

![]()
Veri ambarı (data warehouse) modellemesinde bir gün mutlaka şu sorunla karşılaşırız: tek bir fact satırı, birden fazla boyut değerine bağlanmak istiyor. Bir hasta ziyaretinin birden çok tanısı vardır, bir banka hesabının birden çok ortak sahibi olabilir, bir öğrenci birden çok ana dalda okuyabilir, bir makaleyi birden çok yazar yazabilir. Klasik yıldız şeması (star schema) ise tek değerli (single-valued) boyutlar üzerine kurulu. Peki o zaman ne yapacağız? Ralph Kimball’ın bu sorun için önerdiği klasik çözümü, yani Bridge Table (köprü tablo) tekniğini kullanacağız.
Bridge Table nedir? Kısaca: bir fact tablosu ile bir dimension arasındaki çoktan-çoğa (many-to-many) ilişkiyi modellemek için araya konulan yardımcı bir tablodur. Fact tablosu doğrudan boyutun anahtarı yerine bir grup anahtarı (group key) tutar; Bridge Table ise her grup için, gruba dahil her boyut üyesini ve o üyeye düşen payı belirten bir weighting factor (ağırlıklandırma faktörü) ile birlikte tek bir satır halinde saklar. Böylece tek bir fact satırı, fact tablosunun satır detay seviyesini bozmadan birden çok boyut değerine bağlanabilir.
Bu yazıda , Bridge Table tekniğini, neden çift sayım (double counting) sorunu yarattığını ve weighting factor ile bunu nasıl çözeceğimizi adım adım göreceğiz. Sonra da Docker üzerinde PostgreSQL ayağa kaldırıp tüm bunları somut bir hastane faturalandırma senaryosu üzerinde uygulayacağız.
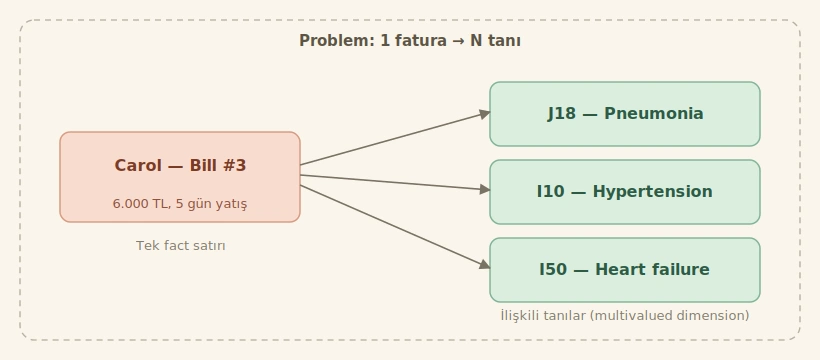
1. Problem: Çok Değerli Boyutlar (Multivalued Dimensions)
Klasik bir yıldız şemasında, bir fact tablosuna (fact table) bağlanan her boyut (dimension), fact tablosunun satır detay seviyesi (grain) ile tutarlı tek bir değer alır [1]. Yani bir satış faktı bir müşteriye, bir ürüne, bir tarihe karşılık gelir. Bu güzel, temiz ve sorgulaması kolay bir yapıdır.
Ama gerçek dünya bu kadar temiz değil. Kimball’ın klasik örneklerinden bazılarına bakalım [1][3]:
- Bir hasta aynı anda birden çok tanıya sahip olabilir.
- Bir öğrenci birden çok ana dalda okuyabilir.
- Tüketicilerin birden çok ilgi alanı olabilir.
- Ticari müşteriler birden çok endüstri sınıflandırmasına dahil olabilir.
- Çalışanlar birden çok beceriye veya sertifikaya sahip olabilir.
- Ürünlerin birden çok opsiyonel özelliği olabilir.
- Banka hesaplarının birden çok ortak müşterisi olabilir.
Bu, sektörlerden bağımsız, kaçınılmaz bir tasarım problemi [3]. Bunu nasıl modelleriz? İlk akla gelen kaba çözüm, fact tablosuna diagnosis_1, diagnosis_2, diagnosis_3 gibi alanlar eklemek. Bu yaklaşımı seçenler de var ama her ziyaretin tanı sayısı değişkense ne olacak? Bazılarında 1 tane, bazılarında 7 tane varsa? Sütun sayısını sabitlemek hem yer israfı yapar hem de raporlamayı kabusa çevirir [4].
İşte Kimball’ın önerisi bu noktada devreye giriyor.
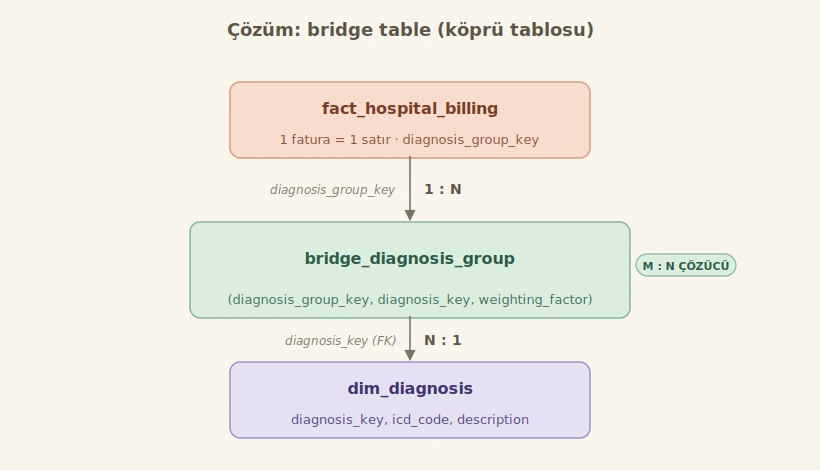
2. Çözüm: Bridge Table
Kimball’ın yaklaşımı şöyle [1][2]:
- Fact tablosuna doğrudan boyut anahtarı (dimension key) koymak yerine, bir grup anahtarı (group key) koyarız.
- Bu grup anahtarı, bir köprü tabloya (bridge table) bağlanır.
- Köprü tablosunun her satırı, grubun bir üyesini (örneğin bir tanıyı) temsil eder.
- Köprü tablosu da asıl boyut tablosuna bağlanır.
Bridge Table iki dimension arasında da olabilir, fact ve dimension arasında da [2]. Önemli olan, çoktan-çoğa (many-to-many) ilişkinin fact tablosunun satır detay seviyesini bozmadan modellenebilmesi.
Şematik olarak şöyle görünür:
fact_hospital_billing
|
| diagnosis_group_key
v
bridge_diagnosis_group -----> dim_diagnosis
(diagnosis_group_key,
diagnosis_key,
weighting_factor)
Bu yapı çok esnek: yeni bir tanı eklemek istediğimizde veritabanı şemasında değişiklik yapmamız gerekmiyor [3]. Sadece bridge tabloya yeni satırlar ekliyoruz.
İki Tür Bridge Table
Warren Thornthwaite, Kimball Design Tip #142’de iki temel bridge table sınıfından bahsediyor [2]:
- Zaman değişimsiz (time-invariant) bridge: Bir acil servis kaydının başlangıçtaki tanılarını düşünün. İşlem anında geçerli olan değer setini tutar, sonradan değişmez.
- Zaman değişimli (time-variant) bridge: Banka hesabı ile müşterileri arasındaki ilişki gibi. Hesap sahipleri zamanla değişebilir, bu yüzden köprü tablo genellikle Type 2 yavaş değişen boyutlara (slowly changing dimensions) dayanır [1].
3. Çift Sayım Problemi (Over-Counting)
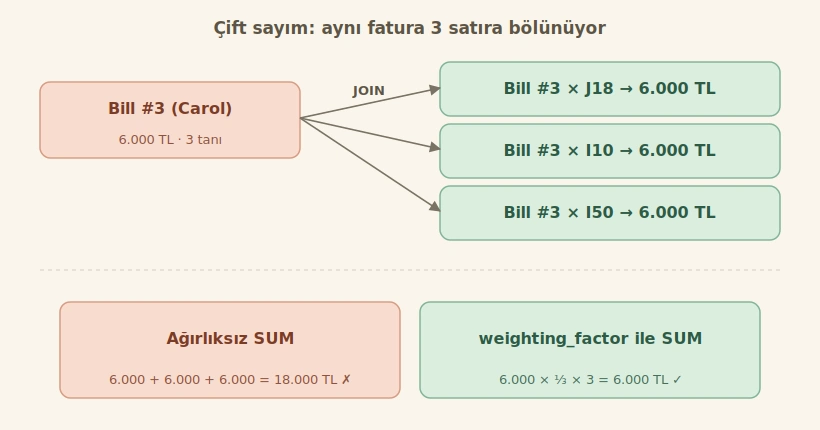
Şimdi en kritik noktaya geldik. Bridge Table sorunu çözer ama yan etkisi vardır: çoktan-çoğa boyuta göre gruplama yaparken, tek bir fact satırı birden fazla boyut satırıyla eşleştiği için ölçü değerleri (measures) çift sayılabilir [3][7].
Mesela hastanenin toplam fatura tutarı 1.000 TL olsun. Eğer bu fatura A, B, C, D olmak üzere 4 tanıya bağlanmışsa, basit bir join sonucu 4 satır döner. Hepsini toplarsak 4.000 TL elde ederiz, bu da yanlış [18].
İşte burada weighting factor (ağırlıklandırma faktörü) devreye giriyor.
Weighting Factor
Köprü tablosunun her satırına, o üyeye düşen oranı belirten bir ağırlık ekleriz [11][16]. Aynı grup içindeki ağırlıkların toplamı 1 (yani %100) olmalıdır [17]. Yukarıdaki örnekte 4 tanı varsa her birine 0.25 ağırlık veririz; sorgu sırasında ölçüyü bu ağırlıkla çarparız: 1000 × 0.25 + 1000 × 0.25 + 1000 × 0.25 + 1000 × 0.25 = 1000 TL [18]. Doğru sonuç!
Ağırlıklar iki şekilde belirlenebilir [11]:
- İş kuralı tarafından (örneğin bir sigorta poliçesinde sürücülerden birine primin %75’i, diğerine %25’i atanabilir [16]).
- ETL sırasında otomatik hesaplama (eşit dağılım için 1 / üye sayısı).
İki Tür Rapor
Bridge Table kullandığımızda iki farklı sorgu deseni vardır [6][17]:
- Weighted report (ağırlıklı rapor): Ölçüler ağırlık faktörüyle çarpılır. Gerçek toplamı verir, çift sayım olmaz.
- Impact report (etki raporu): Ağırlık uygulanmaz; her boyut değerine ait toplam etkiyi gösterir. Toplamlar şişer ama bir tanıya “dokunan” toplam ciro gibi bir metriği anlamak için faydalıdır.
Kimball Group’un uyarısı: bridge table güçlüdür ama bedava değil. BI araçları genelde bu yapıyla SQL üretmekte zorlanır ve ağırlık atanmadıysa çift sayım kaçınılmazdır [3]. Şimdi bu teoriyi gerçekten elimizle yapalım.
4. Hands-on Demo: Docker + PostgreSQL
Şimdi yapacağımız şey: Docker üzerinde PostgreSQL ayağa kaldırıp [13][14], içine yıldız şeması + bridge table kuracağız, örnek veri yükleyeceğiz ve çift sayım probleminin gerçekten olduğunu, sonra da weighting factor ile düzeldiğini SQL sonuçlarıyla göreceğiz.
Senaryo: Hastane Faturalandırma
Bir hastanenin ödemeleri var. Her fatura bir hastaya ve bir tarihe ait. Her fatura birden çok tanıyla ilişkili olabilir. Biz tanıya göre maliyet analizi yapmak istiyoruz. Burada birebir Kimball’ın hasta-tanı örneğini kullanıyoruz [1][2].
Proje Yapısı
bridge-demo/
├── docker-compose.yml
└── init/
├── 01_schema.sql
├── 02_seed.sql
└── 03_queries.sql
Docker Compose Dosyası
PostgreSQL’in resmi imajı, ilk açılışta /docker-entrypoint-initdb.d dizinindeki .sql ve .sh dosyalarını alfabetik sırayla otomatik çalıştırır [13][19][20]. Bu, demo verisi yüklemek için biçilmiş kaftan.
docker-compose.yml:
services:
postgres:
image: postgres:16-alpine
container_name: kimball_bridge_demo
restart: unless-stopped
environment:
POSTGRES_USER: dwh
POSTGRES_PASSWORD: dwhpass
POSTGRES_DB: dwh
ports:
- "5432:5432"
volumes:
- ./init:/docker-entrypoint-initdb.d:ro
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U dwh -d dwh"]
interval: 5s
retries: 10
volumes:
pgdata:
Önemli not: /docker-entrypoint-initdb.d betikleri yalnızca veri dizini boşken çalışır [20]. Yani değişiklik yapıp tekrar test etmek istiyorsak docker compose down -v ile volume’u silmeliyiz.
Adım 1: Şema Oluşturma
init/01_schema.sql:
-- Dimension: Date
CREATE TABLE dim_date (
date_key INT PRIMARY KEY,
full_date DATE NOT NULL,
year INT NOT NULL,
month INT NOT NULL,
day INT NOT NULL
);
-- Dimension: Patient
CREATE TABLE dim_patient (
patient_key SERIAL PRIMARY KEY,
patient_no VARCHAR(20) NOT NULL UNIQUE,
full_name VARCHAR(100) NOT NULL,
birth_year INT
);
-- Dimension: Diagnosis (ICD-10)
CREATE TABLE dim_diagnosis (
diagnosis_key SERIAL PRIMARY KEY,
icd_code VARCHAR(10) NOT NULL UNIQUE,
diagnosis_description VARCHAR(200) NOT NULL
);
-- Dimension: Diagnosis Group (group dimension)
CREATE TABLE dim_diagnosis_group (
diagnosis_group_key SERIAL PRIMARY KEY,
group_description VARCHAR(255) NOT NULL,
icd_code_list VARCHAR(255) NOT NULL UNIQUE
);
-- Bridge: Diagnosis Group Bridge
CREATE TABLE bridge_diagnosis_group (
diagnosis_group_key INT NOT NULL REFERENCES dim_diagnosis_group(diagnosis_group_key),
diagnosis_key INT NOT NULL REFERENCES dim_diagnosis(diagnosis_key),
weighting_factor NUMERIC(6,4) NOT NULL,
PRIMARY KEY (diagnosis_group_key, diagnosis_key)
);
-- Fact: Hospital Billing
CREATE TABLE fact_hospital_billing (
bill_key BIGSERIAL PRIMARY KEY,
date_key INT NOT NULL REFERENCES dim_date(date_key),
patient_key INT NOT NULL REFERENCES dim_patient(patient_key),
diagnosis_group_key INT NOT NULL REFERENCES dim_diagnosis_group(diagnosis_group_key),
bill_amount NUMERIC(12,2) NOT NULL,
length_of_stay_days INT NOT NULL
);
Yapı şöyle: fact_hospital_billing.diagnosis_group_key, bridge_diagnosis_group.diagnosis_group_key ile aynı grup numarasını taşır. Bridge’in her satırı, o gruba dahil bir tanıyı + o tanının grubun toplamındaki ağırlığını kaydeder ve dim_diagnosis‘a bağlanır. Fact tablosunun satır detay seviyesi (bir fatura = bir satır) bozulmuyor [9][29].
Neden bridge.diagnosis_group_key üzerine fact.diagnosis_group_key‘den FK koymadık? Çünkü bridge_diagnosis_group içinde diagnosis_group_key tek başına eşsiz değil — kompozit birincil anahtarın yalnızca bir parçası (her grup birden çok satır içeriyor). FK için tekil bir hedef sütun gerekir. Bu yüzden ya FK’siz mantıksal bağ kurarız (yaptığımız bu) ya da Kimball’ın “group dimension” varyantını kurup dim_diagnosis_group(diagnosis_group_key PK, ...) tablosunu araya ekleriz; ama o yapı bu yazının kapsamı dışında.
Adım 2: Örnek Veri
init/02_seed.sql:
-- Date dimension (just a few days)
INSERT INTO dim_date (date_key, full_date, year, month, day) VALUES
(20260101, '2026-01-01', 2026, 1, 1),
(20260102, '2026-01-02', 2026, 1, 2),
(20260103, '2026-01-03', 2026, 1, 3);
-- Patients
INSERT INTO dim_patient (patient_no, full_name, birth_year) VALUES
('P001', 'Alice Brown', 1972),
('P002', 'Bob Smith', 1985),
('P003', 'Carol White', 1990);
-- Diagnoses
INSERT INTO dim_diagnosis (icd_code, diagnosis_description) VALUES
('E11', 'Type 2 diabetes'),
('I10', 'Hypertension'),
('J18', 'Pneumonia'),
('N18', 'Chronic kidney disease'),
('I50', 'Heart failure');
-- Diagnosis groups
-- Group 1: only E11 (single diagnosis)
-- Group 2: E11 + I10 (two diagnoses)
-- Group 3: J18 + I10 + I50 (three diagnoses)
-- Group 4: N18 + I10 (two diagnoses)
INSERT INTO dim_diagnosis_group (group_description, icd_code_list) VALUES
('Diabetes only', 'E11'),
('Diabetes + Hypertension', 'E11,I10'),
('Pneumonia + HT + Heart failure', 'I10,I50,J18'),
('CKD + Hypertension', 'I10,N18');
-- Bridge table: weighting_factor = 1 / number of members in the group
INSERT INTO bridge_diagnosis_group (diagnosis_group_key, diagnosis_key, weighting_factor)
SELECT
g.diagnosis_group_key,
d.diagnosis_key,
ROUND(1.0 / COUNT(*) OVER (PARTITION BY g.diagnosis_group_key), 4) AS weighting_factor
FROM dim_diagnosis_group g
CROSS JOIN LATERAL UNNEST(STRING_TO_ARRAY(g.icd_code_list, ',')) AS u(icd)
JOIN dim_diagnosis d ON d.icd_code = u.icd;
-- Bills
-- Bill 1: Alice, diabetes only (Group 1), 1,000 TL
-- Bill 2: Bob, diabetes + HT (Group 2), 2,000 TL
-- Bill 3: Carol, pneumonia + HT + HF (Group 3), 6,000 TL
-- Bill 4: Alice, CKD + HT (Group 4), 4,000 TL
INSERT INTO fact_hospital_billing
(date_key, patient_key, diagnosis_group_key, bill_amount, length_of_stay_days)
VALUES
(20260101, 1, 1, 1000.00, 1),
(20260101, 2, 2, 2000.00, 2),
(20260102, 3, 3, 6000.00, 5),
(20260103, 1, 4, 4000.00, 3);
Köprü tablo şuna benziyor (1 / üye sayısı ile eşit ağırlık):
| diagnosis_group_key | diagnosis_key (icd_code) | weighting_factor |
|---|---|---|
| 1 | E11 | 1.0000 |
| 2 | E11 | 0.5000 |
| 2 | I10 | 0.5000 |
| 3 | I10 | 0.3333 |
| 3 | I50 | 0.3333 |
| 3 | J18 | 0.3333 |
| 4 | I10 | 0.5000 |
| 4 | N18 | 0.5000 |
Burada eşit dağıtım kullandık ama gerçek hayatta iş tarafı, masrafın hangi tanıya nasıl bölüneceğini belirleyebilir [11][16].
Adım 3: Çift Sayımı ve Çözümü Gösteren Sorgular
init/03_queries.sql:
-- ============================================================
-- Query A: No bridge, try to attach diagnosis directly
-- (Just to illustrate: impossible! A single FK cannot model many-to-many.)
-- ============================================================
-- We cannot do this. The star schema does not support it. That is why bridge exists.
-- ============================================================
-- Query B: TRUE TOTAL (control value)
-- Sum the bills as-is, without asking about diagnosis.
-- ============================================================
SELECT
SUM(bill_amount) AS true_total
FROM fact_hospital_billing;
-- Expected: 13,000.00 TL
-- ============================================================
-- Query C: DOUBLE COUNTING PROBLEM (no weighting)
-- Join the bridge but DO NOT apply the weighting factor
-- ============================================================
SELECT
SUM(f.bill_amount) AS wrong_total
FROM fact_hospital_billing f
JOIN bridge_diagnosis_group b ON b.diagnosis_group_key = f.diagnosis_group_key;
-- Expected: 25,000.00 TL (1000 + 2*2000 + 3*6000 + 2*4000)
-- True total was 13,000. Inflated because of double counting!
-- ============================================================
-- Query D: WEIGHTED REPORT
-- Multiply each row by its weighting_factor
-- ============================================================
SELECT
ROUND(SUM(f.bill_amount * b.weighting_factor), 2) AS correct_total
FROM fact_hospital_billing f
JOIN bridge_diagnosis_group b ON b.diagnosis_group_key = f.diagnosis_group_key;
-- Expected: 13,000.00 TL (equals true total, no double counting)
-- ============================================================
-- Query E: WEIGHTED REPORT - breakdown by diagnosis
-- "Allocated amount per diagnosis" report
-- ============================================================
SELECT
d.icd_code,
d.diagnosis_description,
ROUND(SUM(f.bill_amount * b.weighting_factor), 2) AS allocated_amount
FROM fact_hospital_billing f
JOIN bridge_diagnosis_group b ON b.diagnosis_group_key = f.diagnosis_group_key
JOIN dim_diagnosis d ON d.diagnosis_key = b.diagnosis_key
GROUP BY d.icd_code, d.diagnosis_description
ORDER BY allocated_amount DESC;
-- Totals up to 13,000; no double counting.
-- ============================================================
-- Query F: IMPACT REPORT
-- No weighting; sum by diagnosis.
-- Answers: "How much business has 'touched' this diagnosis?"
-- The grand total will be inflated as expected; that is desired behavior.
-- ============================================================
SELECT
d.icd_code,
d.diagnosis_description,
SUM(f.bill_amount) AS touched_amount
FROM fact_hospital_billing f
JOIN bridge_diagnosis_group b ON b.diagnosis_group_key = f.diagnosis_group_key
JOIN dim_diagnosis d ON d.diagnosis_key = b.diagnosis_key
GROUP BY d.icd_code, d.diagnosis_description
ORDER BY touched_amount DESC;
-- Hypertension (I10) will rank highest here because it touches 3 separate bills.
Çalıştıralım
docker compose up -d docker compose exec postgres psql -U dwh -d dwh
psql içinde sorguları çalıştırınca şunları göreceğiz:
- Sorgu B (gerçek toplam): 13.000,00 TL
- Sorgu C (yanlış toplam, ağırlıksız): 25.000,00 TL — kabarık ve yanıltıcı.
- Sorgu D (weighted, ağırlıklı): 13.000,00 TL — doğru.
- Sorgu E (weighted, tanıya göre): Toplam yine 13.000, tanıya göre eşit paylaştırılmış.
- Sorgu F (impact): I10 (Hypertension) en çok faturaya dokunduğu için en yüksek değeri alır.
Tek bir join farkıyla yanlış yanıttan doğru yanıta nasıl geçtiğimizi gözle görmek, weighting factor’ün ne işe yaradığını çok netleştiriyor.
5. Pratik İpuçları ve Tuzaklar
Kimball Group’un Design Tip #166’sı bridge table’ın çekici görünmesine rağmen dikkat edilecek noktalarına işaret ediyor [3]:
- BI aracı uyumluluğu: Bazı raporlama araçları köprü tablo üzerinden geçen SQL üretirken zorlanır. Aracınızın bunu desteklediğini önceden test edin.
- Filtre kısmiyse ağırlık bozulur: Eğer kullanıcı 4 tanılı bir grupta yalnızca 2 tanıyı filtrelerse, ağırlıklar artık 1’e tamamlanmaz ve sonuç hatalı olur [18]. Bu durumlar için ya etki raporu kullanmak ya da grup analizi yapmak gerekir.
- Snowflake (kar tanesi) ile karıştırmayın: Snowflake bir boyutun normalleştirilmesidir, çoktan-çoğa ilişki içermez ve weighting factor’a ihtiyaç duymaz [6].
- Grupların ETL yönetimi: Yeni bir tanı kombinasyonu geldiğinde, ETL süreci bunu
bridge_diagnosis_groupiçinde yeni birdiagnosis_group_keyile satırlar olarak yazmak ve uygun grup anahtarını fact satırına basmakla yükümlü [2]. ICD kodlarının sıralı birleştirilmiş hali (örneğinI10,I50,J18) iyi bir doğal anahtar (natural key) olur — bu hash’i tutan ufak bir lookup ile aynı kombinasyon ikinci kez geldiğinde aynı grup anahtarını yeniden kullanabilirsiniz [29]. - Bridge bazen iki boyut arasındadır: Köprü tabloların yalnızca fact-dimension arasında olmadığını, dimension-dimension arasında da olabileceğini unutmayın [1][2]. Banka hesabı ile müşteri ilişkisi tam böyle bir örnek.
- Bazen fact bridge’in kendisidir: Kimball forumundaki tartışmalarda dile getirildiği gibi, iki boyutu ilişkilendiren bir tablo aslında fact-less fact tablosu da olabilir [25]; bridge ile fact-less fact arasındaki ince çizgi modelleme tercihine kalıyor.
- Bridge yerine fact’i denormalize etme: Bazı sade durumlarda, çoktan-çoğa yerine düşük satır detay seviyeli (tanı bazlı) bir fact tablosu yapıp ölçüyü orada bölmek daha pratik olabilir [7]. Yani bridge tek çözüm yolu değil; mühendislik kararı.
- Combinatorial numbering gibi yeni akademik yaklaşımlar da gündemde: çoktan-çoğa ilişkisini ayrı bir tablo olmadan tek sütunla kodlamayı öneren çalışmalar var [10]. Üretim ortamında yaygınlaşmadı ama izlemeye değer.
6. Toparlayalım
Bridge table, Kimball’ın çoktan-çoğa ilişkileri yıldız şemasının disiplini içinde modellemek için sunduğu sağlam, açık ve esnek bir tasarım deseni [1][2]. Tek başına kurarsanız çift sayım derdine düşersiniz; weighting factor ile birlikte kurarsanız hem doğru toplamı verir (weighted report) hem de “şu boyut değerine dokunan iş hacmi ne kadar?” sorusunu cevaplar (impact report) [6][17].
Bu yazıda Docker ile PostgreSQL’i tek komutla ayağa kaldırıp [13][19], yıldız şemamızı + bridge tablomuzu kurduk, örnek bir hastane faturalandırma veri setiyle yükledik ve dört farklı sorguyla çift sayım probleminin gerçekten olduğunu, weighting factor’ün de bunu nasıl düzelttiğini gözle gördük. Aynı desen sigorta, perakende (sepet etiketleri, çoklu kategori), eğitim (çoklu ana dal), insan kaynakları (çoklu beceri) gibi pek çok alana doğrudan aktarılabilir [3][9].
Konteynerlerin (containers) güzelliği şu: kodu deneyip beğenmediğinizde docker compose down -v ile ortamı bir saniyede silebiliyorsunuz. Bu yüzden modelleme alternatiflerini denemenin maliyeti çok düşük. Bridge table’ı kendi alanınızdaki bir çoktan-çoğa probleminize uyarlayıp ağırlık politikalarıyla oynayın derim — Kimball’ın dediği gibi modelleme sezgisi ancak ellerini kirleterek gelişir.
Kaynaklar
[1] Kimball Group, “Multivalued Dimensions and Bridge Tables”, https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/multivalued-dimension-bridge-table/
[2] W. Thornthwaite, “Design Tip #142: Building Bridges”, Kimball Group, https://www.kimballgroup.com/2012/02/design-tip-142-building-bridges/
[3] M. Ross, “Design Tip #166: Potential Bridge (Table) Detours”, Kimball Group, https://www.kimballgroup.com/2014/05/design-tip-166-potential-bridge-table-detours/
[4] Aventius, “Data warehousing – bridge tables, what, why, eh?”, https://aventius.co.uk/2024/04/08/data-warehousing-bridge-dimensions-what-why-eh/
[5] Sisense Community, “Many-To-Many / Multivalued Dimension”, https://community.sisense.com/t5/knowledge/many-to-many-multivalued-dimension/ta-p/8828
[6] D. Steiner, “Many to Many Hierarchies: Bridge Tables”, https://diethardsteiner.github.io/mondrian/2014/12/26/Bridge-And-Closure-Table.html
[7] D. Lai, “Handling many-to-many joins using a bridge table (Part 1)”, http://davidlai101.com/blog/2017/08/03/handling-many-to-many-joins-using-a-bridge-table-part-1/
[8] J. Simon, “Populating a many-to-many bridge table”, https://jsimonbi.wordpress.com/2011/01/25/populating-a-many-to-many-bridge-table/
[9] BigBear.ai, “Bridge Tables – Deep Dive”, https://bigbear.ai/blog/bridge-tables-deep-dive/
[10] arXiv, “Numbering Combinations for Compact Representation of Many-to-Many Relationship Sets”, https://arxiv.org/pdf/2511.02096
[11] Kimball Forum, “Weighting factor in bridge table”, https://kimballgroup.forumotion.net/t1356-weighting-factor-in-bridge-table
[12] LeapfrogBI, “Bridge Tables”, https://www.leapfrogbi.com/blog/bridge-tables/
[13] Docker Hub, “postgres – Official Image”, https://hub.docker.com/_/postgres
[14] Geshan Manandhar, “Postgres with Docker and Docker compose: a step-by-step guide for beginners”, https://geshan.com.np/blog/2021/12/docker-postgres/
[15] DataCamp, “PostgreSQL in Docker: A Step-by-Step Guide for Beginners”, https://www.datacamp.com/tutorial/postgresql-docker
[16] Kimball Forum, “Bridge table FK query”, https://kimballgroup.forumotion.net/t3078-bridge-table-fk-query
[17] Drexel University, “Unit 6 Lesson 1: Bridge Tables and Multivalued Dimensions”, https://cci.drexel.edu/faculty/song/courses/info%20607/tutorial_WESST/frmain61.htm
[18] Kimball Forum, “What to do when the weighting factor of a bridge table no longer seems relevant?”, https://kimballgroup.forumotion.net/t441-what-to-do-when-the-weighting-factor-of-a-bridge-table-no-longer-seems-relevant
[19] Docker Docs, “Pre-seeding database with schema and data at startup”, https://docs.docker.com/guides/pre-seeding/
[20] Docker Docs, “Advanced Configuration and Initialization (PostgreSQL)”, https://docs.docker.com/guides/postgresql/advanced-configuration-and-initialization/
[21] A. Suarez Aceves, “Initializing a PostgreSQL Database with a Dataset using Docker Compose”, https://medium.com/@asuarezaceves/initializing-a-postgresql-database-with-a-dataset-using-docker-compose-a-step-by-step-guide-3feebd5b1545
[22] Mkyong, “How to run an init script for Docker Postgres”, https://mkyong.com/docker/how-to-run-an-init-script-for-docker-postgres/
[23] C. Magalhães, “How to setup a PostgreSQL database with Docker Compose”, https://blog.cadumagalhaes.dev/how-to-setup-a-postgresql-database-with-docker-compose
[24] M. Smagulova, “Multivalued Dimensions and Bridge Tables”, Medium, https://medium.com/@meruert.sm/multivalued-dimensions-and-bridge-tables-9dde5001988c
[25] Kimball Forum, “Difference between factless fact and bridge table”, https://kimballgroup.forumotion.net/t1496-difference-between-factless-fact-and-bridge-table
[26] Kimball Forum, “How do you properly model with a bridge table”, https://kimballgroup.forumotion.net/t2814-how-do-you-properly-model-with-a-bridge-table
[27] Kimball Forum, “Weighting factor”, https://kimballgroup.forumotion.net/t1530-weighting-factor
[28] dwbi1, “Bridge table”, https://dwbi1.wordpress.com/2019/03/22/bridge-table/
[29] dimodelo, “Modeling Many to Many Relationships in a Star Schema”, https://dimodelo.substack.com/p/modeling-many-to-many-relationships-in-a-star-schema
[30] OneUptime, “How to Set Up PostgreSQL with Docker”, https://oneuptime.com/blog/post/2026-02-02-postgresql-docker-setup/view
[31] Kapak Görseli: Photo by Ant Rozetsky on Unsplash