
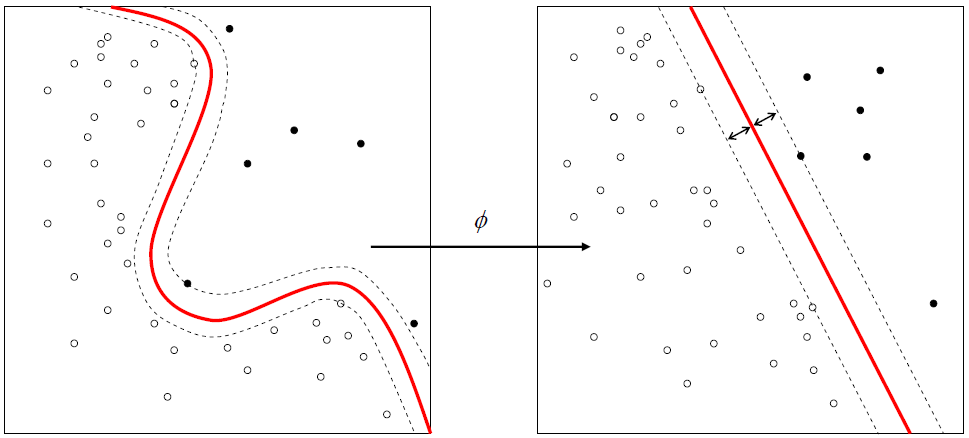
Bu yazıda Sınıflandırma Python ile yaptığımız uygulamanın aynısını R ile yapacağız.
Öncelikle çalışma dizinin ayarlayalım:
setwd('Calisma_dizini')
Veri setini yükleyelim. Veri setini buradan indirebilirsiniz.
dataset = read.csv('SosyalMedyaReklamKampanyası.csv', encoding = 'UTF-8')
Türkçe karakterlerin düzgün okunması için encoding parametresini kullandık. Lazım olan sütunları seçelim.
dataset = dataset[3:5]
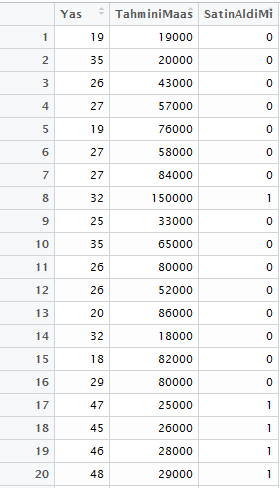
Veri Setini Eğitim ve Test Olarak Ayırmak
Aynı sonuçları almak için random değeri belirlemek için bir sayı belirliyoruz. 123. split fonksiyonu ile hangi kayıtların eğitim hangi kayıtların test grubunda kalacağını damgalıyoruz. Sonra bu damgalara göre ana veri setinden yeni eğitim ve test setlerini oluşturuyoruz.
libraryt(caTools) set.seed(123) split = sample.split(dataset$SatinAldiMi, SplitRatio = 0.75) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)
Yaş ile maaş aynı ölçekte olmadığı için bu nitelikleri normalizasyona tabi tutuyoruz.
training_set[-3] = scale(training_set[-3]) test_set[-3] = scale(test_set[-3])
Modeli eğitelim:
library(e1071) classifier = svm(formula = SatinAldiMi ~ ., data=training_set, type='C-classification', kernel='linear')
Eğittiğimiz modelde test seti ile tahmin setimizi (y_pred) oluşturalım.
y_pred = predict(classifier, newdata = test_set[-3])
Hata matrisini (confusion matrix) oluşturalım:
cm = table(test_set[, 3], y_pred)
y_pred 0 1 0 57 7 1 13 23
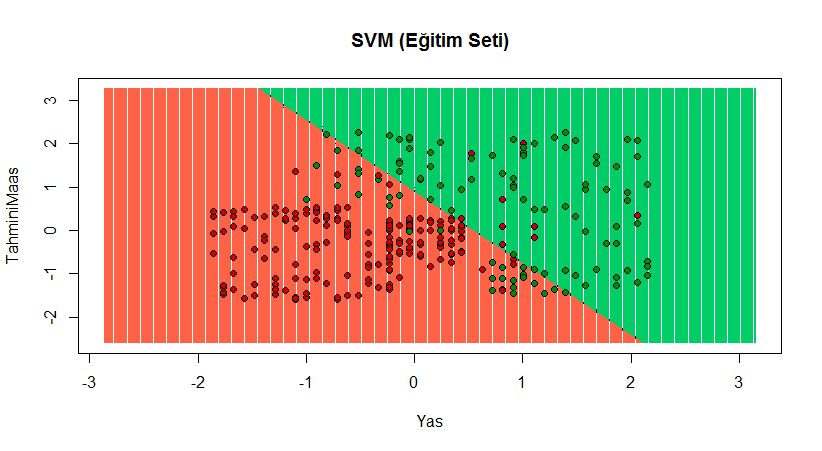
Durum kötü görünüyor. 20 isabetsiz tahmin var. Bir de grafik ile bakalım.
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yas', 'TahminiMaas')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, -3],
main = 'SVM (Eğitim Seti)',
xlab = 'Yas', ylab = 'TahminiMaas',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Test setini de görelim:
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Yas', 'TahminiMaas')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, -3], main = 'SVM (Test seti)',
xlab = 'Yas', ylab = 'TahminiMaas',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))

Grafikte gördüğümüz gibi kırmızı bölgeye taşan yeşil noktalar ile yeşil bölgeye taşan kırmızı noktalar hep başarısız sınıflandırmayı gösteriyor.