
Utku Kubilay ÇINAR Beni...

Merhaba, Bir önceki yazımda Birliktelik...

Merhabalar, Bu gün sizlere pythonda...
Merhaba, Uzun bir aradan sonra...
Merhabalar, Makine Öğrenmesine Giriş Serisi'nin...

Yapay Sinir Ağları ve R...

Makine öğrenmesi ve istatistiksel öğrenme...

Merhaba. Bu yazımızda son yıllarda...

[latexpage] Çoklu regresyon analizinde bağımsız niteliklerin bağımlı...

Outlier Analysis Methods'e girmeden önce...

1. Giriş Merhabalar. Bildiğimiz gibi Spark,...

1. Enseble Yöntemler Nedir? Bir...

K-Fold Cross Validation, sınıflandırma modellerinin...

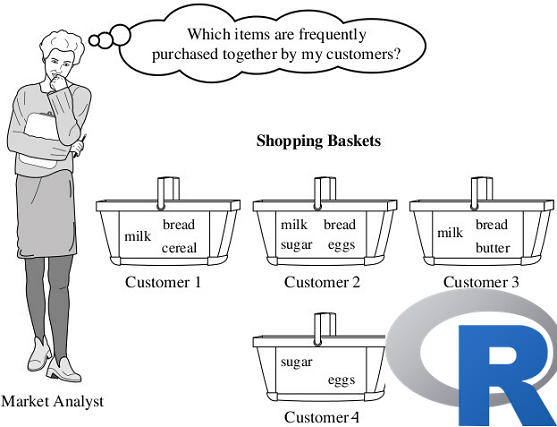
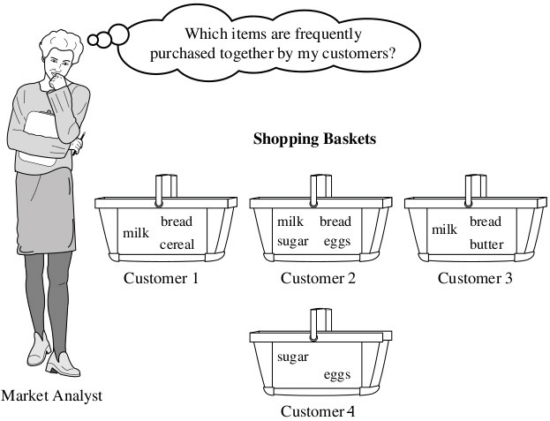
Bu yazımızda birliktelik kurallarının en...

"Bunu alan şunları da aldı"...

Kümeleme ve hiyerarşik kümelemede ilerlemeye...

Bir önceki yazımızda hiyerarşik kümelemeden...

Hiyerarşik kümeleme de K-Ortalamalar tekniği...

Daha önceki üç yazıda kümeleme...

Kümeleme serimizin son iki yazısında...