
Lineer Regresyon Notlarımıza devam ediyoruz. Bu yazımızda Python ile çoklu lineer regresyon uygulaması yapacağız. Teorik olarak ilk dört yazıda iyi kötü bir şeyler söyledik. Burada teoriden bahsetmeyeceğim. Öncelikle olayı anlamak adına elimizdeki veri seti nedir, kuracağımız model ile neyi çözmeyi amaçlıyoruz, hangi nitelikler hangi değişkenlerle eşleşiyor biraz bahsetmek istiyorum. Önce veri setimizi indirip Spyder’ın yakışıklı Variable Explorer penceresinden bir bakalım. Veri setini buradan indirip çalışma dizninize kopyalayınız.
Kütüphaneleri İndirme, Çalışma Diznini Ayarlama ve Veri Setini İndirme
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir('Sizin_Calisma_Dizniniz')
dataset = pd.read_csv('Sirketler_Kar_Bilgileri.csv')
Veriyi Anlamak
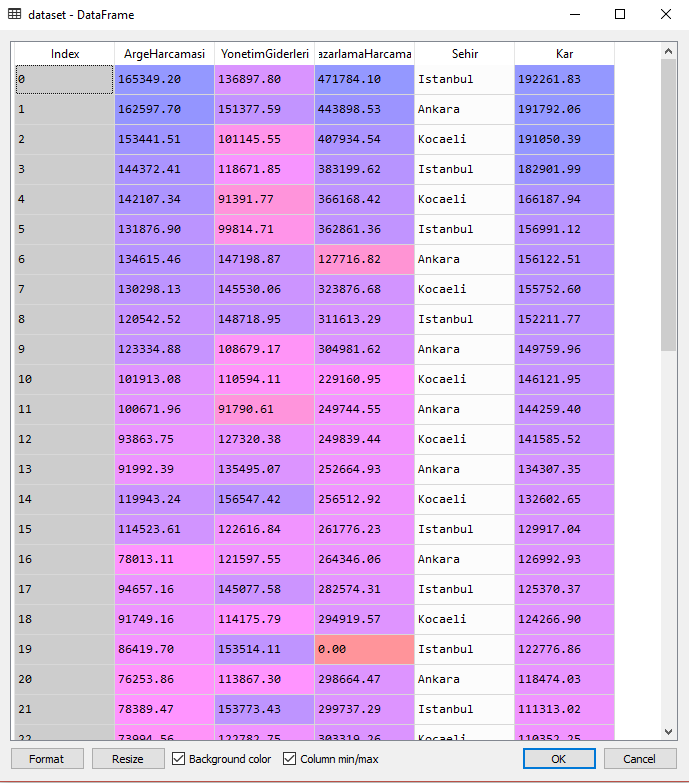
Yukarıdaki tabloda niteliklerimizi görüyoruz:
ArgeHarcamasi: Şirket tarafından araştırma döneminde yapılmış ARGE harcamaları. Nitelik türü nümerik.
YonetimGiderleri: Araştırma döneminde şirketin yönetimi için yapılan idari harcamalar. Nitelik türü nümerik.
PazarlamaHarcamasi: Araştırma döneminde şirketin pazarlam faaliyetleri için yaptığı harcamalar. Nitelik türü nümerik.
Sehir: Şirketin faaliyetini yürüttüğü şehir. Nitelik türü kategorik, sırasız.
Kar: Araştırma döneminde şirketin elde ettiği kar. Nitelik türü nümerik.
Özetle, veri setimizde toplam 5 nitelik ve 50 gözlem (şirket) var.
Nitelikleri ve değişken türlerini görünce kafamızda hemen bir araştırma problemi oluşmuştur sanırım. Bingo! Şirketlerin çeşitli harcama kalemleri ile elde ettikleri kar arasındaki ilişkiyi modelleyeceğiz. ArgeHarcamasi, YonetimGiderleri, PazarlamaHarcamasi ve Sehir bağımsız değişkenleri oluştururken; Kar bağımlı değişkeni oluşturmaktadır. Eğer elde veri varsa bu değişkenlere sosyal sorumluluk projesi, eğitim harcamaları gibi diğer bütçe kalemleri de eklenebilir.
Burada araştırma sorusu şöyle olabilir: X ülkesinde, Y sektöründe ve A,B,C şehirlerinde faaliyet gösteren Z ölçeğinde/büyüklüğündeki şirketlerin çeşitli harcamalarıyla karı arasındaki ilişki nedir? Benzer özelliklere sahip bir şirket gelecek dönem harcama planını yaparken karını maksimum kılacak şekilde harcama/gider kalemlerine ne kadar bütçe ayırmalıdır?
Bağımlı ve Bağımsız Değişkenleri Oluşturmak
Bağımsız değişkenlerimizi nitelikler matrisi olarak X değişkeninde, bağımlı değişkenimizi de vektör olarak y değişkeninde saklayalım:
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
Yukarıdaki kodlarla; dataset’ten en sondaki (-1 indeksli) yani Kar sütununu çıkar ve X değişkenine ata derken ikinci satırda dataset’teki sadece en sondaki (4 indeksli) yani Kar sütununu al ve y değişkenine ata demiş oluyoruz.
Kategorik Niteliği Dönüştürmek
Her şey çok güzel yalnız biz X’e 3 nümerik nitelik ile beraber şehir isimlerinin olduğu bir kategorik nitelik de atadık. Ne yapacağız şimdi? Regresyonda geçer akçe nümerik ve sürekli değişkenler. Bu sebeple bu kategorik niteliğin icabına bakmamız lazım. Kategorik değişkenimiz sırasız değişken olduğu için gölge değişken kullanarak kodlamak durumundayız. Şayet sıralı bir kategorik değişken olsaydı (Örn.: küçük, orta, büyük) label encoder kullanacaktık. Bu yazıda kategorik niteliğin dönüştürülmesi ile ilgili detaylı bilgi bulabiliriz. Dönüştürme işlemi için kodlarımız şu şekilde olacak:
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() X[:, 3] = labelencoder_X.fit_transform(X[:, 3]) onehotencoder = OneHotEncoder(categorical_features = [3]) X = onehotencoder.fit_transform(X).toarray()
Yukarıdaki kodlarla neler oldu özetleyelim: İlk satırda kütüphaneleri indirdik. İkinci satırda LabelEncoder sınıfından labelencoder_X adında bir nesne yarattık ki ilk dönüştürme işini deruhte edecek zatı muhterem budur. Üçüncü satırda X nitelikler matrisinin 3’üncü indekste bulunan sütununa (Sehir sütunu) labelencoder_X nesnemizin fit_transform() metoduyla yine kendisini parametre vererek atadık. Yani burada işin Türkçesi şehir isimleri gitti yerlerine rakamlar geldi. Şayet niteliğimiz sıralı kategorik olsa idi işi burada bırakacak idik. Maalesef değil! O halde gölge değişkenler yaratarak bu sırasızlık sorununu çözmek lazım. Şimdi burada bu sırasızlığı bir daha açıklamak isterim: Şimdi biz labelencoder ile Ankara’ya 0, Istanbul’a 1 ve Kocaeli’ye 2 kodladk. Eee ne var bunda yani? Şu var Ankara ile Istanbul kelimeleri arasında herhangi bir sıralama, küçüklük büyüklük bahis mevzuu değil ancak bunlara 1,2 diye rakamlar verince Istanbul Ankara’nın iki katı gibi abuk bir sonuç çıkıyor. İşte bu sebepledir ki gölge değişkenler oluşturuyoruz. Daha sonra dördüncü satırda OneHotEncoder sınıfından onehotencoder isimli nesneyi oluşturuyoruz. Burada nesne oluştururken sınıfın ana yapıcısına (constructor – bak sen çömez veri bilimciye neleri de bilirmiş 🙂 ) “bak sana birazdan bir veri seti gelecek onun 3’üncü indeksinde bulunan sütununa işlem yap emi!” diyoruz. Beşinci satırda onehotencoder fit_transform() nesnesi X nitelikler matrisini parametre olarak alıyor ve gölge değişkenler oluşturuyor. Yeni matrisi eskisinin üzerine yazıyoruz.
Spyder Variable Explorer’dan orijinal veri setini ve dönüştürülmüş X nitelikler matrisini karşılaştıralım:
Yukarıdaki resimde soldaki tablo orijinal veri setini sağdaki ise dönüştürme sonrası X nitelikler matrisini (bağımsız değişkenler matrisi) görmekteyiz. Gölge değişkenler 0,1,2 indeksinde yerini almış. Ankara 0, Istanbul 1 ve Kocaeli 2 indeksini almış. 3’te ise ArgeHarcamasi, 4 YonetimGiderleri, 5 PazarlamaHarcamasi var.
Gölge değişken tuzağından kaçınmak
Gölge değişkenler yaratmak regresyon modelinde çoklu bağlantıya sebep olabilir ki bu durum regresyon modellerinde istenmeyen bir durumdur. Çoklu bağlantıyı kısaca şöyle açıklayabiliriz: bağımsız değişkenlerden iki veya daha fazlası arasında aşırı yüksek korelasyon olması durumudur. Gölge değişkenlerin çoklu bağlantıya sebep olmasına gölge değişken tuzağı (dummy variable trap) deniliyor. Bunu önlemenin yolu gölge değişkenlerden birisini düşürmektir. Örneğimizden gidecek olursak ben Kocaeli’yi düşürdüm diyelim. Eğer bir sırada Ankara ve İstanbul’un değerleri 0 ise düşürmüş de olsak bu durum Kocaeli’nin 1 olduğu anlamına gelecektir. Çünkü her halükarda gölge değişkenlerden en fazla/en az bir tanesi 1 değerine sahip olmak durumundadır. Basit bir kod ile bu tuzaktan kurtulalım:
X = X[:,1:]
Yukarıdaki kodla X nitelikler matrisindeki tüm satırları (birinci : onu ifade ediyor) ve 1’inci sütun dahil olmak üzere sona kadar tüm sütunları (1: bunu ifade ediyor) tekrar X’e ata demiş oluyoruz. Yani 0 indeksli sütunu düşürmüş oluyoruz. Gitti Ankara, yukarıda da Kocaeli’yi örnek vermiştik. Neyse sağlık olsun. Aslında bir çok Python kütüphanesi bu tuzağı fark edip tedbir alıyor ama öğrenmek adına burada elle yapmış olduk.
Veriyi Eğitim ve Test Olmak Üzere İkiye Bölmek
Burada çok açıklama yapmadan hemen kodlara yer vereceğim. Bu kısımla ilgili daha detaylı açıklamayı veri ön işleme yazımda bulabilirsiniz. Veri setinde 50 kayıt vardı bunlardan 40’ını eğitim 10 tanesini de test için kullanalım.
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
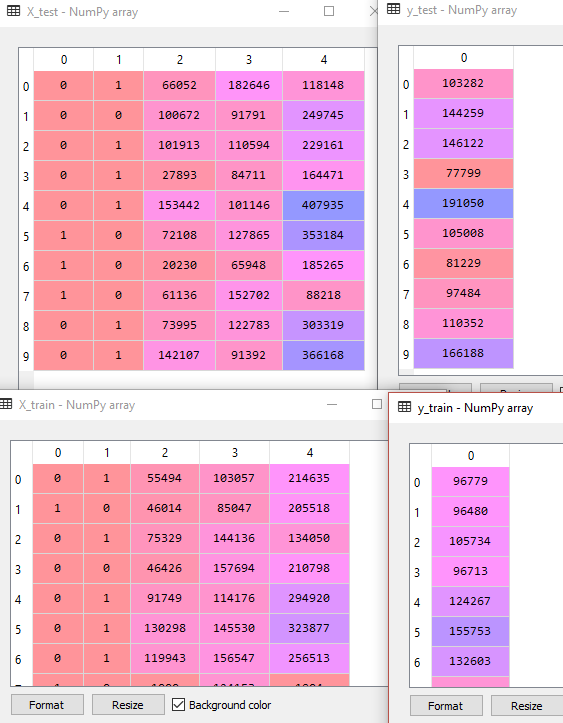
Yukarıda Spyder’ın Variable Explorer penceresinde eğitim ve test olarak parçalara ayrılmış değişkenlerimizin tablo görüntüsü bulunmaktadır. Burada eğitim setlerinde gölge değişken tuzağı için düşürdüğümüz bir sütunun bulunmadığına dikkat ediniz. Bir sonraki yazıda devam edeceğim. Veriyle kalın…