerinde yaptığımız gibi, her bir konu başına düşen kelime olasılıklarını inceleyebiliriz.
chapter_topics <- tidy(chapters_lda, matrix = "beta")
chapter_topics## # A tibble: 72,860 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 joe 1.44e-17
## 2 2 joe 5.96e-61
## 3 3 joe 9.88e-25
## 4 4 joe 1.45e- 2
## 5 1 biddy 5.14e-28
## 6 2 biddy 5.02e-73
## 7 3 biddy 4.31e-48
## 8 4 biddy 4.78e- 3
## 9 1 estella 2.43e- 6
## 10 2 estella 4.32e-68
## # ... with 72,850 more rowsYukarıdaki işlevin modeli satır başına bir konu ve bir terim olarak dönüştürdüğüne dikkat edelim. Her bir kombinasyon için model, kelimelerin bir konuya ait olma olasılıklarını hesaplar. Örneğin, “joe” kelimesinin, Konu 1, Konu 2 ve Konu 3 içerisinde olma olasılığı neredeyse sıfırdır, ancak Konu 4’te “joe” kelimesi konunun %1.45’ini oluşturur.
Her bir konudaki en iyi 5 terimi bulmak için dplyr kütüphanesinden top_n() fonksiyonunu kullanabiliriz .
top_terms <- chapter_topics %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms## # A tibble: 20 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 elizabeth 0.0141
## 2 1 darcy 0.00881
## 3 1 miss 0.00871
## 4 1 bennet 0.00694
## 5 1 jane 0.00649
## 6 2 captain 0.0155
## 7 2 nautilus 0.0131
## 8 2 sea 0.00884
## 9 2 nemo 0.00871
## 10 2 ned 0.00803
## 11 3 people 0.00679
## 12 3 martians 0.00646
## 13 3 time 0.00534
## 14 3 black 0.00528
## 15 3 night 0.00449
## 16 4 joe 0.0145
## 17 4 time 0.00685
## 18 4 pip 0.00683
## 19 4 looked 0.00637
## 20 4 miss 0.00623Yukarıdaki çıktı ggplot2 görselleştirilmesi ile daha anlamlı hale gelecektir. Her bir konu için en yaygın olan kelimeleri görelim.
library(ggplot2)
top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip()
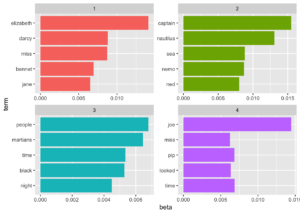
Konuların oldukça dört kitap ile ilişkili olduğunu görmekteyiz. “captain”, “nautilus”, “sea”, ve “nemo” kelimeleri “Twenty Thousand Leagues Under the Sea” kitabına, “jane”, “darcy”, ve “elizabeth” kelimeleri “Pride and Prejudice” kitabına aittir. “Great Expectations” kitabından “pip”, “joe” kelimelerini ve “The War of the Worlds” kitabından da “martians”, “black” ve “night” kelimelerini görmekteyiz.
Ayrıca LDA “bulanık kümeleme” yöntemi ile uyumlu olarak Konu 1 ve Konu 4’te “miss” kelimesinin geçtiğini, Konu 3 ve Konu 4’te de “time” kelimesinin geçtiğini görüyoruz. Birden çok konular arasında ortak kelimelerin de olduğunu görüyoruz.
6.2.2 Döküman Başına Sınıflandırma – Per-Document Classification
Bu analizdeki her belge tek bir bölümü temsil ediyordu. Bundan kaynaklı her bir belge ile hangi konuların ilişkilendirilebileceğini anlamamız gerebilir. Bölümleri doğru kitaplarda bir araya getirme şansımız var mıdır ? Bunu her bir belge için konu olasılıklarına yani γ gamma’ya bakarak bulabiliriz.
chapters_gamma <- tidy(chapters_lda, matrix = "gamma")
chapters_gamma## # A tibble: 772 x 3
## document topic gamma
## <chr> <int> <dbl>
## 1 Great Expectations_57 1 0.0000134
## 2 Great Expectations_7 1 0.0000146
## 3 Great Expectations_17 1 0.0000210
## 4 Great Expectations_27 1 0.0000190
## 5 Great Expectations_38 1 0.355
## 6 Great Expectations_2 1 0.0000171
## 7 Great Expectations_23 1 0.547
## 8 Great Expectations_15 1 0.0124
## 9 Great Expectations_18 1 0.0000126
## 10 The War of the Worlds_16 1 0.0000107
## # ... with 762 more rowsElde ettiğimiz gamma değerleri belgelerin hangi konudan olabileceğinin olasılığıdır. Great_Expectations_5 belgesindeki her kelimenin Konu !’den yani Pride and Prejudice kitabından olma olasılığının yalnızca 0.00135 olduğunu tahmin etmektedir.
Şimdi konu olasılıklarına sahip olduğumuza göre unsupervised learning (denetimsiz öğrenme) ile elimizdeki dört kitabı ayırt etmede ne kadar başarılı olacağımızı görelim.
Öncelikle, belge ismini başlık (“title”) ve bölüm (“chapter”) olmak üzere yeniden ayırdık ve ardından her bir belge başına konu olasılıklarını görselleştirebileceğiz.
chapters_gamma <- chapters_gamma %>%
separate(document, c("title", "chapter"), sep = "_", convert = TRUE)
chapters_gamma## # A tibble: 772 x 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 Great Expectations 57 1 0.0000134
## 2 Great Expectations 7 1 0.0000146
## 3 Great Expectations 17 1 0.0000210
## 4 Great Expectations 27 1 0.0000190
## 5 Great Expectations 38 1 0.355
## 6 Great Expectations 2 1 0.0000171
## 7 Great Expectations 23 1 0.547
## 8 Great Expectations 15 1 0.0124
## 9 Great Expectations 18 1 0.0000126
## 10 The War of the Worlds 16 1 0.0000107
## # ... with 762 more rowsKitaplardaki her bir bölüm için gamma olasılıkları,
chapters_gamma %>% mutate(title = reorder(title, gamma * topic)) %>% ggplot(aes(factor(topic), gamma)) + geom_boxplot() + facet_wrap(~ title)
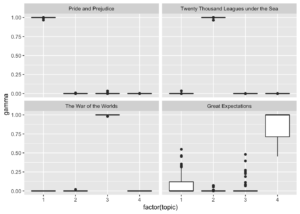
Neredeyse kitapladaki tüm bölümler benzersiz te bir konu ile tanımlandı. Bunlar “Pride and Prejudice”, “War of the Worlds” ve “Twenty Thousand Leagues Under the Sea” kitaplarıdır.
Great Expectations (Konu 4) kitabından bazı bölümler diğer konularla bir şekilde ilişkiliydi.Bir bölümle en çok ilişkilendirilen konunun başka bir kitaba ait olduğu durumlar var mı?
İlk olarak, her bir bölümü top_n() fonksiyonunu kullanarak en çok ilişkili olan konular ile etkili bir biçimde sınıflandırabiliriz.
chapter_classifications <- chapters_gamma %>%
group_by(title, chapter) %>%
top_n(1, gamma) %>%
ungroup()
chapter_classifications## # A tibble: 193 x 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 Great Expectations 23 1 0.547
## 2 Pride and Prejudice 43 1 1.000
## 3 Pride and Prejudice 18 1 1.000
## 4 Pride and Prejudice 45 1 1.000
## 5 Pride and Prejudice 16 1 1.000
## 6 Pride and Prejudice 29 1 1.000
## 7 Pride and Prejudice 10 1 1.000
## 8 Pride and Prejudice 8 1 1.000
## 9 Pride and Prejudice 56 1 1.000
## 10 Pride and Prejudice 47 1 1.000
## # ... with 183 more rowsDaha sonra her bir kitap için bölümler arasındaki en yaygın konuları karşılaştırabiliriz ve en fazla yanlış tanımlanmş olanları görebiliz. Bunu da “consensus” ile bakabiliriz.
book_topics <- chapter_classifications %>%
count(title, topic) %>%
group_by(title) %>%
top_n(1, n) %>%
ungroup() %>%
transmute(consensus = title, topic)
chapter_classifications %>%
inner_join(book_topics, by = "topic") %>%
filter(title != consensus)## # A tibble: 2 x 5
## title chapter topic gamma consensus
## <chr> <int> <int> <dbl> <chr>
## 1 Great Expectations 23 1 0.547 Pride and Prejudice
## 2 Great Expectations 54 3 0.481 The War of the WorldsLDA’a göre “Pride and Prejudice” Konu 1 ve “The War of the Worlds” Konu 3 olarak tanımladığı gibi “Great Expectations” kitabında ise sadece iki bölümün yanlış sınıflandırıldığı görüyoruz. Denetimsiz öğrenmede kümeleme yöntemi için bu sonuç kötü değildir.
6.2.3. Kelime Atamaları: augment
LDA algoritmasının bir adımı da her bir belgedeki kelimeleri bir konuya atamaktır. Belgedeki daha fazla kelimeler bu konuya atanır. Genellikle gamma ağırlığı fazla olan document-topic classification yani döküman-konu sınıflandırmasına geçecektir.
Orijinal belge-kelime çiftlerini bilmek ve her bir belgedeki kelimelerin hangi konuya atandığını bulmak isteyebiliriz. Broom paketindeki augment() fonksiyonu düzenli model çıktısını almak için bir yolu sağlar. tidy() fonksyionu modelin istatistiksel bileşenlerini alırken, augment() fonksiyonu ise orjinal verilerin her bir gözlemine bilgi eklemek için bir model kullanır.
assignments <- augment(chapters_lda, data = chapters_dtm)
assignments## # A tibble: 104,722 x 4
## document term count .topic
## <chr> <chr> <dbl> <dbl>
## 1 Great Expectations_57 joe 88 4
## 2 Great Expectations_7 joe 70 4
## 3 Great Expectations_17 joe 5 4
## 4 Great Expectations_27 joe 58 4
## 5 Great Expectations_2 joe 56 4
## 6 Great Expectations_23 joe 1 4
## 7 Great Expectations_15 joe 50 4
## 8 Great Expectations_18 joe 50 4
## 9 Great Expectations_9 joe 44 4
## 10 Great Expectations_13 joe 40 4
## # ... with 104,712 more rowsYukarıdaki kod, Kitap-Terim frekanslarının (book-term counts) düzeni bir veri setini verir. Ancak veri setine fazladan bir sütun ekler, bu sütun topic. topic değikeni ile her bir terim belgelerin içine atanmıştır. (Mevcut değişkenlerin üzerine yazılmasındansa augment() fonksiyonu ek değişken oluşturur). Hangi kelimelerin yanlış sınıflandırıldığını bulmak için assignments tablosunu uygun kitap başlıklarıyla birleştirebiliriz .
assignments <- assignments %>%
separate(document, c("title", "chapter"), sep = "_", convert = TRUE) %>%
inner_join(book_topics, by = c(".topic" = "topic"))
assignments## # A tibble: 104,722 x 6
## title chapter term count .topic consensus
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Great Expectations 57 joe 88 4 Great Expectations
## 2 Great Expectations 7 joe 70 4 Great Expectations
## 3 Great Expectations 17 joe 5 4 Great Expectations
## 4 Great Expectations 27 joe 58 4 Great Expectations
## 5 Great Expectations 2 joe 56 4 Great Expectations
## 6 Great Expectations 23 joe 1 4 Great Expectations
## 7 Great Expectations 15 joe 50 4 Great Expectations
## 8 Great Expectations 18 joe 50 4 Great Expectations
## 9 Great Expectations 9 joe 44 4 Great Expectations
## 10 Great Expectations 13 joe 40 4 Great Expectations
## # ... with 104,712 more rowsGerçek kitabın (title) ve ona atanan kitabın (consensus) bu birleşimi daha fazla keşif yapmak için yararlıdır. Örnek olarak bir kitaptaki kelimelerin diğer kitaplara ne kadar sıklıkla atanmış olabileceğini gösteren bir “confusion matrix” yani karışıklık matrisini görselleştirebiliriz. Burada dplyr ve ggplot2 küüphanelerini etkin bir biçimde kullanalım.
Aşağıdaki görselleştirme Confusion Matrix ile LDA’nın her bir kitaptaki kelimelerin atandığı kitapları görebiliriz. Her bir satır yani y-ekseni kelimelerin geldikleri kitapları ve her bir sütun yani x-ekseni de kelimelerin atandıkları kitapları gösterir.
assignments %>%
count(title, consensus, wt = count) %>%
group_by(title) %>%
mutate(percent = n / sum(n)) %>%
ggplot(aes(consensus, title, fill = percent)) +
geom_tile() +
scale_fill_gradient2(high = "red", label = percent_format()) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
panel.grid = element_blank()) +
labs(x = "Book words were assigned to",
y = "Book words came from",
fill = "% of assignments") 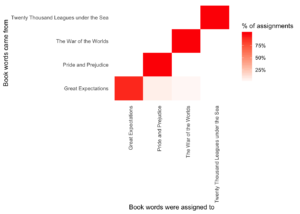
“Pride and Prejudice”, “Twenty Thousand Leagues Under the Sea” ve “The War of the Worlds” kitaplarındaki kelimeler hemen hemen doğru bir şekilde atanmış olmasına rağmen, “Great Expectations” kitabındaki kelimelerin çok fazla sayıda yanlış atanmış olduğunu görüyoruz. Bunun da nedeni yukarıda da görmüştük, iki bölüm yanlış sınıflandırılmıştı.
Peki en çok rastlanan yanlış kelimeler nelerdi?
wrong_words <- assignments %>%
filter(title != consensus)
wrong_words## # A tibble: 4,617 x 6
## title chapter term count .topic consensus
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Great Expectations 38 brother 2 1 Pride and Prejudice
## 2 Great Expectations 22 brother 4 1 Pride and Prejudice
## 3 Great Expectations 23 miss 2 1 Pride and Prejudice
## 4 Great Expectations 22 miss 23 1 Pride and Prejudice
## 5 Twenty Thousand Lea… 8 miss 1 1 Pride and Prejudice
## 6 Great Expectations 31 miss 1 1 Pride and Prejudice
## 7 Great Expectations 5 sergea… 37 1 Pride and Prejudice
## 8 Great Expectations 46 captain 1 2 Twenty Thousand Leag…
## 9 Great Expectations 32 captain 1 2 Twenty Thousand Leag…
## 10 The War of the Worl… 17 captain 5 2 Twenty Thousand Leag…
## # ... with 4,607 more rowswrong_words %>%
count(title, consensus, term, wt = count) %>%
ungroup() %>%
arrange(desc(n))## # A tibble: 3,551 x 4
## title consensus term n
## <chr> <chr> <chr> <dbl>
## 1 Great Expectations Pride and Prejudice love 44
## 2 Great Expectations Pride and Prejudice sergeant 37
## 3 Great Expectations Pride and Prejudice lady 32
## 4 Great Expectations Pride and Prejudice miss 26
## 5 Great Expectations The War of the Worlds boat 25
## 6 Great Expectations The War of the Worlds tide 20
## 7 Great Expectations The War of the Worlds water 20
## 8 Great Expectations Pride and Prejudice father 19
## 9 Great Expectations Pride and Prejudice baby 18
## 10 Great Expectations Pride and Prejudice flopson 18
## # ... with 3,541 more rows“Great Expectations” kiabındaki bazı kelimelerin sıklıkla “Pride and Prejudice” veya “The War of the Worlds” kitabına atandığını görebiliriz. “love” ve “lady” gibi kelimeler “Pride and Prejudice” kitabında daha yaygın olduğu için atanmıştır.
Öte yandan yanlış bir şekilde sınıflandırılmış kelimeler de olabilir. Örneğin, “flopson” kelimesi “Pride and Prejudice” kümesine atanmış olmasına rağmen “Great Expectations” kitabında yer aldığını teyit edebiliriz.
word_counts %>%
filter(word == "flopson")## # A tibble: 3 x 3
## document word n
## <chr> <chr> <int>
## 1 Great Expectations_22 flopson 10
## 2 Great Expectations_23 flopson 7
## 3 Great Expectations_33 flopson 16.3. Özet
Bu bölümde, bir dizi belgeyi karakterize eden kelime kümelerini bulmak için konu modellemesi – topic modelling konusunu anlattık. tidy() eylemi ile dplyr ve ggplot2 kütüphanelerini kullanarak modelleri nasıl keşfedeceğimizi ve anlayacağımızı öğrendik. Model keşfi için LDA düzenli veri formatı yaklaşımının avantajlarından biridir. Farklı çıktı biçimlerinin zorlukları düzenleme fonksionları ile giderilir ve bir takım araçları kullanarak model sonuçlarını keşfedebiliriz. Özellikle konu modellemesinin, kitapların her bir bölümünü diğer kitaplardan ayırabildiğini ve modelin yanlış bir şekilde atadığı kelimeleri ve bölümleri tespit ettiği başarılı bir yöntem olduğunu görüyoruz.
Mutlu Son
Çok uzun bir yazı ile R’da metin madenciliği uygulamalarının nasıl yapıldığını öğrenmiş olduk. Ayrıca, tidytext kütüphanesinin diğer kütüphaneler ile birlikte kullanımının işlevselliğini gördük.
Veri Bilimi maceramızda yeni bir şeyler öğrendiğimize göre, mutlu bir şekilde metinleri analiz etmeye başlayabilirsiniz.