

![]()
Her verinin bir hikayesi vardır. Bu hikayeyi en doğru şekilde aktarabilmek için veri işleme süreçlerimizin iyi bir şekilde birbirini takip etmesi gerekir.
Hadley Wickham’ın R for Data Science kitabındaki veri işleme süreci şeması hikayeyi nasıl anlatacağımızı güzel bir şekilde özetlemiş.
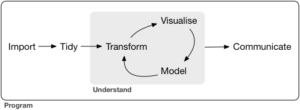
Temel olarak amacımız veri seti içerisindeki detayları ortaya çıkarmak ve genel resmi görmeye çalışmaktır. Buradan yola çıkarak değişkenlerin anlamlılığı, birbirleri ile olan ilişkisi, özellik seçimi gibi konuları en doğru şekilde yapabilmektir. Bu da yapacağımız analizler ve modellerin doğruluk paylarını arttıracaktır.
Bu çalışma ggplot2 cheatsheet’i ve R for Data Science kitabından derlenerek ortaya çıkmıştır.
R’da veri görselleştirme yapmak için ggplot2 harika bir kütüphanedir. Pokemonlarımızın en değerlilerinden biridir.
Gotta catch ’em all!
# Veri görselleştirme kütüphanesi
library(ggplot2)- Veri görselleştirmek için nelere ihtiyacımız vardır ?
- Veri seti – data
- Verinin estetik özellikleri – aes
- Grafik çeşidi – geom
Temel olarak bu üç maddeyi bilmemiz başlangıç için yeterlidir. Bu üç madde ile basit grafikler çizdirebiliriz. Ayrıca bu maddelere küçük eklemeler yaparak harika grafikler ortaya çıkartabilirsiniz.
ggplot(data = ) + (mapping = aes())
Estetik
Aes yani estetik dediğimiz şey değişkenleri daha iyi anlayabilmemiz ve bulguları ortaya çıkarmamız için yaptığımız özellik eklemeleri diyebiliriz. Görsellerin rengini, boyutunu, şeklini, etiketlerini , transparanlığını ve daha bir sürü argümanları ekleyebildiğimiz kısımdır. Yalnız bu özelliklerin çalışma prensibi kesikli veya sürekli veriye göre değişmektedir. Bu özellikleri kullanırken ne anlama geldiklerini bilmeliyiz. Ayrıca geom konusunda daha detaylı anlatacağız fakat yeri gelmişken burada da biraz bahsedelim. Değişken sayısı, kesikli ve sürekli veri de çıkartmak istediğimiz grafik tipini de belirlemektedir.
- color : Verinin rengini ayarlar.
Saçılım grafiğine color argümanını eklemeseydik default halde siyah noktalar çıkacaktı. Biz verinin rengini değiştirmek istediğimizde aes’in dışına yazmamız gerekir.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")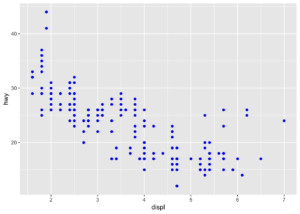
Yukarıda anlattığımıza göre renk argümanını da estetiğin içine yazmamız gerekirdi ama dışarısına yazdık. İçerisine yazınca ne olacak görelim.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = "blue"))
Verinin rengi pembe oldu. Buradaki sorun nedir ?
Renk argümanı ile eğer grafiğin rengi değiştirilecek ise estetiğin dışına yazılmalı. Eğer bir değişken ile kırılıma bakılacak ise renk argümanı estetiğin içinde bir değişken ile birlikte yazılmalıdır.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class))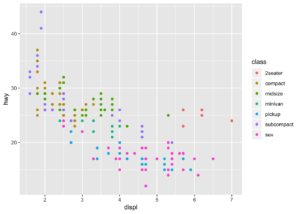
- size : Boyutlandırma işlemidir. Kategorik veriler için tercih edilmez. Alfabetik sıraya göre boyutlandırma işlemi yapar. Sürekli veriler için kullanılmalıdır. Aşağıdaki örneğin de bunun ispatı olarak düşünebiliriz.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, size = class))## Warning: Using size for a discrete variable is not advised.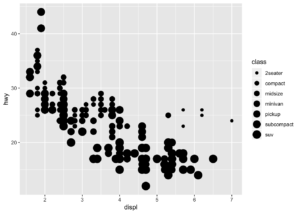
- alpha : Şeffaflaştırma işlemidir. Yine kategorik veriler için tercih edilmez. Ancak yapmak istediğiniz probleme göre değişir.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, alpha = class))## Warning: Using alpha for a discrete variable is not advised.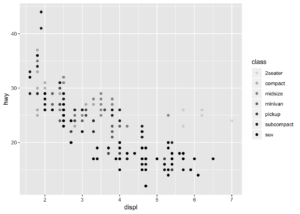
- shape : Verileri farklı şekillendirme işlemidir. Burada dikkat etmemiz gereken şey ise shape maksimum altı kesikli gözlem için kullanılabilir. Örnekte de görüldüğü gibi suv sınıfındaki arabalar gözükmemektedir.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, shape = class))## Warning: The shape palette can deal with a maximum of 6 discrete values
## because more than 6 becomes difficult to discriminate; you have 7.
## Consider specifying shapes manually if you must have them.## Warning: Removed 62 rows containing missing values (geom_point).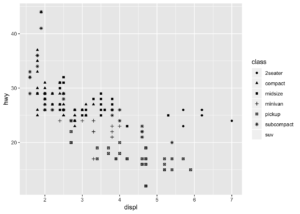
NOT: Estetik özellikler kesikli ve sürekli değişkenlere göre farklılık göstermektedir. Bu yüzden kullanacağımız argümanları nerede nasıl kullanacağımızı bilmemiz bizim için yararlı olacaktır.
Ayrıca bu şekilde de kod yazımı yapabiliriz. Veriyi ggplot içerisinde tanımlayıp, geom içerisinde estetik özellikleri yazarsak aynı çıktıyı alabiliriz.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))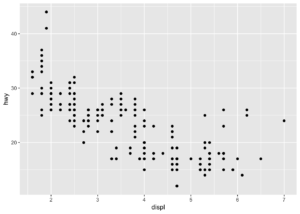
Facet
Kategorik değişkenler için yararlı iki fonksiyonlarımız bulunmakta, facet_wrap() ve facet_grid() fonksiyonları. Seçtiğimiz kategorik değişkenleri alt kümelerine ayırıp kendi içlerinde karşılaştırma yapabilmemizi sağlar.
- facet_wrap() fonksiyonu tek bir değişkene göre parçalama yapmak ve karşılaştırmak için kullanışlıdır.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 2)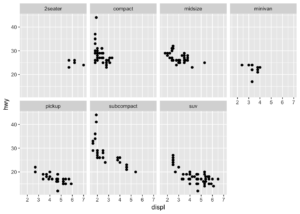
- facet_grid() fonksiyonu iki değişken göre parçalama yapmak ve karşılaştırmak için kullanışlıdır.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)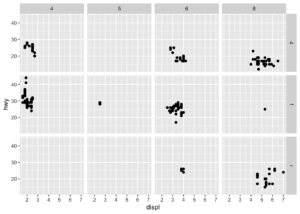
Satır veya sütun boyutunda olmamayı tercih edersek “.” kullanmamız gerekir.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(. ~ cyl)
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(cyl~.)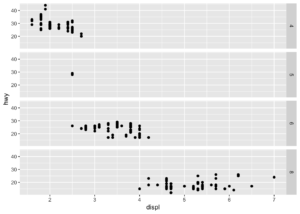
Geomlar
Geomlar aracılığı ile farklı türde grafikler çıkartmamız, hatta farklı geomları birleştirerek daha anlamlı grafikler elde edebilmemiz mümkündür. Örneğin bir saçılım grafiği ile eğri grafiğinin bir arada olduğunu düşünelim. Regresyondan da hatırlanacağı gibi noktalar arasından en uygun doğrunun-eğrinin geçmesini istiyorsak bu iki geomu kullanabiliriz.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))+
geom_smooth(mapping = aes(x = displ, y = hwy))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'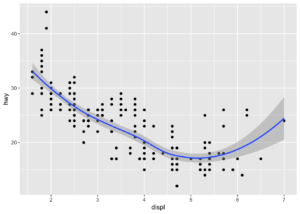
Eğrinin etrafında eğriyi takip eden grimsi yapı güven aralığıdır. geom_smooth’un içerisine aes’in dışına se = FALSE yazılır ise güven aralığı gözükmeyecektir.
geom_smooth() ile kategorik değişkene göre kırılım yapabiliriz.
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = drv))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'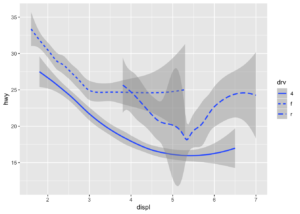
Daha da detaylandırmak istersek, saçılım grafiğinde drv kategorik değişkenini renklere göre ayırdıktan sonra, her bir kategorinin eğrisini de renklere göre ayırdık.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = drv))+
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = drv, color = drv))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'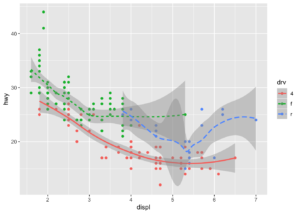
ggplot üzerinde zaman geçirdikçe daha iyi görseller elde etme ve daha fazla geomları birlikte kullanma şansı yakalayacaksınız.
ggplot2, 30’un üzerinde geom’a sahiptir. ggplot2’in ek paketleri ile farklı görseller yapma fırsatı bulabilirsiniz. https://www.ggplot2-exts.org
Şu ana kadar yaptığımız görsellerin ne anlama geldiğini konuşmadık. Alttaki kod üzerinden neye baktığımızı anlayalım.
library(dplyr)ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth(data = filter(mpg, class == "subcompact"), se = FALSE)## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
mpg veri seti arabaların özellikleri ile ilgili olduğunu biliyoruz. Burada displ ve hwy değişkenlerinin temel olarak karşılaştırılması ve özelleştirilmesini görüyoruz.
displ değişkeni arabanın motor hacmi, hwy değişkeni ise yakıt verimliliğini temsil eden iki değişkendir. Buradan şu soruyu sorabiliriz, büyük motorlu araçlar, küçük motorlu araçlardan daha fazla yakıt tüketiyor mu ?
Saçılım grafiğine baktığımız zaman bu sorunun cevabını verebiliriz.
Renklere göre kategorize ettiğimizde ise yukarıdaki sorunun araba sınıflarına göre cevabını buluruz.
Eğriye baktığımız zaman ise yukarıdaki soruyu subcompact sınıfındaki arabalara göre cevaplamış oluruz.
Stats – İstatistiksel Dönüşümler
İstatistiksel dönüşümler için çubuk grafik iyi bir örnektir.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut))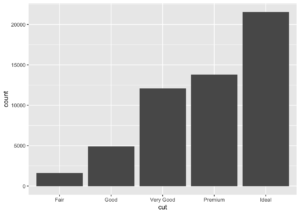
Saçılım grafiği gibi birçok grafik veri setinin ham değerlerini çizer. Çubuk grafikler gibi diğer grafikler, plot için yeni değerleri hesaplar.
Bir grafiğin yeni değerleri hesaplanırken kullanılan algoritmaya istatistiksel dönüşüm yani stat denir . Aşağıdaki şekil bu işlemin nasıl çalıştığını açıklar.
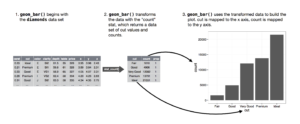
stat argümanlarının varsayılan değerlerini inceleyerek bir geom’un hangi stat’ı kullandığını öğrenebilirsiniz. Örnek olarak geom_bar() ile stat_count() birbiri ile aynı işleve sahiptir.
Geomları ve statları genellikle birbirinin yerine kullanabilirsiniz. Örneğin, önceki grafiği düşünürsek geom_bar() yerine stat_count() kullandığınızda aynı grafiği elde edersiniz.
ggplot(data = diamonds) +
stat_count(mapping = aes(x = cut))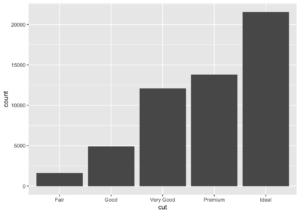
Pozisyon Ayarlamaları – Position Adjustments
color ve fill argümanları estetik özellikler için en kullanışlı olanlardan ikisidir.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, colour = cut))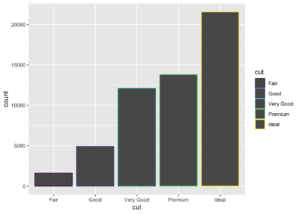
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = cut))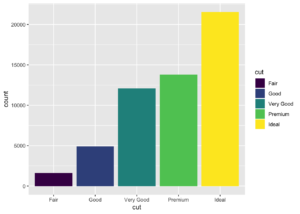
fill estetiğini başka bir değişkene eşlerseniz, örneğin bu değişkenimiz clarity olsun çubuklar otomatik olarak yığılım gösterir ve her bir renkli dikdörtgen elmasların kesimini (cut değişkeni) temsil eder.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity))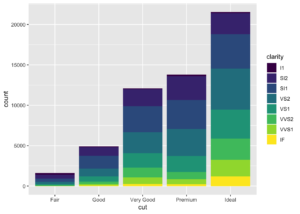
Yığılım, pozisyon ayarlaması yapmadan ile otomatik gerçekleşir. Eğer bir yığın grafiği istemiyorsanız diğer seçenekler kullanılabilir. Bu seçeneklerimiz ise position argümanı içerisinde “identity”, “dodge” veya “fill” kullanılabilir.
- position = “identity”
Her bir nesneyi tam olarak grafik bağlamında düştüğü yere yerleştirir. “identity” çubuk grafik için çok kullanışlı değildir, çünkü bunlar üst üste geleceğinden işe yaramaz bir grafik elde ederiz. Üst üste binmeyi yani yığılımı görmek için ya alpha argümanına küçük bir değer vererek ya da tamamen şeffaflaştırarak daha anlamlı bir grafik ortaya çıkartabiliriz.
ggplot(data = diamonds, mapping = aes(x = cut, fill = clarity)) +
geom_bar(position = "identity")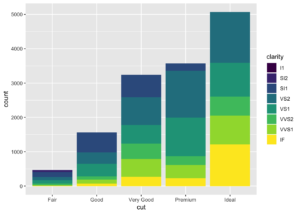
alpha = 1/5 olduğu durum
ggplot(data = diamonds, mapping = aes(x = cut, fill = clarity)) +
geom_bar(alpha = 1/5, position = "identity")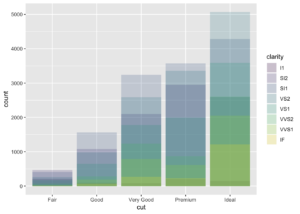
veya fill = NA olduğu durum
ggplot(data = diamonds, mapping = aes(x = cut, colour = clarity)) +
geom_bar(fill = NA, position = "identity")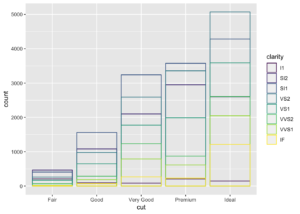
identity iki boyutlu grafikler için daha kullanışlıdır.
- position = “fill”
Yığılım gibi çalışır, ancak her kümeden çubukları aynı yükseklikte yapar. Bu da gruplar arasındaki oranların karşılaştırılmasını kolaylaştırır.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity), position = "fill")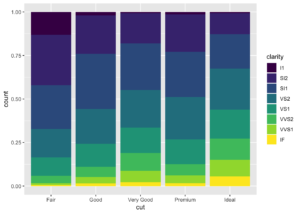
- position = “dodge”
Üst üste yığılım yerine nesneler birbirlerinin yanına gelir. Bu da bir aynı özellikte olan grupların karşılaştırmasını kolaylaştırır.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity), position = "dodge")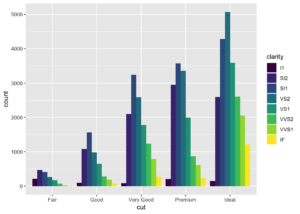
- position = “jitter”
Çubuk grafikler için kullanışlı olmayan ancak saçılım grafiği için çok yararlıdır. İlk grafiğimizdeki mpg veri setinde 234 gözlem olmasına rağmen, plotta sadece 126 gözlem görüntüledik.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))
Bunun nedeni hwy ve displ değişkenlerinindeki her bir gözlemin yuvarlanması ve yuvarlanan gözlemler de birbiri üzerine düştüğü için gözlemlerin görüntülenmesi daha az olmaktadır. Buna da overplotting denir. Yani veri kütlelerinin nerede olduğunu görmemiz zorlaşmaktadır. “jitter” ayarlaması ile bu sorunu ortadan kaldırabiliriz. position = “jitter” her noktaya az bir miktarda gürültü ekler.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), position = "jitter")
Rastgelelik eklemek, grafiğinizi küçük ölçeklerde daha az hassas hale getirirken, grafiğinizi büyük ölçeklerde daha da açığa çıkaracaktır.
Koordinat Sistemleri
Kısaca bahsetmek gerekirse x ve y düzleminde ayarlamalar yapmamıza yardımcı olur.
- coord_flip() x ve y eksenlerini değiştirir.
ggplot(data = mpg, mapping = aes(x = class, y = hwy)) +
geom_boxplot()
ggplot(data = mpg, mapping = aes(x = class, y = hwy)) +
geom_boxplot() +
coord_flip()
- coord_polar() Kutupsal koordinatları kullanır. Kutupsal koordinatlar, bir çubuk grafik ve bir Coxcomb şeması arasındaki bağlantı ile görselleştirme sağlar.
Çubuk grafik
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = cut), show.legend = FALSE, width = 1) +
theme(aspect.ratio = 1) +
labs(x = NULL, y = NULL)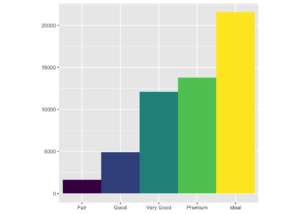
ve kutupsal gösterimi
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = cut), show.legend = FALSE, width = 1) +
theme(aspect.ratio = 1) +
labs(x = NULL, y = NULL)+
coord_flip()+
coord_polar()## Coordinate system already present. Adding new coordinate system, which will replace the existing one.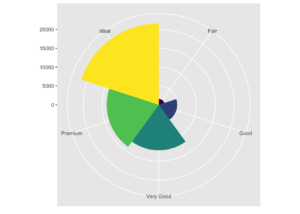
Buraya ek olarak eğer pasta grafik yapmak isterseniz aşağıdaki kodu kullanabilirsiniz.
ggplot(diamonds,aes(x = "", fill=clarity)) +
geom_bar(width = 1) +
coord_polar (theta="y")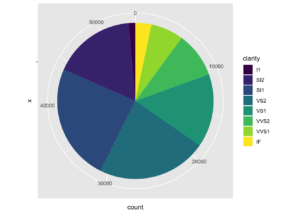
Etiketler
x ve y değişkenini anlamlandırmak, grafiğinize başlık ve alt başlık eklemek isterseniz labs fonksiyonunu kullanabilirsiniz.
ggplot(diamonds,aes(x = cut, fill = cut)) +
geom_bar()+
labs( x = "Elmasların kesim türü",
y = "Frekanslar",
title = "Kesimlerine göre elmas türleri",
caption = "Kaynak: Diamonds veri seti")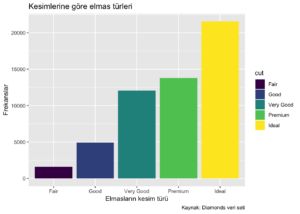
Lejant
Legend yani Lejantlar plotun sağ tarafında kategorileri gösterdiği kısımdır. Elimizde farklı kategoriler var ise lejant gösterimi yapmamız gerekir.
ggplot(diamonds,aes(cut, fill=cut))+
geom_bar()+
coord_polar(theta = "y")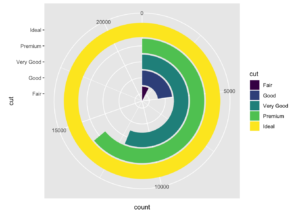
Eğer lejantları kaldırmak isterseniz show.legend = FALSE yazabilirsiniz.
ggplot(diamonds,aes(cut, fill=cut))+
geom_bar(show.legend = FALSE)+
coord_polar(theta = "y")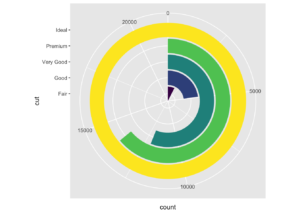
Artık görselleştirme için nelere ihtiyacımız olduğunu, veri tiplerinin görselleştirmedeki özelliklerini, argümanlar arasındaki farklılıkları, küçük eklemeler ile görseli daha güzel hale getirebileceğimizi öğrendik.
En mükemmel analizleri, tahminleri yapsak bile elde ettiğimiz sonuçları karşı tarafa aktaramadığımız sürece yaptığımız işin bir önemi yok. Bu aktarımı da en iyi görselleştirme aracı ile karşı tarafa aktarmalıyız. Unutmayın sayısal bir çıktıdan çok, görsel bir çıktı her zaman daha akılda kalıcı olacaktır.
Kaynak: https://r4ds.had.co.nz/data-visualisation.html