
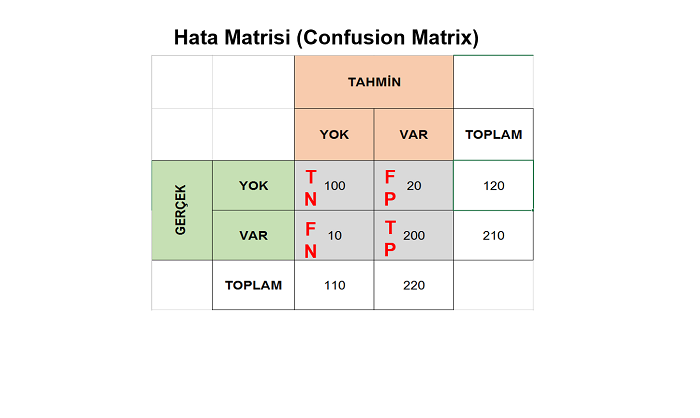
Makine öğrenmesinde kullanılan sınıflandırma modellerinin performansını değerlendirmek için hedef niteliğe ait tahminlerin ve gerçek değerlerin karşılaştırıldığı hata matrisi sıklıkla kullanılmaktadır. Her ne olursa olsun sınıflandırma tahminleri şu dört değerlendirmeden birine sahip olacaktır:
- Doğruya doğru demek (True Positive – TP) DOĞRU
- Yanlışa yanlış demek (True Negative – TN) DOĞRU
- Doğruya yanlış demek (False Positive – FP) YANLIŞ
- Yanlışa doğru demek(False Negative – FN) YANLIŞ

Benzer şekilde hipotez testlerinde de kullanılan Tip I (FP) ve Tip II (FN) hatalar bizim FP ve FN’ye benzer.
Aslına bakarsanız iki tane sonuç var. Ya sınıfı doğru tahmin edecek ya yanlış tahmin edecek. Bu matrise dayanarak üretilen bazı kriterleri aşağıda görelim ve yukarıdaki örnek matrise dayanarak çözelim. Problemimiz de şöyle olsun: bazı nitelikleri kullanarak bir hastada X rahatsızlığı var veya yok diyelim. Eğer hasta olmayanlara hasta değil demişsek TN (gerçekte var olmayan bir şeye biz de yok demişsek), hasta olmayana hasta demişsek FP (gerçekte olmayan bir şeye biz var demişsek), hasta olana hasta değil demişsek FN (gerçekte var olan bir şeye biz yok demişsek), hasta olana hasta demişsek TP (gerçekte var olan bir şeye biz de var demişsek).
Doğruluk (Accuracy): Doğru sınıflandırmanın toplama bölümüdür. Yani; doğrular / toplam. Yani yoka yok vara var dediklerimizin toplama oranı. Ayrıca esas köşegenin toplama oranı da diyebiliriz.
Doğruluk = TN + TP / TOPLAM = 100+200 / 330 = 0,91
Hata Oranı (Error Rate / Misclassification Rate): Yanlışların toplama oranıdır. Bu aynı zamanda 1’den doğruluk oranını çıkararak da elde edilir. Ayrıca yedek köşegenin toplama oranıdır da diyebiliriz.
Hata Oranı = FN + FP / TOPLAM = 10 + 20 / 330 = 0,09 Hata Oranı = 1 - Doğruluk = 1 - 0,91 = 0,09
Doğru Pozitif Oranı/Duyarlılık/Hassasiyet (True Positive Rate – Sensivity): Doğru olarak tahmin edilen varların (TP) gerçek varlara oranı. Modelin doğruları bilme konusundaki etkinliği de denilebilir.
Duyarlılık = TP / Gerçek Varlar = 200 / (200+10) = 0,95
Yanlış Pozitif Oranı (False Positive Rate): Yok’a var deme oranı. Gerçekte yok olan ancak var diye tahmin edilen hastaların gerçekten hasta olmayanlara oranı. FP / Gerçek Yok Toplamı.
Yanlış Pozitif Oranı = FP / Gerçek Yoklar = 20 / (100+20) = 0,17
Yukarıdaki iki metrik (True Positive Rate ve False Positive Rate) Receiver Operating Characteristic (ROC) grafiği çizimi ve Area Under Curve (AUC) hesaplamada kullanılır.
Seçicilik/Özgüllük (True Negative Rate – Specifity): Yok’u tahmin etme etkinliği. Yok’a ne derece yok diyebilmiş yani. TN/ Gerçek Yok toplamı.
Seçicilik = TN / Gerçek Yoklar = 100 / (100+20) = 0,83
Precision: Doğru var olarak tahmin edilenlerin, toplam var tahminlere oranı. TP / (FP+TP)
Precision = TP/(FP+TP) = 200/220 = 0.91
Prevalence: Gerçekten varların toplama oranı. (FN+TP)/Toplam
Prevalence = (FN+TP) / Toplam = (10+200) / 330 = 0.64
Öncelikle yazınız için teşekkürler,
Ancak bir tanımınız dikkatimi çekti. “Doğruya yanlış demek (True Negative – TN) YANLIŞ” olarak tanımlamışsınız.
Bununla birlikte bir alt paragraf da ise
“Problemimiz de şöyle olsun: bazı nitelikleri kullanarak bir hastada X rahatsızlığı var veya yok diyelim. Eğer hasta olmayanlara hasta değil demişsek TN”
Bu durumda ilk tanımızdaki TN YANLIŞ değil DOĞRU olması gerekmez mi?
Merhaba. yorumunuz için teşekkürler. İlk gruplandırma örnekten bağımsız hata matrislerine özgü bir tasniftir. En yaygın kullanılan metrik olan accuracy hesaplanırken doğru bilinenlerin toplama oranı hesaplanır. Bu sebeple ilk gruplamada vara var ve yoka yok demenin doğru olduğunu söyledim ki zaten accuray hesapllarken biz de böyle yapmak durumundayız. Hastalıkla ilgili paragrafa ilave açıklamalar ekledim. Sanırım buradaki karışıklık birazcık hastalığın var olması ve olmamasından kaynaklanıyor. Hastalık tabiatı itibariyle olumsuzluğu çağrıştırıyor. belki daha farklı bir örnek kullanmalıydım. Özetle gerçekte var olana var demek gerçekte olmayana ise yok demek doğrudur ve bu doğrular matriste ana köşegeni oluştururlar. Kolay gelsin…
Erkan Bey Merhaba,
Emeğiniz için teşekkürler. Ancak TN değeri sizinde “hasta olmayanlara hasta değil demişsek TN” belirttiğiniz gibi zaten False olan değeri olumsuz tahminlemek anlamında değil mi? Dolayısıyla TN yanlışa yanlış demek olarak belirtilmesi ve dolayısıyla TRUE olması gerekmiyor mu ?
iyi çalışmalar dilerim.
İkazınız için teşekkürler. Haklısınız dikkatimizden kaçmış. Confusion matrix tam bir confusion 🙂