

![]()
1. Giriş
Merhabalar. Uygulama geliştirirken geliştirme(dev), test ve canlı (prod) gibi farklı farklı ortamlar kullanırız. Farklı ortamlarda çalışırken bazı ayarlamalar yapmamız gerekir. Şayet hızlı bir şekilde uygulamayı çıkarayım, geliştirme, canlı vb. uğraşmayayım diyorsanız bu yazı size göre. Bu yazıda Windows bilgisayarımızı driver olarak kullanarak IntelliJ IDEA ile canlı Hadoop Cluster üzerinde kodlarımızı geliştirme esnasında çalıştıracağız. Başka bir deyişle kod geliştirme aracı (Intellij) kendi lokal bilgisayarımızda iken çalıştır dediğimizde kodlar uzak Hadoop cluster üzerinde çalışacak ve driver olarak biz sonuçları görebileceğiz. Bunu aşağıdaki şekilde daha iyi görebiliriz.
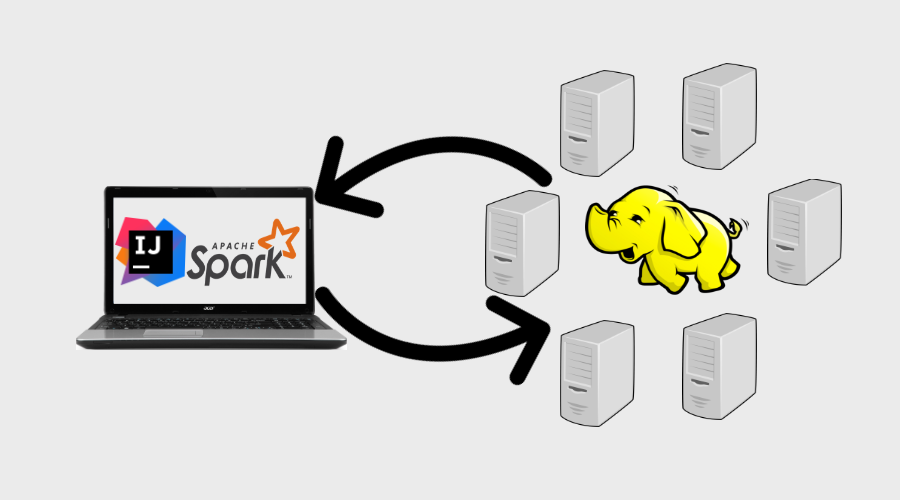
2. Kullanılan Araçlar ve Varsayımlar
2.1. Kullanılan Araçlar
Bu çalışmada; Windows 10 Bilgisayar, gitbash, IntelliJ IDEA, Scala 2.11.8, java 8 (windows), Cloudera Manager 6.2.X ile yönetilen 5 sunuculu Hadoop Cluster, hem Hadoop cluster hem windows bilgisayarda Spark 2.4.0 sürümü kullanılmıştır.
Hadoop cluster 5 sunucudan oluşmaktadır. 1 ve 2 master; 3,4,5 ise slave sunuculardır. Hadoop Cluster sunucu isimleri:
- cdh1.impektra.com
- cdh2.impektra.com
- cdh3.impektra.com
- cdh4.impektra.com
- cdh5.impektra.com
2.2. Varsayımlar
Windows 10 bilgisayarınızda Spark 2.4.0 kurulu ve çalışır durumdadır.
3. Ön Ayarlar
3.1. Windows kullanıcısı için HDFS’te home dizin oluşturma
Kendi Windows bilgisayarımızdan çalıştırdığımız kod uzak Hadoop Cluster’a kendi kullanıcı adımızla gider. HDFS tarafında bu kullanıcıya ait home diznin olması gerekir. HDFS dünyasında home dizin /user dizni altındadır. Öyleyse önce edge sunucumuza (cdh1) bağlanalım ve home dizni oluşturalım /user/<windows kullanıcı adınız>. Kullanıcı adınızı bilmiyorsanız aşağıdaki şekilden öğrenebilirsiniz. Benimki user.
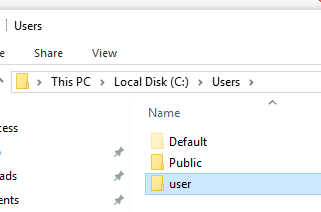
Önce cdh1 sunucusuna gitbash ile bağlanalım.
ssh root@cdh1
Bağlandığınızda:
[root@cdh1 ~]#
promt yukarıdaki şekilde hazır bizi bekliyor olacaktır. Önce linux tarafında user kullanıcısı ve home diznini oluşturalım:
[root@cdh1 /]# useradd -m user
Yukarıdaki komut hem kullanıcıyı hem de kullanıcı home diznini (/home/user) oluşturdu.
Şimdi az önce oluşturduğumuz user kullanıcısının hdfs üzerinde home diznini yaratalım. Bunu yaparken hdfs kullanıcısının adını kullanacağız. Neden diye sorarsanız hdfs kullanıcısı HDFS dünyasının süper kullanıcısıdır.
[root@cdh1 ~]# sudo -u hdfs hdfs dfs -mkdir /user/user
Kontrol edelim
[root@cdh1 ~]# hdfs dfs -ls /user Found 9 items drwxr-xr-x - admin admin 0 2019-07-14 10:32 /user/admin drwx------ - hdfs supergroup 0 2019-07-14 09:18 /user/hdfs drwxrwxrwx - mapred hadoop 0 2019-07-14 05:58 /user/history drwxrwxr-t - hive hive 0 2019-07-14 05:58 /user/hive drwxrwxr-x - hue hue 0 2019-07-14 06:03 /user/hue drwxrwxr-x - oozie oozie 0 2019-07-14 05:57 /user/oozie drwxr-x--x - spark spark 0 2019-07-14 05:57 /user/spark drwxr-xr-x - hdfs supergroup 0 2019-09-29 11:28 /user/user drwxr-xr-x - hdfs supergroup 0 2019-07-14 05:57 /user/yarn
user kullanıcısı için hdfs dünyasında home dizin oluşturuldu. Ancak dizin sahipliği hala hdfs, bunu user yapmalıyız ki user kullanıcısı buraya erişirken hata almasın.
[root@cdh1 ~]# sudo -u hdfs hdfs dfs -chown user:hdfs /user/user
3.2. Spark jar dosyalarını HDFS’e taşıma
Madem Spark’ı uzak Hadoop Cluster üzerinden çalıştıracağız. Uygulamamızın ihtiyaç duyacağı jar dosyalarını HDFS’e taşımalıyız. Bunun için önce HDFS’te bir klasör oluşturacağız ardından da jar dosyalarını Windows üzerinde kurulu olan spark içinden kopyalayacağız.
Ben HDFS /tmp/spark_jars yaratacağım. Bunun için Windows bilgisayarımdaki jar dosyalarını önce edge sunucu olarak kullandığım cdh1 sunucusuna ardında da hdfs’e taşımayı planlıyorum.
[root@cdh1 /]# sudo -u user hdfs dfs -mkdir /tmp/spark_jars
Kontrol edelim
[root@cdh1 /]# hdfs dfs -ls /tmp Found 4 items d--------- - hdfs supergroup 0 2019-07-14 11:06 /tmp/.cloudera_health_monitoring_canary_files drwx-wx-wx - hive supergroup 0 2019-07-14 08:41 /tmp/hive drwxrwxrwt - mapred hadoop 0 2019-07-14 08:52 /tmp/logs drwxr-xr-x - user supergroup 0 2019-09-29 13:48 /tmp/spark_jars
Tamadır. Şimdi jar dosyalarını taşıyalım. Önce cdh1 sunucusu üzerinde bu dosyaları hdfs’e aktarmadan önce geçici olarak tutacağım dizin yaratalım. user kullanıcısına geçip onun home diznini kullanalım.
[root@cdh1 /]# su - user [user@cdh1 ~]$ mkdir spark_jars_lokal
Şimdi Windows bilgisayardan cdh1 sunucu lokal diznine (/home/user/spark_jars_lokal)aktarma yapalım. Benim spark home diznim: C:\spark. Gitbash üzerinde cd ile bu dizine geçelim ve cdh1 sunucusuna bu jar dosyalarını kopyalayalım. Bunun için ikinci bir gitbash terminali açıyoruz.
cd /c/spark scp jars/* root@cdh1:/home/user/spark_jars_lokal
Evet kopyalama başladı. Aşağıdaki şekilde kopyalanan dosyaları göreceksiniz:

cdh1 sunucusu üzerinden kontrol edelim.
[root@cdh1 /]# ls -l /home/user/spark_jars_local/
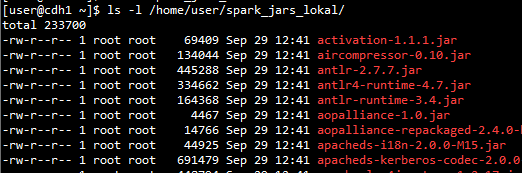
Gördüğümüz gibi dosya sahipliği root kullanıcısında bunu user yapalım ve dosya modunu çalıştırılabilir yapalım. Bunun için exit ile user kullanıcısından tekrar root kullanıcısına geçiş yapacağız.
[user@cdh1 ~]$ exit logout You have new mail in /var/spool/mail/root [root@cdh1 /]# [root@cdh1 /]# chown user:user /home/user/spark_jars_lokal/* [root@cdh1 /]# chmod 755 /home/user/spark_jars_lokal/*
Artık jar dosyaları user kullanıcısının kontrolünde. Şimdi bunları HDFS üzerindeki /tmp/spark_jars’a taşıyalım ve kontrol edelim.
[root@cdh1 /]# sudo -u user hdfs dfs -put /home/user/spark_jars_lokal/* /tmp/spark_jars [root@cdh1 /]# hdfs dfs -ls /tmp/spark_jars Found 227 items -rw-r--r-- 3 user supergroup 16993 2019-09-29 13:51 /tmp/spark_jars/JavaEWAH-0.3.2.jar -rw-r--r-- 3 user supergroup 325335 2019-09-29 13:51 /tmp/spark_jars/RoaringBitmap-0.7.45.jar -rw-r--r-- 3 user supergroup 236660 2019-09-29 13:51 /tmp/spark_jars/ST4-4.0.4.jar -rw-r--r-- 3 user supergroup 69409 2019-09-29 13:51 /tmp/spark_jars/activation-1.1.1.jar -rw-r--r-- 3 user supergroup 134044 2019-09-29 13:51 /tmp/spark_jars/aircompressor-0.10.jar
Dosyaların burada da modunu 755 yapalım ve kontrol edelim.
[root@cdh1 /]# sudo -u user hdfs dfs -chmod 755 /tmp/spark_jars/* [root@cdh1 /]# sudo -u user hdfs dfs -ls /tmp/spark_jars/ Found 227 items -rwxr-xr-x 3 user supergroup 16993 2019-09-29 13:51 /tmp/spark_jars/JavaEWAH-0.3.2.jar -rwxr-xr-x 3 user supergroup 325335 2019-09-29 13:51 /tmp/spark_jars/RoaringBitmap-0.7.45.jar -rwxr-xr-x 3 user supergroup 236660 2019-09-29 13:51 /tmp/spark_jars/ST4-4.0.4.jar -rwxr-xr-x 3 user supergroup 69409 2019-09-29 13:51 /tmp/spark_jars/activation-1.1.1.jar -rwxr-xr-x 3 user supergroup 134044 2019-09-29 13:51 /tmp/spark_jars/aircompressor-0.10.jar -rwxr-xr-x 3 user supergroup 445288 2019-09-29 13:51 /tmp/spark_jars/antlr-2.7.7.jar
3.3. Windows Ana Makinenin Adını ve IP numarasını Cluster hosts dosyalarında tanımlama
Spark driver Windpws 10 makine olduğu için bu makinenin ip ve ismini cluster linux makineleri /etc/hosts dosyalarına eklememiz gerekir. Önce ana makinenin adını ve ip numarasını öğrenelim. Windows cmd açılır (Windows tuşu + cmd), ipconfig komutu çalıştırılır.
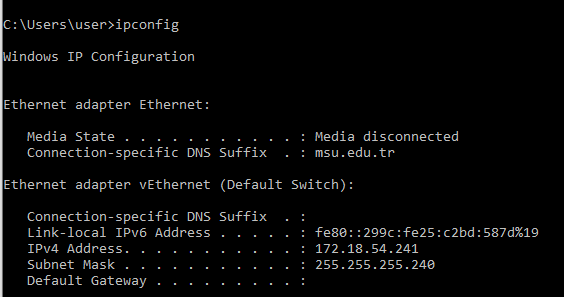
Peki makinenin adı? Bunu en iyi Spark uygulamasını çalıştırdığımızda öğrenebiliriz. Diğer yöntemler maalesef kısa adını veriyor. Uygulama çalışırken INFO loglarında SparkUI adresini yazar.
INFO SparkUI: Stopped Spark web UI at http://DESKTOP-RL2HHBV.mshome.net:4040
Buradaki DESKTOP-RL2HHBV.mshome.net bizim Windows ana makinenin adıdır.
Şimdi ip ve makine adını öğrendik. Bunu Hadoop cluster linux makinelerin /etc/hosts dosyasına ekleyelim
[root@cdh1 ~]# nano /etc/hosts
komutu ile host dosyasını nano editörü ile açarız.
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.206.101 cdh1.impektra.com cdh1 192.168.206.102 cdh2.impektra.com cdh2 192.168.206.103 cdh3.impektra.com cdh3 192.168.206.104 cdh4.impektra.com cdh4 192.168.206.105 cdh5.impektra.com cdh5 172.18.54.241 DESKTOP-RL2HHBV.mshome.net
Son satırda olanı ekleriz (Sizin ip ve makine isminiz farklılık gösterebilir).
Bu işlemi cluster içindeki diğer makinelere de yapmalıyız. Bunu elle veya pssh gibi pratik yöntemlerle yapabilirsiniz.
Evet bu yazımızda Spark uygulamamızın ihtiyacı olabilecek jar dosyalarını HDFS’e taşıdık ve windows kullanıcımızın HDFS diznini oluşturduk. Serimize bir sonraki yazımızla devam ediyoruz.