
![]()
Sevgili VBO okuyucuları, yeniden merhaba! Bu yazımda sizlere word2vec’ten bahsedeceğim ve daha iyi açıklayabilmek adına Python programlama dili ile küçük bir uygulama yapacağım. Projeyi yazarken nltk ve gensim kütüphanesini kullanacağım eğer nltk hakkında bilgi edinmek istiyorsanız bir önceki yazıma bakabilirsiniz. Keyifli okumalar dilerim. 🙂
Doğal dil işleme çalışmaları, büyük veri kavramına paralel olarak metin verilerinin artmasıyla birlikte son dönemlerde daha da önemli hale gelmiş yapılan çalışmalar ile oldukça popüler olmuştur. Metin sınıflandırma, duygu analizi, makine diline çeviri, bilginin çıkarılması, özetleme, soru-cevap sistemlerinin geliştirilmesi gibi çalışma alanlarında doğal dil işleme teknikleri kullanılmaktadır.
Metin sınıflandırma problemi, doğal dil işleme alanında en çok üzerinde durulan çalışmalardan biridir. Başta İngilizce olmak üzere bir çok dünya dilinde metin verileri ile çeşitli çalışmalar yapılmaktadır fakat Türkçe dili için bu sayı yetersizdir.
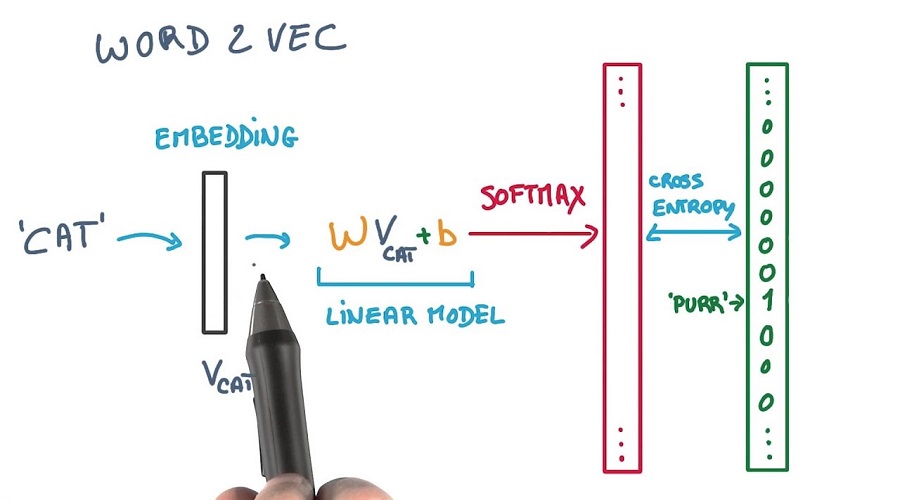
Word2Vec, kelime temsil (word embedding) yöntemidir. Peki kelime temsil yöntemi nedir?
Kelime Temsil (Word Embedding) : Metin verisi üzerinde çalışabilmek için öncelikle veriyi makinenin anlayacağı hale getirmemiz gerekiyor, işte burada kelime temsil (word embedding) yöntemleri devreye giriyor. Kelime temsil yöntemleri bir dil modelleme tekniğidir, sözcükleri veya cümleleri sayısallaştırıp birer vektör haline getiriyor böylelikle veri vektör uzayında temsil ediliyor.
Kelime temsil (word embedding)’i yapay sinir ağları, olasılık modelleri vb. gibi yöntemler kullanılarak üretilebilir.
Peki word2vec nedir, hangi yöntem ile üretilmiştir?
Word2Vec; tahmin tabanlı (prediction-based) kelime temsil yöntemi olup, 2013 yılında Google araştırmacısı Thomas Mikolov ve ekip arkadaşları ile birlikte temelinde yapay sinir ağı ile iki farklı model kullanarak kelimelerin eğitilmesi amaçlanıp geliştirilmiştir.
Word2Vec’in kullandığı iki model CBOW(Continuous Bag of Words) ve Skip-Gram Model’dir. Bu iki modelin mimarisini inceleyecek olursak:
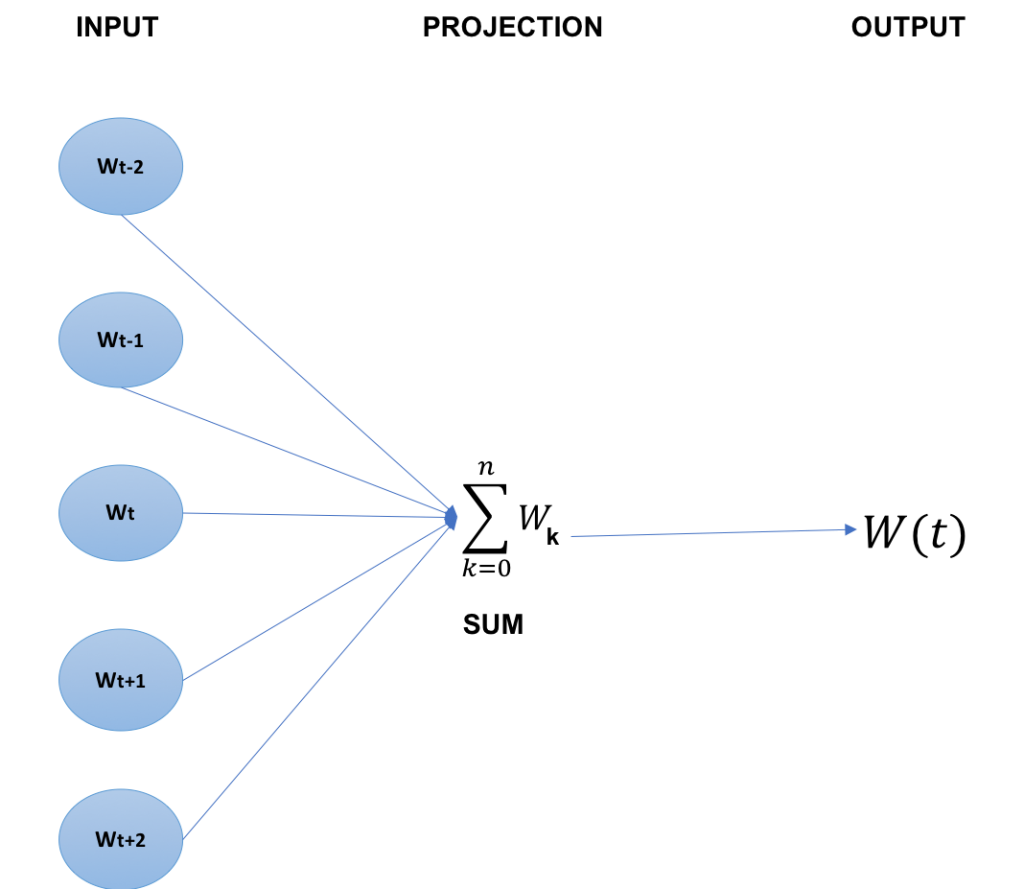
- Continuous Bag of Words: CBOW modelinde pencere boyutu merkezinde olmayan kelimeler girdi olarak alınıp, merkezinde olan kelimeler çıktı olarak tahmin edilmeye çalışılmaktadır. Bu durum aşağıdaki şekilde gösterilmeye çalışılmıştır. Burada w(t) ile gösterilen değer, cümlenin merkezinde bulunan ve tahmin edilmek istenen çıktı değeri iken, w(t-2)…..w(t+2) ile gösterilen değerler ise tercih edilen pencere boyutuna göre merkezde olmayan çıktı değerleridir.
Vektörler arasındaki benzerlik şartlı olasılık formülüne göre hesaplanır:
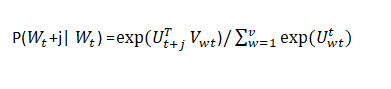
Eğitim sırasında CBOW için optimize edilecek hata fonksiyonu şöyledir:
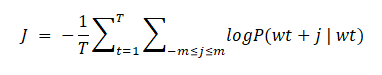
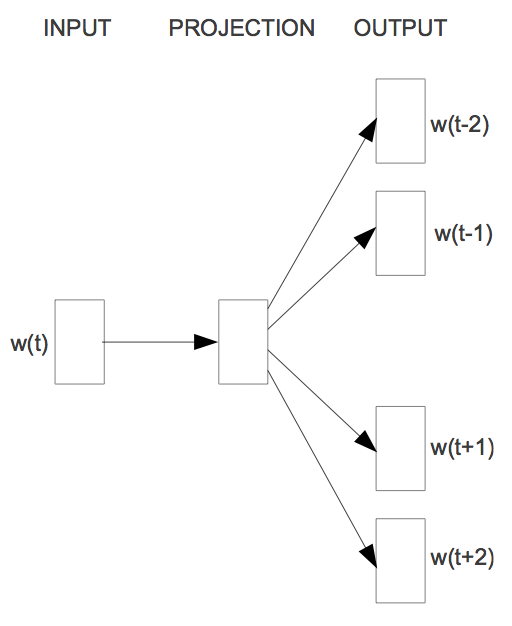
- Skip Gram: Skip Gram modelinde pencere boyutu merkezinde olan kelimeler girdi olarak alınıp, merkezinde olmayan kelimeler çıktı olarak tahmin edilmeye çalışılmaktadır.Bu durum aşağıdaki şekilde gösterilmeye çalışılmıştır. Burada w(t) ile gösterilen değer, cümlenin merkezinde bulunan ve girdi değeri iken, w(t-2)…..w(t+2) ile gösterilen değerler ise cümlenin merkezinde olmayan tercih edilen pencere boyutuna göre tahmin edilmek istenen çıktı değerleridir.
Skip Gram model ve CBOW arasındaki tek fark Skip Gram modelin CBOW’un tam tersi olmasıdır. Yani, yapay sinir ağında çıktılar ve girdilerin yeri değiştirmektedir.
Eğitim sırasında Skip Gram Model için optimize edilecek hata fonksiyonu şöyledir:
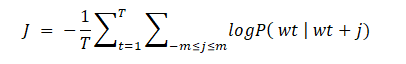
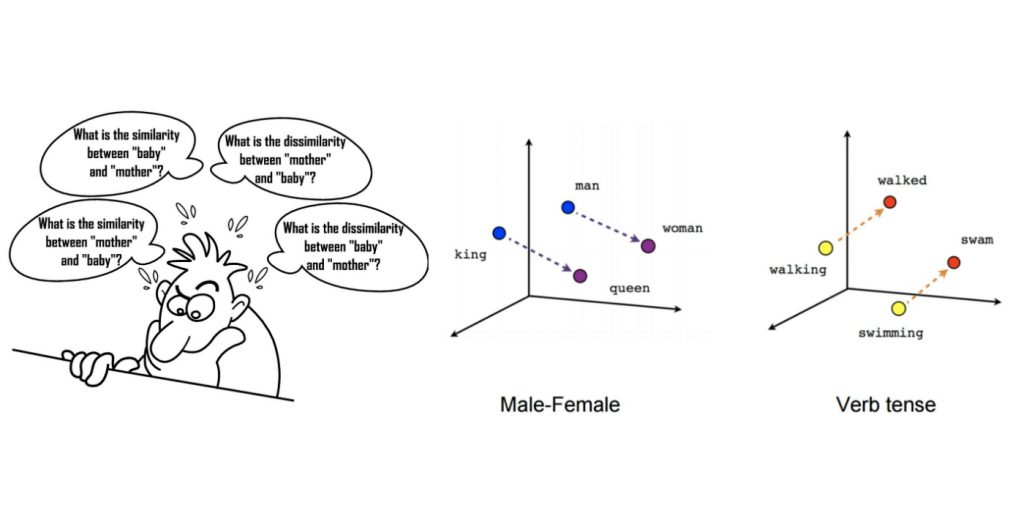
Word2Vec modelinin en büyük avantajı kelimelerin cümle içerisindeki pozisyonlarına göre şartlı olasılık prensibi çalışma mantığından dolayı kelimeler arasındaki yakınlıkların kaybolmamasıdır.
Kelime temsil (word embedding) yöntemi hakkında teoride aklımızda bir şeyler oluşmuştur diye düşünüyorum. Bu iki model için yapay sinir ağını satır satır kodlayabilir ve çalıştırabilirsiniz. Skip gram model için şu siteye bakabilirsiniz. Ben tek tek kodlama yerine hali hazırda word2vec modelini içeren gensim adındaki kütüphaneyi kullanacağım.
Gensim, modern istatistiksel makine öğrenimini kullanarak denetlenmeyen konu modellemesi ve doğal dil işleme için açık kaynaklı bir kütüphanedir. Gensim Python ve Cython’da uygulanmaktadır.
Google Colab’ı kullanarak word2vec için yazdığım proje aşağıdadır. Bu projenin amacı kelimelerin birbiri ile olan yakınlık ilişkisini inceleyerek metin sınıflandırma ya da metin özetleme gibi problemlerde bize yardımcı olmasını sağlamak.
Gensim kütüphanesinde veriyi eğitebilmek için bir takım parametrelere ihtiyaç vardır, bu parametreleri ve anlamlarını aşağıdaki tabloda görebilirsiniz.
| Parametre | Alabileceği Değer Aralığı | Açıklama | Kullanılan Değer |
| sentences | Model için oluşturulmuş, ön işlemden geçirilmiş kelimeler listesidir. | Modelin eğitilmesi için kullanılan veri kümesidir. | Derlem |
| size | Opsiyonel olarak integer değer alır. | Kelime vektörlerinin boyutudur. | 300 |
| window | Opsiyonel olarak integer değer alır. | Bir cümle içindeki mevcut ve tahmin edilen kelime arasındaki maksimum mesafedir | 10 |
| min_count | Opsiyonel olarak integer değer alır. | Parametre değerinden daha düşük frekanstaki tüm kelimeler yok sayılır | 1 |
| sg | 0 ve 1 değerlerini alır. | Skip-gram yöntemiyle eğitim için 1, CBOW yöntemi için 0 değeri kullanılır | Çalışmada iki yöntemde kullanılmıştır.(0 ve 1) |
| alpha | Opsiyonel olarak float değer alır. | Başlangıç öğrenme oranıdır. | 0,25 |
pip install nltk
Requirement already satisfied: nltk in /usr/local/lib/python3.6/dist-packages (3.2.5)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from nltk) (1.12.0)nltk.download('punkt')
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
Truepip install gensim
Requirement already satisfied: gensim in /usr/local/lib/python3.6/dist-packages (3.6.0)
Requirement already satisfied: six>=1.5.0 in /usr/local/lib/python3.6/dist-packages (from gensim) (1.12.0)
Requirement already satisfied: numpy>=1.11.3 in /usr/local/lib/python3.6/dist-packages (from gensim) (1.17.4)
Requirement already satisfied: scipy>=0.18.1 in ......nltk.download('stopwords')[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
TrueYukarıda gördüğünüz gibi proje için gerekli bütün kütüphaneleri indirdim.
import nltk import gensim
# Python program to generate word vectors using Word2Vec
# importing all necessary modules
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
warnings.filterwarnings(action = 'ignore')
import gensim
from gensim.models import Word2Vec
stopWords = set(stopwords.words('turkish'))
sentence= """
Antalya Valisi Münir Karaloğlu, kırmızı kodlu uyarının yapıldığı Antalya'da gece yarısında yağışın hızlanacağını belirterek,
"Kriz merkezinin yönettiği bin 452 personel hazır durumda. 213 ekibimiz var, 252 iş makinesi ve 124 kamyonla olayı takip ediyoruz." dedi.
"""
data = []
# iterate through each sentence in the file
for w in sent_tokenize(sentence):
temp = []
# tokenize the sentence into words
words = word_tokenize(sentence)
for w in words:
if w not in stopWords:
temp.append(w)
data.append(temp)
Öncelikle veriyi herhangi bir haber sitesinden deneme amaçlı bir paragraflık olacak şekilde aldım. Veriyi ön işlemeden geçirip eğitim için hazır hale getirdim.
Elimdeki verinin son halini görselleştirdim.
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = []
for i in sentence:
text.append(i)
text = ''.join(map(str, text))
wordcloud = WordCloud(width=6000, height=1000, max_font_size=300,background_color='white').generate(text)
plt.figure(figsize=(20,17))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
# Create CBOW model
model1 = gensim.models.Word2Vec(data, min_count = 1, size = 200, window=10, alpha=0.25)
# Print results
print("Cosine similarity between 'kodlu' " +
"ve 'uyarının' - CBOW : ",
model1.similarity('kodlu','uyarının'))
print("Cosine similarity between 'kodlu' " +
"ve 'yapıldığı' - CBOW : ",
model1.similarity('kodlu','yapıldığı'))
# Create Skip Gram model
model2 = gensim.models.Word2Vec(data, min_count=1, size = 300, alpha=0.025, window = 10, sg = 1)
# Print results
print("Cosine similarity between 'kodlu' " +
"ve 'uyarının' - Skip Gram : ",
model2.similarity('kodlu','uyarının'))
print("Cosine similarity between 'kodlu' " +
"ve 'yapıldığı' - Skip Gram : ",
model2.similarity('kodlu','yapıldığı'))
Cosine similarity between 'kodlu' ve 'uyarının' - CBOW : -0.039434817
Cosine similarity between 'kodlu' ve 'yapıldığı' - CBOW : 0.080858305
Cosine similarity between 'kodlu' ve 'uyarının' - Skip Gram : -0.052302007
Cosine similarity between 'kodlu' ve 'yapıldığı' - Skip Gram : 0.073610365Gensim kütüphanesini kullanarak veriyi eğittim. Sonuçlar yukarıda gördüğünüz gibidir.
İyi bir sonuç elde edebilmek için elimdeki veriyi karşılaştıracak daha büyük bir veri setine ihtiyacım var. Burada bir paragraflık veriyi rahat bir şekilde inceleme fırsatı bulabilelim diye kullandım, siz dilerseniz TSCorpus sitesinden Türkçe veri seti indirebilir ve deneme yapabilirsiniz.
Elimden geldiğince bildiklerimi aktarmaya çalıştım umarım sizler için faydalı bir yazı olmuştur, değerli yorumlarınızı bekliyorum. Seneye görüşmek üzere 😉
Kaynaklar: https://www.geeksforgeeks.org/python-word-embedding-using-word2vec/ https://radimrehurek.com/gensim/auto_examples/index.html
Burada kütüphane kullanmanın yolunu göstermişsiniz. Önemli olan bu verinin yorumu. Veriler nasıl yorumlanır? Daha çok veri olsaydı nasıl yorumlanması gerekirdi?