
![]()
Daha anlaşılır olması için şöyle basit bir örnek yapalım. Aşağıda y_pred tahmin sonuçlarını, y_test gerçek sonuçları ve Sonuç ise hata matrisindeki karşılığı ifade etsin. Bu tabloyu tamamen kafadan attık. Çünkü en baştan veri oluştur, böl, eğit, test et vs. uğraşmayalım doğrudan hata matrisine dalalım istedik. TP,TN,FP,FN gibi kısaltmaların ne anlama geldiği bu yazıda açıklanmıştı. Sıkma tablomuz:
| y_pred | y_test | Sonuç |
| 1 | 1 | TP |
| 1 | 0 | FN |
| 1 | 1 | TP |
| 0 | 1 | FP |
| 0 | 0 | TN |
| 1 | 0 | FN |
| 0 | 1 | FP |
| 1 | 0 | FN |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 1 | 1 | TP |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 1 | 1 | TP |
| 1 | 1 | TP |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 1 | 0 | FN |
| 1 | 1 | TP |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 0 | 0 | TN |
| 1 | 0 | FN |
| 1 | 0 | FN |
| 0 | 1 | FP |
Hata matrisi oluşturmak için Python kodlarımız:
# Gerekli kütüphane
from sklearn import metrics
# Sıkma listemizi oluşturalım
y_pred2 = [1,1,1,0,0,1,0,1,0,0,0,1,0,0,1,1,0,0,1,1,0,0,0,0,1,1,0]
y_test2 = [1,0,1,1,0,0,1,0,0,0,0,1,0,0,1,1,0,0,0,1,0,0,0,0,0,0,1]
# Python listemizi pandas series yapalım
y_pred2 = pd.Series.from_array(y_pred2)
# Python listemizi pandas series yapalım
y_test2 = pd.Series.from_array(y_test2)
# Hata matrisini oluşturalım
metrics.confusion_matrix(y_test2, y_pred2)
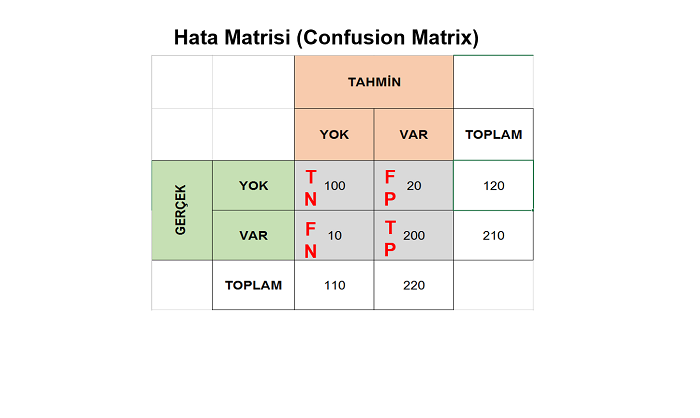
array([[12, 6],
[ 3, 6]])Elde ettiğimiz hata matrisini daha iyi anlamak için aşağıda şekil üzerinde görelim:

Hata Matrisinden Elde Edilen Bazı Metrikler
Doğruluk (Classification Accuracy)
Doğruluk = TN + TP / TOPLAM idi. Şimdi Python ile bunu yapalım:
dogruluk = metrics.accuracy_score(y_test2, y_pred2) dogruluk 0.66666666666666663
Hata Oranı (Error Rate / Misclassification Rate)
Hata Oranı = FN + FP / TOPLAM veya 1 - dogruluk
1 - metrics.accuracy_score(y_test2, y_pred2) 0.33333333333333337
Precision
Precision = TP/(FP+TP) idi. Yani pozitif tahminlerin toplam pozitiflere oranı.
metrics.precision_score(y_test2, y_pred2) 0.5
Bunlar gibi başka metrikler de var. Hata matrisi bize sınıflandırma modelini değerlendirmede daha genel bir çerçeve verir. Genelde accuracy kullanılır. Ancak ihtiyaca göre hangi metriğin daha önemli olduğu değişebilir. Örneğin istenmeyen e-posta filtrelemede doğru postalardan ziyade istenmeyen e-postaların ayıklanması istenir. Bu sebeple TP yerine FN önem kazanır. Yani doğruya doğru demenin anlamı yoktur. Önemli olan yanlışa yanlış demek yani FN sonuçlarını yüksek oranda doğru sınıflandırmakla olur. Yani yanlışa yanlış deme başarısı daha önemlidir.