


Eğer büyük veri (big data) dünyasının içindeysek, Apache Spark'ın adını...

MCP (Model Context Protocol), yapay zeka asistanlarının dış araçlar ve...

Son iki yılda yapay zeka dünyasında en çok konuşulan konulardan...

Diş kliniğinin resepsiyonunda çalıştığınızı hayal edin. Telefon çalıyor, hasta randevu...






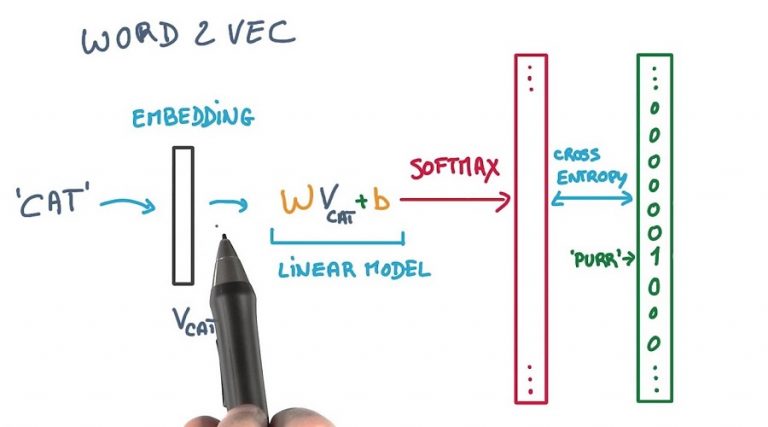
Aralık ayı blog yazımın konusu olan, word2vec’ten yani kelime temsil (word embedding) yöntemini teoride açıkladıktan sonra Pyhton programlama...

Merhaba Arkadaşlar,Özellik seçimi ile ilgili yazı serisinin 2.yazısını okumaktasınız, eğer ilk yazıyı okumadıysanız ilk yazıyı okumanız konu bütünlüğünü...