

21. yüzyılın en popüler mesleklerinden biri olan veri bilimi; çok kısaca, geçmiş gözlem değerlerine bakarak geleceği tahminleyen, verilerden gerekli modeller kurarak sorunları önceden belirtmeye çalışan, gelecek durumlar hakkında bilgiler sunan, yapay zeka algoritmaları geliştiren ve veri yığınlarından anlamlı bilgiler üreterek eylem planları (şirket stratejileri) hazırlayan kişilerin içinde bulunduğu, büyük otoritelerce “son 10 yılın en seksi” mesleği konumundadır.
Bu yazımda sizlerle bir veri seti ile karşılaştığımızda neler yapmalıyız gibi baştan sona bir eğitim projesi yazmak istedim. Bilindiği üzere çok ilgilisi olan bir meslek grubunda çalışıyorum ve bana sorulan bazı soruları hem yanıtlamak için hem de bir veri bilimci genel taslakla veri ile karşı karşıya kaldığında ne yaptığını gösterip ve elimden geldiğince açıklamaya çalışacağım. Böylece “Hangi Makine Öğreniyor?” ya da “Nasılsa makineler modeli yapıyor, sen niye eğitime gidiyorsun ? Bırak makine gitsin eğitime 😛 “ gibi soruları cevaplayabilmeniz için ilgili ve bu alanda çalışmak isteyen arkadaşlara yardımcı olabileceğimi düşünüyorum. Bu yazının amacı, LightGBM modelini örnek göstererek, karar bazlı bir model kurmaktır.
UYGULAMA
Bu ayki uygulama konum Titanik … Filmin sonunu şimdiden söyleyeyim, gemi batıyor arkadaşlar. Kaggle platformu üzerinden aldığım “ Titanic: Machine Learning From Disaster” veri seti ile çalışmamı gerçekleştireceğim. Bu uygulamayla baştan sonra bir projeyi bitirmiş olacağız. Bu uygulamayı Python üzerinden gerçekleştireceğim ve modelleme aşamasında 2017 yılında Microsoft tarafından çıkarılan ve karar ağaçları mantığı ile çalışan ve XGBoost modellerinden daha optimize edilmiş olan LightGBM modelini kullanarak problemi çözmeye çalışacağım.

Titanik verisi aslında, Titanik gemisindeki yolcuların bilgilerini içeren (yaş, cinsiyet, sorumlu olduğu insan sayısı, yolculuk sınıfı, bileti vs) bir veri setidir. Veri bilimcilerin “Hello World” ‘ u sayılan, “iris” verisi ile beraber bu alanda efsaneleşmiş veri setlerinden biridir. Problemin sonunda da bağımlı değişken (hedef) olarak ise kişinin hayatta kalıp/kalmadığını tahminlememiz istenilen, bir yarışma verisidir. Eğer hala bu veri ile karşılaşmadıysanız lütfen biraz veriyi kurcalayın, muhakkak karşınıza çıkacak, konusu açılacak ya da çok benzer bir problemle uğraşmak zorunda kalacaksınızdır.
Uygulamaya ve kodlarımı paylaşmaya geçmeden önce kısaca yol haritamı sizlere maddeler halinde paylaşmak istiyorum.
Problemi anlamak ve geçmiş çalışmaları inceleyerek insanların bu konuya nasıl yaklaştıklarını öğrenmek
- Veriyi yükledikten sonra, kayıp verileri / uç değerleri / korelasyonları basit düzeyde incelemek
- Kaç tane değişkenim var? Ardından dağılımları nasıl?
- Hangi değişkenler kategorik? Hangi değişkenler numerik?
- Değişkenlerin dağılımını incelemek
- Kategorik kırılımda numerik değişkenleri incelemek
- Belli bir pattern (yapı) varsa bunları belirlemek (basit bir Karar Ağacı gibi gözümde canlandırmak)
- Kendime notlar çıkartarak olası problemli değişkenleri ve durumları belirlemek
- Keşifçi veri analizi (EDA) yaparak, veri ile bolca oynamak
- Keşifçi veri analizi sürecinde çıkardığım notlarla kayıp verileri doldurmak ya da farklı şekillerle eksik verileri doldurmak ve kayıp verilerin dağılımını istatistiksel olarak rastlantısal olduğunu öğrenmek
- Verideki anomali (beklenmeyen) durumları belirlemek, gerekirse veriden çıkarmak ya da ortanca-otalama-3.kantil gibi değerlerle doldurmak
- Anlamlı değişkenler üretmek
- Bazı numerik değişkenleri, gruplayarak (standart sapma ve ortalama değerleri incelenerek) kategorik veriye çevirerek yeni değişken üretmek
- Tüm bu işlemler sonunda tekrar korelasyonlarını inceleyerek 0.90 üstü korelasyonlu olan değişkenlerin birini veri setinden çıkarmak
- Kategorik değişkenlere One-Hot-Encoding ya da Label Encoding yapmak, değişkenleri standartlaştırmak
- Model kurma sürecinin başlayabilmek için problemi düşünerek hangi modelin/modellerin kullanabileceğini belirlemek
- En uygun model belirleyerek parametre ayarlamalarını yapmak, modeli geliştirmek (Model Tuning / Hyper-Parametre Tuning)
- Validasyon sayısını belirlemek ve aşırı öğrenmeyi engellemek için validasyon verisi kullanmak
- Hataların dağılımı ve hataların neyden kaynaklandığını belirlemek gibi konular için hataların incelenmesi
- Gerekli ise veri manipülasyonu ve tekrar modelin kurulması
- Son olarak test verisinin tahmini ve sonuçların paylaşılması.
Bu maddelerle birçok veri bilimi projesi yapabilir ve kullanabilirsiniz. Bu akış genellikle değişmez. Şunu belirtmek isterim ki, aslında modelin kurulması işin en kolay ve en kısa kısmı. En keyifli kısmı ise keşifçi veri analizleri süreçleri. En zor ve projenin yaklaşık %70’ ini oluşturan veri manipülasyonu kısmıdır. Fakat bu veride manipülasyon işlemi çok zor değildi.
Hadi biraz kodlayalım !
KÜTÜPHANELER ve VERİ
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import KFold
import matplotlib.pyplot as plt
import lightgbm as lgb
import seaborn as sns
import pandas as pd
import numpy as np
import warnings
import re
warnings.filterwarnings("ignore")
train = pd.read_csv("titanic/train.csv")
test = pd.read_csv("titanic/test.csv")
test_index = test.PassengerId.copy()
train.drop(["PassengerId"], axis = 1, inplace = True) # Drop
test.drop(["PassengerId"], axis = 1, inplace = True) # Drop

Gerekli kütüphaneleri import ettikten sonra verimizi yükleyelim ve şu an için önemsiz olan id numarasını silelim. Eğitim verisine bakıldığı zaman, hedef değişkenimizin “Survived” ve binary (ikili) sınıflandırma problemi olduğu görülüyor. “Name” değişkeninden anlamlı bilgi üretmek için manipülasyon işlemleri uygulanabilir. Metin madenciliğinden ziyade, değişkenimizde Mr. ve Mrs. gibi ünvan kelimelerin olduğu görülüyor. Buradan anlamlı bilgiler çıkartılabilir. “Ticket” değişkeni incelendiğinde, biletin numarası ya da geminin bir şeyi olduğu anlaşılıyor. “Cabin” değişkeni ise biletin geminin neresinden alındığı, kabin numarasını veriyor. Bir açıdan lokasyon gibi düşünebiliriz. Cabin değişkeninden karar bazlı bir model kurulurken faydalanabiliriz. Bu değişken sayesinde geminin kaçış sandallarına yakın olan yolcularının yaşama şansının daha yüksek olduğunu düşünebiliriz, böylece modelimizde hedef değişkeninin üzerinde ciddi bir önemi olduğu görülecektir. Diğer bir düşünceyle “Pclass” değişkeni ile geminin iş sınıfı-ekonomi-birinci sınıf gibi bilgilerine ulaşabiliyoruz. Varsayımlar kontrol edildikten sonra sınıflar arasında hayatta kalma durumu için hipotez testi yapılarak bu durum istatistiksel olarak belirtilebilir. “Embarked” değişkeni ise yolcunun hangi limandan gemiye bindiğini belirten bir değişkendir.
Aşağıdaki örnek görselleştirmeyi tam ekran (full screen) seçeneği ile inceleyebilirsiniz.
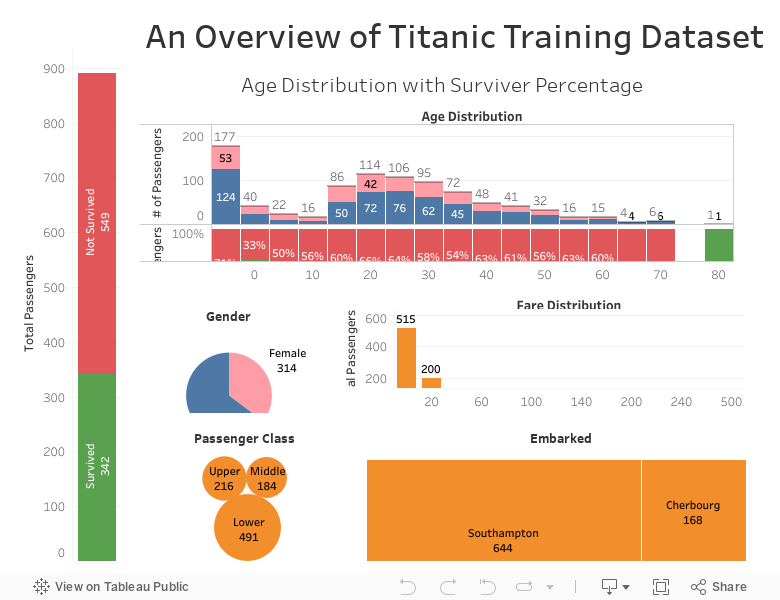
Kategorik değişkenlerimiz için verilerimizi basit bir şekilde görselleştirelim.
VERİ GÖRSELLEŞTİRME – Kategorik
def eda_object(df,feature):
a = len(df[feature].unique())
plt.figure(figsize = [15,min(max(8,a),5)])
plt.subplot(1,2,1)
x_ = df.groupby([feature])[feature].count()
x_.plot(kind='pie')
plt.title(feature)
plt.subplot(1,2,2)
cross_tab = pd.crosstab(df['Survived'],df[feature],normalize=0).reset_index()
x_ = cross_tab.melt(id_vars=['Survived'])
x_['value'] = x_['value']
sns.barplot(x=feature,y='value',hue ='Survived',data=x_,palette = ['b','r','g'],alpha =0.7)
plt.xticks(rotation='vertical')
plt.title(feature + " - Survived")
plt.tight_layout()
plt.legend()
plt.show()
rm_list = ['PassengerId','Name','Ticket', "Cabin"]
type_list = ['object']
feature_list = []
for feature in train.columns:
if (feature not in rm_list) & (train[feature].dtypes in type_list):
feature_list.append(feature)

train[["Survived", "Pclass", "Sex", "Cabin", "Embarked"]] = train[["Survived", "Pclass", "Sex", "Cabin", "Embarked"]].astype("object")
test[["Pclass", "Sex", "Cabin", "Embarked"]] = test[["Pclass", "Sex", "Cabin", "Embarked"]].astype("object")
Kategorik verilerimizi programa “object” olarak belirtmemiz gerekmektedir. Python dilinde kategorik(karakter vs.) değişkenler “object” olarak tanımlanır. R dilinde ise “factor” olarak isimlendirilir. Eğitim verisine ne uyguladıysa, aynı işlemi test verisine de uygulanması gerekmektedir. Şimdi numerik değişkenlerimizi inceleyelim.
VERİ GÖRSELLEŞTİRME – Numerik
def eda_numeric(df,feature):
x_ = df[feature]
y_ = df['Survived']
data = pd.concat([x_,y_],1)
plt.figure(figsize=[15,5])
ax1 = plt.subplot(1,2,1)
sns.boxplot(x='Survived',y=feature,data=data)
plt.title(feature+ " - Boxplot")
upper_0 = data[data['Survived']==0][feature].quantile(q=0.75)
upper_1 = data[data['Survived']==1][feature].quantile(q=0.75)
lower_0 = data[data['Survived']==0][feature].quantile(q=0.25)
lower_1 = data[data['Survived']==1][feature].quantile(q=0.25)
ax1.set(ylim=(min(lower_0,lower_1),max(upper_0,upper_1)))
ax2 = plt.subplot(1,2,2)
plt.title(feature+ " - Density with Log")
p1=sns.kdeplot(data[data['Survived']==0][feature].apply(np.log), color="b",legend=False)
p2=sns.kdeplot(data[data['Survived']==1][feature].apply(np.log), color="r",legend=False)
plt.legend(loc='upper right', labels=['0', '1'])
plt.tight_layout()
plt.show()
rm_list = ['PassengerId','Name','Ticket', "Cabin"]
type_list = ['int64','float']
feature_list = []
for feature in train.columns:
if (feature not in rm_list) & (train[feature].dtypes in type_list) & (len(train[feature].unique()) > 5):
feature_list.append(feature)

Kategorik kırılımda bazı değişkenlerimizi inceleyelim.
Kategorik Kırılımda Veri Görselleştirmeleri
%config InlineBackend.figure_format = "retina" sns.catplot(x="Embarked", y="Age", data = train, hue = "Sex");

sns.boxplot("SibSp", "Age", data = train);

sns.boxplot("SibSp", "Fare", hue = "Survived", data = train, palette="ch:0.25");

tmp = pd.crosstab(train['Embarked'], train['Survived'], normalize='index') * 100
tmp = tmp.reset_index()
tmp.rename(columns={0:'Survived', 1:'NoSurvived'}, inplace=True)
plt.figure(figsize=(14,10))
plt.suptitle('Embarked Distributions', fontsize=22)
plt.subplot(221)
g = sns.countplot(x='Embarked', data=train)
g.set_title("Embarked Distribution", fontsize=19)
g.set_xlabel("Embarked Name", fontsize=17)
g.set_ylabel("Count", fontsize=17)
for p in g.patches:
height = p.get_height()
g.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/len(train)*100),
ha="center", fontsize=14)
plt.subplot(222)
g1 = sns.countplot(x='Embarked', hue='Survived', data=train)
plt.legend(title='Survived', loc='best', labels=['No', 'Yes'])
gt = g1.twinx()
gt = sns.pointplot(x='Embarked', y='Survived', data=tmp, color='black', order=['S', 'C', 'Q'], legend=False)
gt.set_ylabel("% of Survived ", fontsize=16)
g1.set_title("Embarked by Target(Survived)", fontsize=19)
g1.set_xlabel("Embarked Name", fontsize=17)
g1.set_ylabel("Count", fontsize=17)
plt.subplot(212)
g3 = sns.boxenplot(x='Embarked', y='Age', hue='Survived',
data=train[train['Age'] <= 100] )
g3.set_title("Age Distribuition by Embarked and Target", fontsize=20)
g3.set_xlabel("Embarked Name", fontsize=17)
g3.set_ylabel("Age Values", fontsize=17)
plt.subplots_adjust(hspace = 0.6, top = 0.85)
plt.show()

sns.pairplot(data=train[["Fare", "Survived", "Age", "Pclass"]], hue = "Survived", dropna = True);

pd.crosstab([train.Embarked, train.Pclass], [train.Sex, train.Survived], margins = True).style.background_gradient(cmap = 'cubehelix_r')

sns.catplot("Survived", "SibSp", kind = "violin", hue = "Sex", data = train);

Eksik değerlerimize baktığımızda 3 değişkenimizde kayıp verilerimiz mevcut. Aşağıdaki tabloda eksik veri oranları ve gerekli nitelikler belirtilmiştir.
KAYIP VERİLER
KAYIP VERİ – GÖRSEL
def missing_zero_values_table(df):
zero_val = (df == 0.00).astype(int).sum(axis=0)
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
mz_table = pd.concat([zero_val, mis_val, mis_val_percent], axis=1)
mz_table = mz_table.rename(
columns = {0 : 'Zero Values', 1 : 'Missing Values', 2 : '% of Total Values'})
mz_table['Total Zero Missing Values'] = mz_table['Zero Values'] + mz_table['Missing Values']
mz_table['% Total Zero Missing Values'] = 100 * mz_table['Total Zero Missing Values'] / len(df)
mz_table['Data Type'] = df.dtypes
mz_table = mz_table[
mz_table.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print ("Your selected dataframe has " + str(df.shape[1]) + " columns and " + str(df.shape[0]) + " Rows.\n"
"There are " + str(mz_table.shape[0]) +
" columns that have missing values.")
return mz_table
missing_zero_values_table(train)

Eksik verilerimizi görsel üzerinden gösterelim.
fig, ax = plt.subplots(figsize = (9, 5)) sns.heatmap(train.isnull(), cmap = "cubehelix_r", yticklabels='') plt.show()

Eksik verilerimizi doldururken keşifçi veri analizi kısmında gördüğüm bazı durumlar vardı. Bunlar, gerekli filtrelemeleri yaptığımda “Embarked” değişkeninde 2 tane kayıp veri vardı. Bu eksik verileri “S” ile doldurdum. “Age” değişkenimizde, yaklaşık %20 oranında kayıp verimiz vardı. Bunları doldururken bazen kişisel projelerimde kullandığım bir yöntem ile verimi doldurmak istedim. Bu yaklaşımda; eğitim verisindeki yaş ortalaması ile test verisindeki yaşların standart sapmasını, toplayıp-çıkarıp, aralıklara göre yerleştirerek yaş değişkenindeki kayıp verileri doldurdum. “Fare” değişkeninde de ortanca ile kayıp değer doldurma yoluna gittim.
KAYIP VERİ – DOLDURMA İŞLEMLERİ
train["Embarked"] = train["Embarked"].fillna('S')
test["Embarked"] = test["Embarked"].fillna('S')
data = [train, test]
for dataset in data:
mean = train["Age"].mean()
std = test["Age"].std()
is_null = dataset["Age"].isnull().sum()
rand_age = np.random.randint(mean - std, mean + std, size = is_null)
age_slice = dataset["Age"].copy()
age_slice[np.isnan(age_slice)] = rand_age
dataset["Age"] = age_slice
dataset["Age"] = train["Age"].astype(int)
train["Fare"] = train["Fare"].fillna(train["Fare"].median())
test["Fare"] = test["Fare"].fillna(test["Fare"].median())
Veri bilimciler için diğer bir önemli konu ise yeni parametreler üretmektir. Makine Öğrenmesi algoritmalarında, model başarısını arttırmak için yapılan bu adımda; mevcut değişkenleri kullanarak, araştırmacı ve problemin çözümü için önemli olabilecek yeni değişkenleri bulma ve oluşturma sürecidir.
“Ticket” değişkeninden yeni bir parametre olarak ilk harfi alınmıştır. “Fare” değişkeni numerik bir değişkendir. “Fare_group” ile bu numerik değişken, ortalama ve standart sapmalarına göre 10 farklı gruba bölünerek kategorikleştirilmiştir. Aynı işlem “Age” değişkeni için uygulanarak “Age_group” değişkeni üretilmiştir. Bireylerin gemideki toplam aile büyüklüğü hesaplanmıştır. Bu rakama göre “Alone” parametresi üretilmiştir. Önceki çalışmaları incelediğimde gördüğüm bir işlemi anlatmak istiyorum, “Name” değişkeninden “title” değişkeni üretilmiştir. Bu değişken ile kişinin ünvanı Mr., Mrs., kaptan, doktor ve nadir kişi gibi değerler çıkartılmıştır. Hedef değişken için önemli olduğunu düşündüğüm bir değişkeni çıkarmış oldum. “Cabin” ile “Ticket” değişkenlerini birleştirerek gemideki kabin lokasyonunu iyice daraltacağımı düşünerek iki değişkeni birleştirdim. Model bittikten sonra “Parametre Önemi” grafiğine baktığımda ise bu değişkenin önemli bir değişken olduğunu gördüğümde şaşırmıştım.
Birçok kategorik veriyi gruplayarak, numerik değişkenlere böldüğümde ve tüm bu numerik değişkenlerin kombinasyonunu farklı istatistiksel değerlerini de modele ekledim. Böylece değişken sayımı üstel olarak ciddi sayıda arttırdım ve bu işlemin modelin başarısında ciddi bir farklılık oluşturduğunu gördüm (Sınıflandırma başarısı ölçüm birimlerinden olan AUC değeri 84’ten 92’e yükseldi).
FEATURE ENGINEERING (Parametre Mühendisliği)
Yeni Değişkenler – Üretim
%%time
train.Cabin.fillna("Miss", inplace=True)
train.Cabin = [i[0] for i in train.Cabin.astype("str")]
test.Cabin.fillna("Miss", inplace=True)
test.Cabin = [i[0] for i in test.Cabin.astype("str")]
train.Ticket = [i[0] for i in train.Ticket.astype("str")]
test.Ticket = [i[0] for i in test.Ticket.astype("str")]
# Fare değişkenini kategorikleştirelim (gruplayalım)
train.Fare_group = pd.DataFrame()
train['Fare_group'] = np.where(train['Fare'] < 7, 'Low_Fare',
np.where(train["Fare"] < 14, "low_mid_Fare",
np.where(train["Fare"] < 21, "mid_fare",
np.where(train["Fare"] < 28, "mid_high_fare",
np.where(train["Fare"] < 35, "high_low_fare",
np.where(train["Fare"] < 42, "high_mid_fare",
np.where(train["Fare"] < 49, "high_high_fare",
np.where(train["Fare"] < 56, "top_fare",
np.where(train["Fare"] < 63, "max_fare", "out_top_fare")))))))))
# Aynı işlemleri test verisine de uygulayalım
test.Fare_group = pd.DataFrame()
test['Fare_group'] = np.where(test['Fare'] < 7, 'Low_Fare',
np.where(test["Fare"] < 14, "low_mid_Fare",
np.where(test["Fare"] < 21, "mid_fare",
np.where(test["Fare"] < 28, "mid_high_fare",
np.where(test["Fare"] < 35, "high_low_fare",
np.where(test["Fare"] < 42, "high_mid_fare",
np.where(test["Fare"] < 49, "high_high_fare",
np.where(test["Fare"] < 56, "top_fare",
np.where(test["Fare"] < 63, "max_fare", "out_top_fare")))))))))
# Age değişkenini gruplayalım
train['Age_group'] = 0
train.loc[train['Age'] <= 15, 'Age_group'] = 0
train.loc[(train['Age'] > 15) & (train['Age'] <= 30), 'Age_group']=1
train.loc[(train['Age'] > 30) & (train['Age'] <= 45), 'Age_group']=2
train.loc[(train['Age'] > 45) & (train['Age'] <= 60), 'Age_group']=3
train.loc[train['Age'] > 60, 'Age_group'] = 4
test['Age_group'] = 0
test.loc[test['Age'] <= 15, 'Age_group'] = 0
test.loc[(test['Age'] > 15) & (test['Age'] <= 30), 'Age_group']=1
test.loc[(test['Age'] > 30) & (test['Age'] <= 45), 'Age_group']=2
test.loc[(test['Age'] > 45) & (test['Age'] <= 60), 'Age_group']=3
test.loc[test['Age'] > 60, 'Age_group'] = 4
train['FamilySize'] = train['SibSp'] + train['Parch'] + 1
test['FamilySize'] = test['SibSp'] + test['Parch'] + 1
train.Alone = pd.DataFrame()
test.Alone = pd.DataFrame()
train["Alone"] = np.where(train["FamilySize"] < 2, 1, 0)
test["Alone"] = np.where(test["FamilySize"] < 2, 1, 0)
# Name değişkeninden kişinin ünvanını çıakrtalım
def title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
train['Title'] = train['Name'].apply(title)
test['Title'] = test['Name'].apply(title)
train['Title'] = train['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
train['Title'] = train['Title'].replace('Mlle', 'Miss')
train['Title'] = train['Title'].replace('Ms', 'Miss')
train['Title'] = train['Title'].replace('Mme', 'Mrs')
test['Title'] = test['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
test['Title'] = test['Title'].replace('Mlle', 'Miss')
test['Title'] = test['Title'].replace('Ms', 'Miss')
test['Title'] = test['Title'].replace('Mme', 'Mrs')
train['Fare_Per_Person'] = train['Fare']/(train['FamilySize'])
test['Fare_Per_Person'] = test['Fare']/(test['FamilySize'])
train.drop(["Name"], axis = 1, inplace = True)
test.drop(["Name"], axis = 1, inplace = True)
# Cabin ile Ticket değişkenini "_" ile birleştirelim
train["Cabin_Ticket"] = train["Cabin"]+"_"+train["Ticket"]
test["Cabin_Ticket"] = test["Cabin"]+"_"+test["Ticket"]
train['Cabin_Ticket_number'] = train['Cabin_Ticket'].apply(lambda x: len(x))
train['Title_grup_count'] = train.groupby(['Cabin_Ticket', 'Title'])['Cabin_Ticket_number'].transform('count')
# Kategorik ile numerik verileri gruplayarak yeni değişken üretelim
test['Cabin_Ticket_number'] = test['Cabin_Ticket'].apply(lambda x: len(x))
test['Title_grup_count'] = test.groupby(['Cabin_Ticket', 'Title'])['Cabin_Ticket_number'].transform('count')
train['Pclass_Alone_count'] = train.groupby(['Pclass', 'Alone'])['Age'].transform('count')
test['Pclass_Alone_count'] = test.groupby(['Pclass', 'Alone'])['Age'].transform('count')
train['Pclass_Alone_mean'] = train.groupby(['Pclass', 'Alone'])['Age'].transform('mean')
test['Pclass_Alone_mean'] = test.groupby(['Pclass', 'Alone'])['Age'].transform('mean')
train['Pclass_Alone_SibSp_count'] = train.groupby(['Pclass', 'Alone'])['SibSp'].transform('count')
test['Pclass_Alone_SibSp_count'] = test.groupby(['Pclass', 'Alone'])['SibSp'].transform('count')
train['Pclass_Alone_SibSp_mean'] = train.groupby(['Pclass', 'Alone'])['SibSp'].transform('mean')
test['Pclass_Alone_SibSp_mean'] = test.groupby(['Pclass', 'Alone'])['SibSp'].transform('mean')
train['Fare_group_Cabin_Age_count'] = train.groupby(['Fare_group', 'Cabin'])['Age'].transform('count')
test['Fare_group_Cabin_Age_count'] = test.groupby(['Fare_group', 'Cabin'])['Age'].transform('count')
train['Fare_group_Cabin_Age_mean'] = train.groupby(['Fare_group', 'Cabin'])['Age'].transform('mean')
test['Fare_group_Cabin_Age_mean'] = test.groupby(['Fare_group', 'Cabin'])['Age'].transform('mean')
train['Fare_group_Cabin_Fare_Per_Person_mean'] = train.groupby(['Fare_group', 'Cabin'])['Fare_Per_Person'].transform('mean')
test['Fare_group_Cabin_Fare_Per_Person_mean'] = test.groupby(['Fare_group', 'Cabin'])['Fare_Per_Person'].transform('mean')
train['Fare_group_Cabin_Fare_Per_Person_count'] = train.groupby(['Fare_group', 'Cabin'])['Fare_Per_Person'].transform('count')
test['Fare_group_Cabin_Fare_Per_Person_count'] = test.groupby(['Fare_group', 'Cabin'])['Fare_Per_Person'].transform('count')
train['Cabin_Ticket_Alone_count'] = train.groupby(['Cabin_Ticket', 'Alone'])['Age'].transform('count')
test['Cabin_Ticket_Alone_count'] = test.groupby(['Cabin_Ticket', 'Alone'])['Age'].transform('count')
train['Cabin_Ticket_Alone_mean'] = train.groupby(['Cabin_Ticket', 'Alone'])['Age'].transform('mean')
test['Cabin_Ticket_Alone_mean'] = test.groupby(['Cabin_Ticket', 'Alone'])['Age'].transform('mean')
train['Title_FamilySize_count'] = train.groupby(['Title', 'FamilySize'])['Fare'].transform('count')
test['Title_FamilySize_count'] = test.groupby(['Title', 'FamilySize'])['Fare'].transform('count')
train['Title_FamilySize_Parch_count'] = train.groupby(['Title', 'FamilySize'])['Parch'].transform('count')
test['Title_FamilySize_Parch_count'] = test.groupby(['Title', 'FamilySize'])['Parch'].transform('count')
train['Title_FamilySize_mean'] = train.groupby(['Title', 'FamilySize'])['Fare'].transform('mean')
test['Title_FamilySize_mean'] = test.groupby(['Title', 'FamilySize'])['Fare'].transform('mean')
train['Title_FamilySize_Parch_mean'] = train.groupby(['Title', 'FamilySize'])['Parch'].transform('mean')
test['Title_FamilySize_Parch_mean'] = test.groupby(['Title', 'FamilySize'])['Parch'].transform('mean')
# For döngüsü ile yeni parametreler
columns=['Title_FamilySize_Parch_mean','Fare_group_Cabin_Age_mean', 'Age', 'Parch', 'SibSp', 'Title_FamilySize_mean', 'FamilySize', 'Fare_Per_Person', 'Fare_group_Cabin_Age_mean',
'Cabin_Ticket_number', 'Fare_group_Cabin_Fare_Per_Person_count','Fare','Title_grup_count','Pclass_Alone_mean','Pclass_Alone_SibSp_count','Cabin_Ticket_Alone_mean','Title_FamilySize_count','Fare_group_Cabin_Fare_Per_Person_mean']
obj_cols=['Alone','Cabin_Ticket','Title', 'Fare_group','Cabin','Pclass','Age_group', "Embarked", "Sex"]
for col in columns:
for feat in obj_cols:
train[f'{col}_mean_group_{feat}']=train[col]/train.groupby(feat)[col].transform('mean')
train[f'{col}_max_group_{feat}']=train[col]/train.groupby(feat)[col].transform('max')
train[f'{col}_min_group_{feat}']=train[col]/train.groupby(feat)[col].transform('min')
train[f'{col}_skew_group_{feat}']=train[col]/train.groupby(feat)[col].transform('skew')
train[f'{col}_skew_group_{feat}']=train[col]/train.groupby(feat)[col].transform('count')
for col in columns:
for feat in obj_cols:
test[f'{col}_mean_group_{feat}']=test[col]/test.groupby(feat)[col].transform('mean')
test[f'{col}_max_group_{feat}']=test[col]/test.groupby(feat)[col].transform('max')
test[f'{col}_min_group_{feat}']=test[col]/test.groupby(feat)[col].transform('min')
test[f'{col}_skew_group_{feat}']=test[col]/test.groupby(feat)[col].transform('skew')
test[f'{col}_skew_group_{feat}']=test[col]/test.groupby(feat)[col].transform('count')
Yeni parametre üretme işlemi yukarıdaki kodlar ile yapılmıştır. Korelasyonları yüksek parametreleri silmek için aşağıda sevdiğim ve sıklıkla kullandığım kodu sizlerle paylaşıyorum. Burada veri setinde bulunan en yüksek korelasyona sahip 30 değişkeni sıralıyor. Buradan gereksiz ve modelde bulunmaması gereken değişkenleri belirleyebilirsiniz. Int32 ve int64 türünde olan değişkenler arasında bu işlemi yapıyorum.
Yeni Değişkenler – Korelasyon
def get_redundant_pairs(df):
pairs_to_drop = set()
cols = df.columns
for i in range(0, df.shape[1]):
for j in range(0, i+1):
pairs_to_drop.add((cols[i], cols[j]))
return pairs_to_drop
def get_top_abs_correlations(df, n=5):
au_corr = df.corr().abs().unstack()
labels_to_drop = get_redundant_pairs(df)
au_corr = au_corr.drop(labels=labels_to_drop).sort_values(ascending=False)
return au_corr[0:n]
print("Top Absolute Correlations !")
print(get_top_abs_correlations(train.select_dtypes(include=['int32','int64']), 30))


LightGBM modelinde, değişkenleri label encode etmeden de kategorik verileri belirterek modeli koşturabilirsiniz fakat ben LabelEncode yöntemiyle de bunu yapmak istedim. Aşağıdaki kod dizini ile bu işlem gerçekleştirilmiştir.
Label Encoding
categorical_1 = ["Pclass", "Sex", "Ticket", "Cabin", "Embarked", "Fare_group", "Age_group", "Alone", "Title", "Cabin_Ticket"]
from sklearn.preprocessing import LabelEncoder
for col in train[categorical_1].columns:
train[col] = train[col].astype(str)
test[col] = test[col].astype(str)
le = LabelEncoder()
le.fit(list(train[col])+list(test[col]))
train[col] = le.transform(train[col])
test[col] = le.transform(test[col])
train[col] = train[col].astype('category')
test[col] = test[col].astype('category')
LGBM MODEL
y = train['Survived']
train = train.drop(['Survived'],axis=1)
nfolds = 15
folds = KFold(n_splits = nfolds, shuffle=True, random_state=4590)
# Hiperparametrelerimiz
params = {
'num_leaves': 2**5 - 1,
'max_depth': 8,
'min_data_in_leaf': 50,
'learning_rate': 0.05,
'feature_fraction': 0.75,
'bagging_fraction': 0.75,
'bagging_freq': 1,
'metric': 'auc',
'num_threads': 4,
'verbose': -1,
'objective': 'binary',
'metric': 'auc',
"boosting_type": "gbdt"
}
num_round = 10000
HyperParametre işlemlerini yukarıdaki gibi görebilirsiniz. Bu değerleri GreadSearh gibi basit algoritmalarla da belirleyebilirsiniz ya da istatistikte sıklıkla kullanılan “Bayesgil Optimizasyon”la da. Ben bu çalışmada GreadSearch yöntemini kullandım. Son rakamlar yukarıda belirtildiği gibidir.
Aşağıda LighGBM modelini bulabilirsiniz. Bu işlemi olabildiğince sadece gösterdim. Bu kodu siz de istediğiniz zaman rahatlıkla buradan kullanabilirsiniz. Sadece veri setini değiştirmeniz (y ve train) yeterli olacaktır. Umarım bu kod dizini siz değerli insanların işini kolaylaştırır. Bu modelde 30 validasyonlu (bilerek bu rakamı yüksek tutmak istedim) LGBM modeli kullanılmıştır. Aynı zamanda “Parametre Önemini” de kendisi doldurmaktadır. Her validasyonun en iyi hyperparametreleri ile test datasını tahmin etmektedir. Bu tahmini yaptıktan sonra CV sayısına bölmektedir.
feature_importance_df = np.zeros((train.shape[1], nfolds))
mvalid = np.zeros(len(train))
predictions = np.zeros(len(test))
aucs = list()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train.values, train.values)):
print('----')
print("fold n°{}".format(fold_))
x0,y0 = train.iloc[trn_idx], y[trn_idx]
x1,y1 = train.iloc[val_idx], y[val_idx]
trn_data = lgb.Dataset(x0, label= y0); val_data = lgb.Dataset(x1, label= y1)
clf = lgb.train(params, trn_data,
num_round, valid_sets = [trn_data, val_data],
verbose_eval=2000,
early_stopping_rounds = 1000,
categorical_feature = ["Pclass", "Sex", "Ticket", "Cabin", "Embarked", "Fare_group", "Age_group", "Alone", "Title", "Cabin_Ticket"])
mvalid[val_idx] = clf.predict(x1, num_iteration=clf.best_iteration)
feature_importance_df[:, fold_] = clf.feature_importance()
predictions += clf.predict(test, num_iteration=clf.best_iteration) / folds.n_splits
aucs.append(clf.best_score['valid_1']['auc'])
print('-' * 80)
print('-' * 70)
print('-' * 60)
print('-' * 50)
print('-' * 40)
print('Mean AUC:', np.mean(aucs).round(3))


Sonuç olarak, 30 Cross Validasyonlu ortalama AUC değerimiz 0.92 gibi çok başarılı bir sonuç elde ediyoruz. Hedef değişkenimiz üzerinde en etkili 45 değişkeni görmek istediğimizde ise aşağıdaki gibi bir görselle karşılaşıyoruz.
PARAMETRE ÖNEMİ
ximp = pd.DataFrame()
ximp['feature'] = train.columns
ximp['importance'] = feature_importance_df.mean(axis = 1)
plt.figure(figsize=(10,8))
sns.barplot(x="importance",
y="feature",
data=ximp.sort_values(by="importance",
ascending=False).head(45))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()

Modeli başarılı yapmak kadar, modelin çıktılarını yorumlamak ve gerekli stratejileri belirlemek de bizlerin görev tanımları arasındadır. Bu sebeple, oluşturduğumuz modelin bağımlı değişkenin değişimi de incelenmelidir. “Parametre Önemi” dediğimiz bu işlem/görsel sayesinde bağımlı değişken üzerinde en önemli/etkili değişkenleri görebiliyoruz. Bunun için çeşitli algoritmalar mevcuttur. Örneğin Rastgele Orman (Random Forest) tabanlı çalışan “Boruta Algoritması” ya da “Greedy Algoritmaları” bu önem düzeyini görebilmemize imkân sağlamaktadır. LightGBM ya da XGBoost gibi karar bazlı (Rule Based Models) modellerde önem düzeyini Python üzerinden görebiliyoruz. Çıktıya bakıldığında yaş-cinsiyet-kabin/ticket numaralarının hayatta kalım üzerine ne kadar önemli olduğunu görebiliyoruz.
Veri bilimciler olarak bizlerin temel görev ve sorumlulukları arasında veriyi modellemek, algoritmalar ile sorunu çözmek gibi maddeler olsa da keşifçi veri analizleri ile mevcut sorunları göstermek ve bu sorunları çözmek için öneriler de sunmak olduğunu unutmamalıyız.
“Veri Çağı” nda olduğumuzu bilmek ve bu durumu iyice özümsemek zorundayız. Veri okur yazarlığının önemini her yazımda vurguluyorum. Bu yazımda da verinin bize söylediği bilgileri anlamanın önemini belirterek sonlandırmak isterim. Bu uygulama çalışmamızla beraber LightGBM gibi Makine Öğrenmesinin en son silahlarından biri olan güzel bir algoritmayı öğrenmiş olduk. Şimdi pratik yapma sırası sizde…
Saygılarımla.
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın..
UTKU KUBİLAY ÇINAR
merhaba,
hiperparametre kısmında aşağıdaki hatayı alıyorum.
—————————————————————————
KeyError Traceback (most recent call last)
in ()
—-> 1 y = train[‘Survived’]
2 train = train.drop([‘Survived’],axis=1)
3 nfolds = 15
4
5 folds = KFold(n_splits = nfolds, shuffle=True, random_state=4590)
C:\Users\erkan.ulgey\AppData\Local\Continuum\anaconda2\lib\site-packages\pandas\core\frame.pyc in __getitem__(self, key)
2925 if self.columns.nlevels > 1:
2926 return self._getitem_multilevel(key)
-> 2927 indexer = self.columns.get_loc(key)
2928 if is_integer(indexer):
2929 indexer = [indexer]
C:\Users\erkan.ulgey\AppData\Local\Continuum\anaconda2\lib\site-packages\pandas\core\indexes\base.pyc in get_loc(self, key, method, tolerance)
2657 return self._engine.get_loc(key)
2658 except KeyError:
-> 2659 return self._engine.get_loc(self._maybe_cast_indexer(key))
2660 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
2661 if indexer.ndim > 1 or indexer.size > 1:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: ‘Survived’
Teşekkürler
Erkan Bey merhaba,
Sorunu tam olarak görememekle birlikte çözüm için bir fikrim var. Bu kodlardan önce Survived değişkenini tanımlıyordum. Muhtemelen sizde o tanımlı değil. Model “Survived” değişkenini train setinde göremediği için bu problemi alıyorsunuz. Muhtemelen bağımlı değişkeni tanımlamayı unuttunuz ya da bağımlı değişkenin adını ya da tırnak işaretlerinde bir eksik/hata var gibi görünüyor.
Bu adımları kontrol ederseniz model çalışacaktır.
Teşekkür ederim geri dönüşünüz için.
Merhabalar,
Projeni okuyunca yazı yazmadan geçemedim. Oldukça akıcı, neyi neden dolayı yaptığını anlatan bir çalışma olmuş. Veri Bilimi dünyasına henüz çok çok yeni katılmış biri olarak, kafamda oturmamış olan kavramları sayenizde oturtmuş oldum. Emeğinize sağlık.
Başarılarının devamını dilerim.
Çok teşekkür ederim Yusuf, ne mutlu bana.