
Lineer Regresyon Notlarımıza devam ediyoruz. Son iki yazıda Python ile yaptığımız çoklu lineer regresyonu bu yazımızda R ile yapacağız. Teorik olarak Lineer Regresyon Notları ilk dört yazıda iyi kötü bir şeyler söyledik. Burada teoriden bahsetmeyeceğim. Öncelikle olayı anlamak adına elimizdeki veri seti nedir, kuracağımız model ile neyi çözmeyi amaçlıyoruz, hangi nitelikler hangi değişkenlerle eşleşiyor biraz bahsetmek istiyorum. Önce veri setimizi indirip R’ın view() fonksiyonuyla tablo halinde veri setimizi görelim. Veri setini buradan indirip çalışma dizninize kopyalayınız. Çalışma dizninizi setwd() ile ayarlamayı unutmayınız.
dataset = read.csv('Sirketler_Kar_Bilgileri.csv')
View(dataset)

Veriyi Anlamak
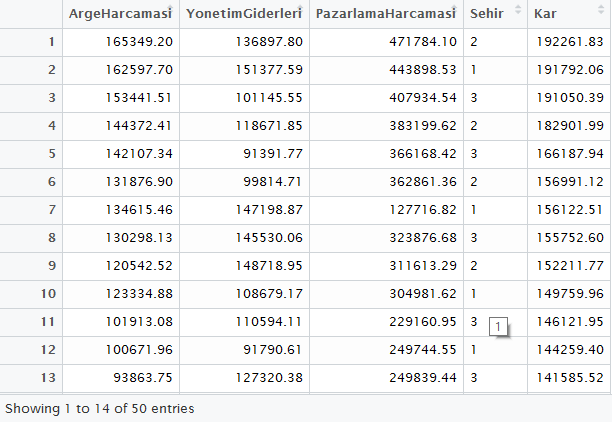
Yukarıdaki tabloda niteliklerimizi görüyoruz:
ArgeHarcamasi: Şirket tarafından araştırma döneminde yapılmış ARGE harcamaları. Nitelik türü nümerik.
YonetimGiderleri: Araştırma döneminde şirketin yönetimi için yapılan idari harcamalar. Nitelik türü nümerik.
PazarlamaHarcamasi: Araştırma döneminde şirketin pazarlam faaliyetleri için yaptığı harcamalar. Nitelik türü nümerik.
Sehir: Şirketin faaliyetini yürüttüğü şehir. Nitelik türü kategorik, sırasız.
Kar: Araştırma döneminde şirketin elde ettiği kar. Nitelik türü nümerik.
Özetle, veri setimizde toplam 5 nitelik ve 50 gözlem (şirket) var.
Nitelikleri ve değişken türlerini görünce kafamızda hemen bir araştırma problemi oluşmuştur sanırım. Bingo! Şirketlerin çeşitli harcama kalemleri ile elde ettikleri kar arasındaki ilişkiyi modelleyeceğiz. ArgeHarcamasi, YonetimGiderleri, PazarlamaHarcamasi ve Sehir bağımsız değişkenleri oluştururken; Kar bağımlı değişkeni oluşturmaktadır. Eğer elde veri varsa bu değişkenlere sosyal sorumluluk projesi, eğitim harcamaları gibi diğer bütçe kalemleri de eklenebilir.
Burada araştırma sorusu şöyle olabilir: X ülkesinde, Y sektöründe ve A,B,C şehirlerinde faaliyet gösteren Z ölçeğinde/büyüklüğündeki şirketlerin çeşitli harcamalarıyla karı arasındaki ilişki nedir? Benzer özelliklere sahip bir şirket gelecek dönem harcama planını yaparken karını maksimum kılacak şekilde harcama/gider kalemlerine ne kadar bütçe ayırmalıdır?
Kategorik Niteliği Dönüştürmek
Her şey çok güzel yalnız biz veri setinde nümerik nitelik ile beraber şehir isimlerinin olduğu bir kategorik nitelik de görüyoruz. Ne yapacağız şimdi? Bunca zabitin arasında gediklinin işi ne? Regresyonda geçer akçe nümerik ve sürekli değişkenlerdir. Bu sebeple bu kategorik niteliğin icabına bakmamız lazım, vurun gedikliye yaşatman! Dönüştürme işlemi için kodlarımız şu şekilde olacak:
dataset\$Sehir = factor(dataset\$Sehir,
levels = c('Ankara','Istanbul','Kocaeli'),
labels = c(1,2,3))
View(dataset)
Gördüğümüz gibi işlem sonrası Sehir niteliği kategorikten nümeriğe dönüşmüş. Ankara 1, Istanbul 2, Kocaeli 3 olmuş.
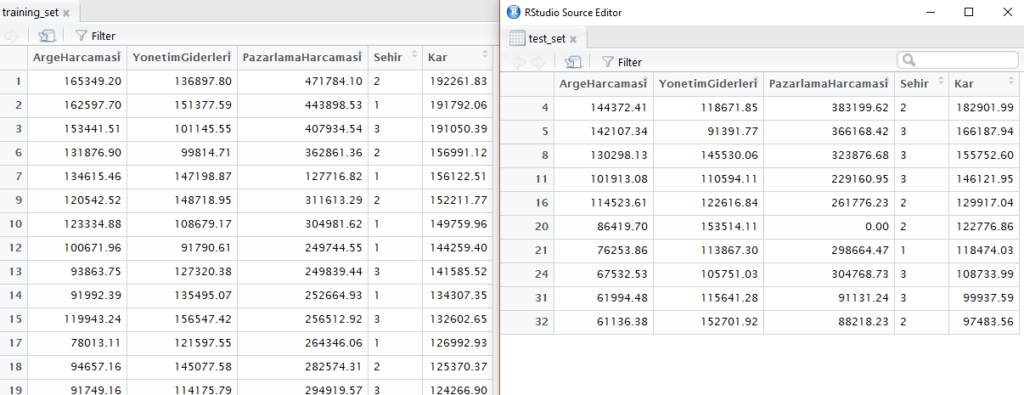
Veriyi Eğitim ve Test Olmak Üzere İkiye Bölmek
Modeli eğitmek ve test etmek için veriyi ikiye ayıracağız. 50 kayıt var. 40 eğitim için, 10 test için ayıralım. Bunun için; caTools kütüphanesini yükleyeceğiz, rastgele örnekleme temel olacak bir rakam belirleyeceğiz seed(123), verinin %80’ini eğitim seti olacak şekilde ayırıyoruz. sample.split() metoduna ilk parametre olarak hedef niteliği (Kar) veriyoruz. Bu mteod eğitim için seçilenlere TRUE, test için seçilenlere FALSE işaretini koyar. training_set ve test_set‘i bu işaretlere göre subset() fonksiyonu ile ayırıp oluşturduk.
library(caTools) set.seed(123) split = sample.split(dataset\$Kar, SplitRatio = 0.8) training_set = subset(dataset, split == TRUE) test_set = subset(dataset, split == FALSE)
Kontrol edelim:
View(training_set) View(test_set)
Modeli Eğitme
Regresyon modelini kuruyoruz:
regressor = lm(formula = Kar ~ ArgeHarcamasi + YonetimGiderleri + PazarlamaHarcamasi + Sehir,
data = training_set)
Yukarıda gördüğümüz gibi Kar’ı bağımlı değişkenden sonra tilda ekledik ve bağımsız değişkenleri toplayarak yan yana yazdık. Böyle uzun kod yazımını kısaltmak için R’ın pratik çözümü var. Tüm bağımsız değişkenleri tek bir nokta ile temsil edebiliyoruz.
regressor = lm(formula = Kar ~ ., data = training_set)
Modelimizi eğittik. Şimdi sonuçları inceleyelim:
summary(regressor)
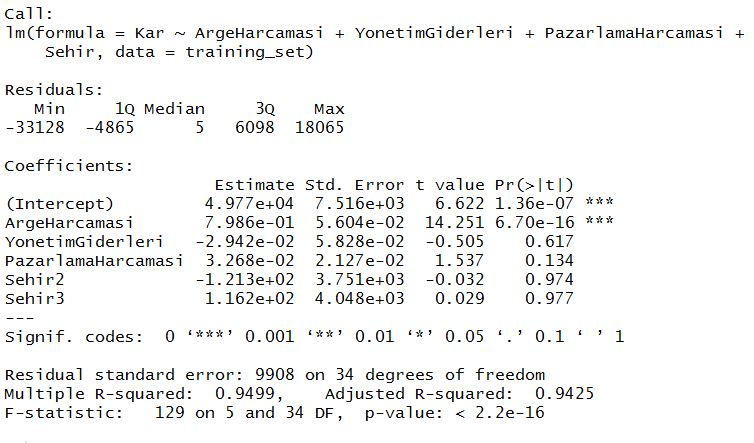
Sehir2 ve Sehir3’ü aslında biz belirtmedik. Yukarıdaki lineer modelde bağımsız değişkenler arasında sadece Sehir olarak bildirmiştik. Peki nereden çıktı bu Sehir1 ve Sehir2? Gölge değişken. Sehir niteliğimiz kategorik olduğundan onu nümerik yapmıştık. Hatırlarsanız bunu da factor() fonksiyonu ile yapmıştık. İşte lineer model (lm) bu niteliğin kategorikten çevirme olduğunu anladı, gölge değişken tuzağına düşmemek için de birini düşürdü ve geriye kalan ikisini (Sehir2, Sehir3) modele koydu. Bu yazımızda bu işi elle yapmıştık.
Geriye doğru eleme yöntemi ile optimum modeli bulmak
İlk adım;
Geriye doğru eleme yönteminde ilk adım anlamlılık düzeyini belirlemektir, 0.05 olsun.
İkinci adım;
Tüm değişkenler modele dahil edilir, ettik.
Üçüncü adım;
Her bir bağımsız değişkenin anlamlılık düzeyi incelenir. Eğer anlamlılık düzeyi model için belirlenenden (0.05 kabul ettik) daha büyük ise bu bağımsız değişken modelden çıkarılır. Eğer birden fazla var ise bu işlem en büyük p değerine sahip olana uygulanır. Şayet bütün p değerleri sınır değerden küçük ise model tamam demektir. Yukarıdaki model özetinde p değerlerini incelediğimizde Sehir3 0.977 değeriyle en büyük p değerine sahip ve anlamlılık düzeyinden büyük. Öyleyse Sehir3‘ü çıkararak modeli tekrar çalıştırmalıyız. Hatta Sehir2‘nin de p değeri anlamlılık sınırımızı aşıyor modeli ber dah bir daha çalıştırmayalım. Yalnız modeli bu sefer eğitim setinde değil de orijinal veri setinde çalıştıralım. Ne de olsa daha fazla elemanı var.
regressor = lm(formula = Kar ~ ArgeHarcamasi + YonetimGiderleri + PazarlamaHarcamasi,
data = dataset)
summary(regressor)
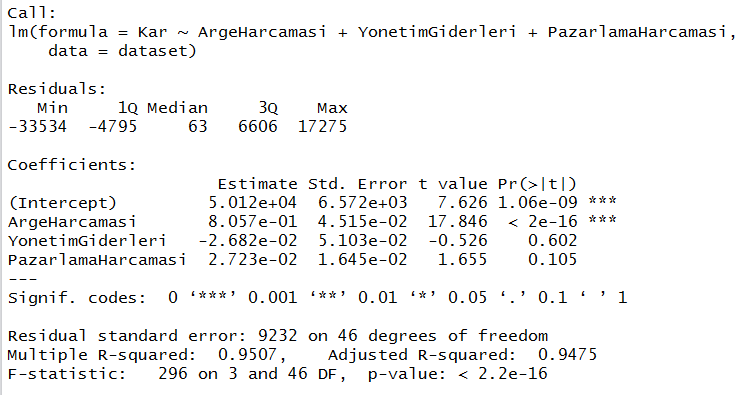
Sehir gitti. Şimdi bir sonraki en yüksek p değerine sahip bağımsız değişkeni modelden çıkarıyoruz. 0.602 ile YonetimGiderleri kuzu gibi orada yatıyor. Gel bakalım aslanım, seni dışarı alalım, hadi yallah ormana…
regressor = lm(formula = Kar ~ ArgeHarcamasi + PazarlamaHarcamasi,
data = dataset)
summary(regressor)
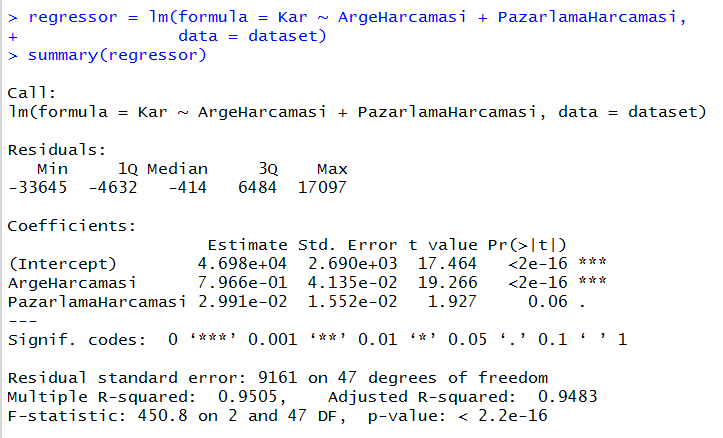
Evet, aynen Python’da olduğu gibi burada da PazarlamaHarcamasi kıl payı anlamlılık düzeyinin üzerinde kalıyor. PazarlamaHarcamasi’nı model dışına çıkarmasak da olur. Şimdilik çıkaralım.
regressor = lm(formula = Kar ~ ArgeHarcamasi, data = dataset) summary(regressor)
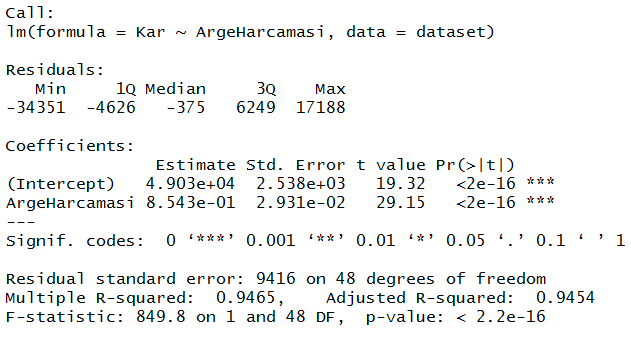
Böylece geriye doğru eleme yöntemiyle anlamlı ve en optimal model seçilmiş oldu. Ancak model seçiminde başka değerlere de bakmalıyız. Örneğin düzeltilmiş R2 (Adjusted R-squared). PazarlamaHarcamasi çıkmadan önce 0.9483 olan R2 m, çıktıktan sonra 0.9454’e düşmüş. Çıkmadan önce biraz ArgeHarcaması ve Sabit (Intecept) katsayısından yemiş. Çıkınca onun katsayı puanları biraz kalanlara yaramış. Baktığımızda katsayı olarak ArgeHarcamasi’na nispeten bağımsız değişken üzerinde etkisi çok çok az.