

![]()
Bu yazımızda veri ambarı dünyasında boyut (dimension) tablolarında sıklıkla kullanılan bir güncelleme yöntemi olan slowly changing dimension örneğini Apache Spark ve Delta Lake ile yapacağız. Veri ambarında gerçekleşen işlemler ve bu işlemlere ait tanım bilgileri farklı tablolarda tutulur. Hepimiz e-ticaret sitelerinden alışveriş yapıyoruz. Örneğin bir telefon kılıfı aldık. Bu telefon kılıfı bir üründür ve tanımı (özellikleri, boyutu, ağılığı, görselleri, menşei vb.) bir yerde, bir kere saklanır. Bu tablolara boyut (dimension) tablosu denir. Ancak bu kılıf her satıldığında ayrı bir tabloda farklı bir kayıt oluşur. Binlerce müşteri, yüzlerce farklı yerde ve zamanda, bir sürü sipariş verir. İşte tüm bu siparişlerin saklandığı tablo ise fact tablosudur. Fact tabloları genelde güncellenmez, çünkü meydana gelen bir olayla ilgilidir. Hatta iptaller bile yeni kayıt olarak eklenir. Ancak boyut tabloları zamanla değişebilir. Örneğin müşteri bilgilerinin tutulduğu bir boyut tablosunda müşterinin bilgileri (adres gibi) zamanla değişebilir. İşte biz bu değişiklikleri güncellemek ve eski bilgileri (adresler gibi) kaybetmek istemiyorsak Slowly Changing Dimension Type2 yöntemini kullanırız. Type2 haricinde ihtiyaca göre farklı bir kaç yöntem daha var. Konumuz bu olmadığı için onlara burada değinmeyeceğim. Dileyen detaylı bilgiyi Kimball‘ın kitabından bulabilir.
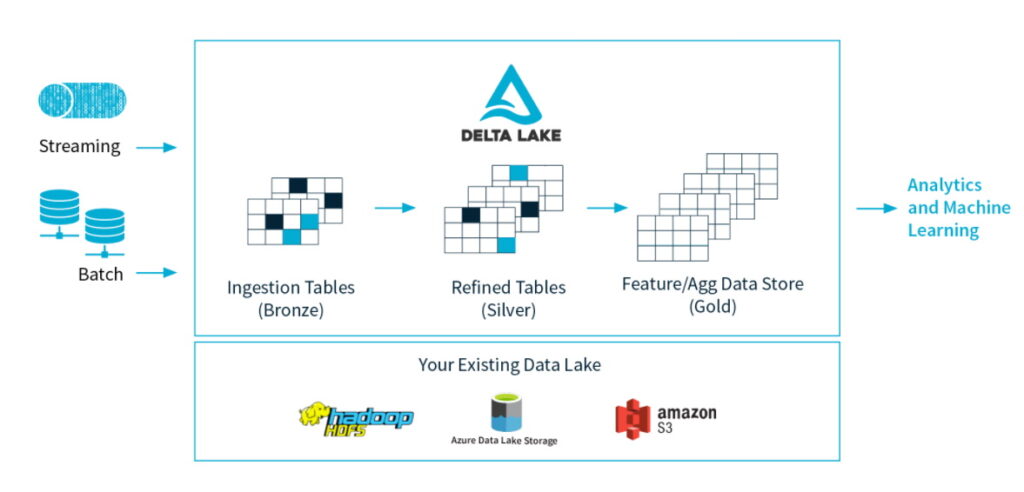
Peki yıllardır bilinen ve sektörde yaygın olarak uygulanan bir şeyi ne diye burada tekrardan yazıyoruz? Sebebi şu; yıllardır yapılan bu iş hep ilişkisel veri tabanlarında gerçekleşiyordu. Son 10-20 yılda veri miktarının aşırı derecede artmasıyla beraber büyük veri ortamları, veri ambarı ve analitik ihtiyaçları karşılamak amacıyla kullanılmaya başlandı (data lake). Ancak bu sefer ilişkisel veri tabanlarının sağladığı bazı standart ve kolaylıklar kayboldu. Örneğin ACID, update ve delete zorluğu ya da imkansızlığı. Yakın zamanda hem ilişkisel veri tabanlarının alıkşanlık ve standartlarını koruyan hem de büyük veri ortamlarının rahatlığını sunan yeni araçlar ortaya çıkmaya başladı ve bu tür araçlara çatı kavram olarak lakehouse denildi. Delta Lake ise bu “lakehouse” ların en iddialı adaylarından. Daha iyi anlamak için şöyle bir benzetme yapabiliriz: veritabanı -> postgresql ilişkisi ne ise lakehouse -> delta lake ilişkisi de aynıdır. İşte eski ve bilinen bir konuyu kaleme almamızın sebebi bunun Hadoop + Spark (Pyspark) + Delta Lake örneğini sizlerle paylaşmak. Aşağıda Şekil-1’de Delta Lake’in kendi sayfasından alınmış ve sade olarak veri akışındaki yeri ve katkısını görmekteyiz.
Ortam bilgileri
Spark: 3.0.0
Delta Lake: 0.7.0
Java: 1.8.0
Hadoop: 3.1.2
İşletim Sistemi: CentOS7
Python: 3.6
IDE: Jupyter Notebook
Senaryo
Örneğimizi anlaşılır kılmak için bir senaryoya dayandıralım. Büyük bir beyaz eşya firması müşterilerinin ne zaman ve nerede yaşadıklarını, ne kadar yer değiştirdiklerini ve aktif üyeliklerinin devam edip etmediğini takip etmek istiyor. Şirketin uygulamasında müşterilerin adres güncellemeleri alınıyor. Her bir yeni müşteri girişinde veya mevcut müşterilerin adres değişikliğinde veri ambarındaki müşteri (customers) boyut tablosu güncelleniyor. Şirket müşterilerin ne zaman, nerede yaşadıklarını ve ne sıklıkla adres değiştirdiklerini, satılan eşyaların nereden nereye taşındığını vb. bilmek istediği için eski adres kayıtlarını da tutmak istiyor. Müşteri boyut tablosunun delta table olarak kayıtlı olduğunu varsayıyoruz. Ancak biz çalışmanın tekrarlanabilmesi için bu tabloyu birazdan elle yaratacağız. Senaryo ile doğrudan ilgisi yok ancak fikir vermesi açısından satışlarla ilgili veri ambarı örnek veri modellemesi aşağıda Şekil-2’de bulunmaktadır.

Spark Session
import findspark
findspark.init("/opt/manual/spark")
spark = (SparkSession.builder
.appName("Delta Lake SCD Type2")
.master("yarn")
.config("spark.sql.shuffle.partition", 4)
.config("spark.jars.packages", "io.delta:delta-core_2.12:0.7.0")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate())findspark ile jupyter’in spark’ı bulmasını sağlıyoruz.
“spark.sql.shuffle.partition”, 4 : Küçük veri ile küçük bir makinede çalıştığımız için bu ayarı 4 yaptık. Varsayılan 200.
“spark.jars.packages”: Delta Lake’i burada dahil ediyoruz.
“spark.sql.extensions”: SQL optimizasyonları için 3. parti geliştiricilere açılan kapı. Burada delta lake SparkSession extension seçiyoruz.
“spark.sql.catalog.spark_catalog”: Delta Lake üzerinde DDL kullanmamıza olanak sağlıyor.
Spark Session’ı delta kütüphaneleri ile açtıktan sonra artık bunları import edebiliriz.
from delta.tables import *
Create a spark dataframe
Burada elle oluşturduğumuz dataframe aslında hali hazırda müşteri (customers) boyut tablosunu temsil ediyor.
customers = spark.createDataFrame([(10001504, "Hasan Şahintepesi", "Çankırı", "Eldivan", True, "1992-09-01", None),
(10001505, "Tuncay Çadırcı", "Ankara", "Keçiören", True, "1992-10-12", None),
(10001506, "Melahat Bakır", "İstanbul", "Beykoz", True, "1992-08-26", None),
(10001526, "Sultan Balcı", "Muğla", "Bodrum", True, "1992-09-26", None),
(10001530, "Dudu Karagölet", "Yozgat", "Sorgun", False, "1992-08-11", "1993-08-25"),
(10001518, "Burcu Vataneri", "Kırşehir", "Mucur", False, "1992-08-22", "1993-06-21")],
["Id", "personName", "state", "province", "still_here", "join_date", "leave_date"])
customers.show()
+--------+-----------------+--------+--------+----------+----------+----------+
| Id| personName| state|province|still_here| join_date|leave_date|
+--------+-----------------+--------+--------+----------+----------+----------+
|10001504|Hasan Şahintepesi| Çankırı| Eldivan| true|1992-09-01| null|
|10001505| Tuncay Çadırcı| Ankara|Keçiören| true|1992-10-12| null|
|10001506| Melahat Bakır|İstanbul| Beykoz| true|1992-08-26| null|
|10001526| Sultan Balcı| Muğla| Bodrum| true|1992-09-26| null|
|10001530| Dudu Karagölet| Yozgat| Sorgun| false|1992-08-11|1993-08-25|
|10001518| Burcu Vataneri|Kırşehir| Mucur| false|1992-08-22|1993-06-21|
+--------+-----------------+--------+--------+----------+----------+----------+
Mevcutta customers boyut tablomuzda olan kayıtlar yukarıdaki gibidir. leave_date null olanlar halen müşteri statüsünü devam ettirmektedir (aktif üye), leave_date null olmayanlar ise o tarihte bulunduğu yerden ayrıldı veya üyeliği sonlandı anlamına gelmektedir.
Mevcut Müşterileri DeltaTable Olarak Yazma
Burada çalışmanın tekrarlanabilmesi açısından yukarıda elle oluşturduğumuz spark dataframe’i sanki eskiden beri boyut tablosu olarak delta lake içinde varmış gibi kaydedelim.
deltaPath = "hdfs://localhost:9000/user/train/customers_delta"
customers.write \
.mode("overwrite") \
.format("delta") \
.save(deltaPath)Yeni Kayıtlar
Aşağıdaki dataframe yeni kayıtları temsil etsin. Yani bazı yeni üyelikler var ve mevcut üyelerden bazıları da yer değiştirmiş.
customers_new = spark.createDataFrame([(10001417, "Tuncay Kavcı", "Kütahya", "Merkez", "1994-09-01"),
(10001418, "Tülay İçtiyar", "Ankara", "Sincan", "1994-09-01"),
(10004055, "Arzu Taksici", "Çankırı", "Merkez", "1994-11-07"),
(10001505, "Tuncay Çadırcı", "İstanbul", "Küçükyalı", "1995-01-09"),
(10001526, "Sultan Balcı", "İstanbul", "Tuzla", "1995-01-09")],
["Id", "personName", "state", "province", "join_date"])
customers_new.show()
+--------+--------------+--------+---------+----------+
| Id| personName| state| province| join_date|
+--------+--------------+--------+---------+----------+
|10001417| Tuncay Kavcı| Kütahya| Merkez|1994-09-01|
|10001418| Tülay İçtiyar| Ankara| Sincan|1994-09-01|
|10004055| Arzu Taksici| Çankırı| Merkez|1994-11-07|
|10001505|Tuncay Çadırcı|İstanbul|Küçükyalı|1995-01-09|
|10001526| Sultan Balcı|İstanbul| Tuzla|1995-01-09|
+--------+--------------+--------+---------+----------+Yukarıda Tuncay Çadırcı ve Sultan Balcı’nın yerlerinin değiştiğini görüyoruz (Çünkü bu iki kayıt boyut tablosunda zaten mevcut). Diğer kayıtlar ise daha önceden boyut tablosunda mevcut değil. Burada type2 yöntemine göre Tuncay Çadırcı ve Sultan Balcı’nın eski kayıtlarını koruyarak yenilerini eklemem ve join_date, leave_date ve still_here sütunlarını güncellemem lazım. Bu işi aşağıda belirttiğim 4 adımda gerçekleştiriyoruz.
Adım-1: Yeni Kayıtlarla Boyut Tablosundaki Mevcut Kayıtları Karşılaştırma
Öncelikle yeni gelen kayıtları mevcut boyut tablosundakiler ile kontrol edip güncellenerek mi eklenecek yoksa doğrudan mı eklenecek kontrol etmem lazım. Bu adımda güncellenerek eklenecek kayıtları stagedPart1 adında bir dataframe’de tutuyorum.
stagedPart1 = customers_new.alias("updates") \
.join(customers_delta.toDF().alias("customers"), "Id") \
.where("customers.still_here = true AND (updates.state <> customers.state OR updates.province <> customers.province)") \
.selectExpr("NULL as mergeKey", "updates.*")
stagedPart1.show()
+--------+--------+--------------+--------+---------+----------+
|mergeKey| Id| personName| state| province| join_date|
+--------+--------+--------------+--------+---------+----------+
| null|10001505|Tuncay Çadırcı|İstanbul|Küçükyalı|1995-01-09|
| null|10001526| Sultan Balcı|İstanbul| Tuzla|1995-01-09|
+--------+--------+--------------+--------+---------+----------+Birleşme sonrası bu kayıtların ilave olmasını istediğimiz için mergekey’lerini null bıraktık.
Adım-2: Mevcut Kayıtlara MergeKey Ekleme
Bu kayıtlar her halükarda doğrudan eklenecek.
stagedPart2 = customers_new.selectExpr("Id as merge_key", *customers_new.columns)
stagedPart2.show()
+---------+--------+--------------+--------+---------+----------+
|merge_key| Id| personName| state| province| join_date|
+---------+--------+--------------+--------+---------+----------+
| 10001417|10001417| Tuncay Kavcı| Kütahya| Merkez|1994-09-01|
| 10001418|10001418| Tülay İçtiyar| Ankara| Sincan|1994-09-01|
| 10004055|10004055| Arzu Taksici| Çankırı| Merkez|1994-11-07|
| 10001505|10001505|Tuncay Çadırcı|İstanbul|Küçükyalı|1995-01-09|
| 10001526|10001526| Sultan Balcı|İstanbul| Tuzla|1995-01-09|
+---------+--------+--------------+--------+---------+----------+Adım-3: Adım-1 ve Adım-2’deki Kayıtların Birbirine Eklenmesi (union)
Adım-1’de güncellenerek eklenecek kayıtlarla Adım-2’deki doğrudan eklenecek kayıtları birleştiriyorum. Böylelikle eskilerin silinmemesi, yenilerin eklenmesi mümkün olacak.
stagedUpdates = stagedPart1.union(stagedPart2) stagedUpdates.show() +--------+--------+--------------+--------+---------+----------+ |mergeKey| Id| personName| state| province| join_date| +--------+--------+--------------+--------+---------+----------+ | null|10001505|Tuncay Çadırcı|İstanbul|Küçükyalı|1995-01-09| | null|10001526| Sultan Balcı|İstanbul| Tuzla|1995-01-09| |10001417|10001417| Tuncay Kavcı| Kütahya| Merkez|1994-09-01| |10001418|10001418| Tülay İçtiyar| Ankara| Sincan|1994-09-01| |10004055|10004055| Arzu Taksici| Çankırı| Merkez|1994-11-07| |10001505|10001505|Tuncay Çadırcı|İstanbul|Küçükyalı|1995-01-09| |10001526|10001526| Sultan Balcı|İstanbul| Tuzla|1995-01-09| +--------+--------+--------------+--------+---------+----------+
Adım-4: Boyut Tablosu (DeltaTable) Üzerinde Değişikliklerin İşlenmesi
Adım-3’te elde ettiğimiz stagedUpdates dataframe’i mevcut boyut tablosuna (customers_delta) değişiklikleri/güncellemeleri yaparak ekleyebiliriz.
customers_delta \
.alias("customers") \
.merge(stagedUpdates.alias("staged_updates"), "customers.Id = mergeKey") \
.whenMatchedUpdate(condition="customers.still_here = true AND (staged_updates.state <> customers.state OR staged_updates.province <> customers.province)", \
set={"still_here": "false", "leave_date": "staged_updates.join_date"}) \
.whenNotMatchedInsert(values={
"Id": "staged_updates.Id",
"personName": "staged_updates.personName",
"state": "staged_updates.state",
"province": "staged_updates.province",
"still_here": "true",
"join_date": "staged_updates.join_date",
"leave_date": "null"}) \
.execute()Sonuç:
customers_delta.toDF().orderBy(F.desc("personName")).show()
+--------+-----------------+--------+---------+----------+----------+----------+
| Id| personName| state| province|still_here| join_date|leave_date|
+--------+-----------------+--------+---------+----------+----------+----------+
|10001418| Tülay İçtiyar| Ankara| Sincan| true|1994-09-01| null|
|10001505| Tuncay Çadırcı|İstanbul|Küçükyalı| true|1995-01-09| null|
|10001505| Tuncay Çadırcı| Ankara| Keçiören| false|1992-10-12|1995-01-09|
|10001417| Tuncay Kavcı| Kütahya| Merkez| true|1994-09-01| null|
|10001526| Sultan Balcı|İstanbul| Tuzla| true|1995-01-09| null|
|10001526| Sultan Balcı| Muğla| Bodrum| false|1992-09-26|1995-01-09|
|10001506| Melahat Bakır|İstanbul| Beykoz| true|1992-08-26| null|
|10001504|Hasan Şahintepesi| Çankırı| Eldivan| true|1992-09-01| null|
|10001530| Dudu Karagölet| Yozgat| Sorgun| false|1992-08-11|1993-08-25|
|10001518| Burcu Vataneri|Kırşehir| Mucur| false|1992-08-22|1993-06-21|
|10004055| Arzu Taksici| Çankırı| Merkez| true|1994-11-07| null|
+--------+-----------------+--------+---------+----------+----------+----------+Yukarıda boyut tablosunun son hali görülmektedir. Type2 yöntemine göre eski kayıtların kalması ve güncellenenlerin yeni satır eklenmesi sağlanmıştır (Tuncay Çadırcı ve Sultan Balcı kayıtlarına dikkat).
Bu yazımızda Spark ve Delta lake kullanarak SCD type2 örneği yapmaya çalıştık. Eğer ilişkisel veri tabanlarına sığmıyorsanız, Hadoop Data Lake de tam size uymuyorsa Deltalake’i incelemenizi öneririm.
Başka bir yazıda görüşene dek esen kalın…
Kaynaklar:
- Kapak: Photo by Customerbox on Unsplash
- https://delta.io/
- https://www.researchgate.net/figure/Sales-Dimensional-Model_fig10_314332952
- https://mungingdata.com/delta-lake/type-2-scd-upserts/
- https://datamantips.wordpress.com/2014/01/23/slowly-changing-dimension-nedir/
- Kimball, Ralph, and Margy Ross. The data warehouse toolkit: the complete guide to dimensional modeling. John Wiley & Sons, 2011.